
vSkill
软链接
创建软链接
ln -s /mnt/nas/datasets/kitti ~/kitti
查看软链接
find ~/ky -type l -ls
ls -la ~/ky/datasets
ls -lb 查看软链接
unlink xxxx
rysnc
REMOTE_USER="cht"
REMOTE_HOST="218"
REMOTE_BASE="~/ky"
RSYNC_OPTS="-avz --delete --progress"
rsync $RSYNC_OPTS -e ssh /home/linux/ky/GSFusion/ \
"${REMOTE_USER}@${REMOTE_HOST}:${REMOTE_BASE}/GSFusion/"
rsync $RSYNC_OPTS -e ssh /home/linux/ky/ORB_SLAM3/ \
"${REMOTE_USER}@${REMOTE_HOST}:${REMOTE_BASE}/ORB_SLAM3/"
rsync $RSYNC_OPTS -e ssh /home/linux/ky/Fast-FoundationStereo/ \
"${REMOTE_USER}@${REMOTE_HOST}:${REMOTE_BASE}/Fast-FoundationStereo/"
————————————————————————————————————
普通rsync(incremental)
rsync -avz /path/file.txt cht@218:/home/user/data/
rsync -avz /path/dir/ cht@218:/home/user/data/
rsync -avz --delete --progress cht@218:/home/remote_dir/ /local/path/
(data后面要+斜杠!!)
rsync -avz cht@218:/home/remote_file.txt /local/path/
某些文件不传
rsync -avz --progress \
--exclude 'gsfusion_out/' \
--exclude 'gsfusion.yaml' \
--exclude 'gsfusion_orb_run.yaml' \
--exclude 'pose_orb_gsfusion.txt' \
cht@218:/home/cht/ky/datasets/zed_runj/ ./zed_runj/
压缩文件夹
zip -r mydata.zip ./myfolder
curl
curl -L -o depth_anything_v2_vitl.pth "https://huggingface.co/depth-anything/Depth-Anything-V2-Large/resolve/cbbb86a30ce19b5684b7a05155dc7e6cbc7685b9/depth_anything_v2_vitl.pth"
(-L:跟随跳转(Hugging Face 常会 302 到实际存储地址,不加容易下到 HTML 或失败)。
-o 文件名:保存成指定文件名;当前目录会生成 depth_anything_v2_vitl.pth。
--progress-bar 显示进度条)
下载文件
终端不自动配代理,需要自己设置
wget -e "https_proxy=[http://127.0.0.1](http://127.0.0.1):10808" -c [https://www.simulation.openfields.fr/phocadownload/CloudCompare_20260128_151607.dmg]
git clone
export http_proxy=http://127.0.0.1:10808
export https_proxy=http://127.0.0.1:10808
git clone ....
避免占用满盘的 /tmp 和家目录缓存:
mkdir -p /data/cht/tmp /data/cht/pip-cache
export TMPDIR=/data/cht/tmp
export PIP_CACHE_DIR=/data/cht/pip-cache
diff
diff -qr /home/cht/ky /data/cht/ky
find
进程状态查询
ps -p 40292,111682,97264 -o pid,stat,cmd
ps -o ppid= -p 40292 看父进程
cuda
Introduction
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由 NVIDIA 推出的一个并行计算平台和编程模型。它允许软件开发者利用 NVIDIA GPU(图形处理器)进行通用计算(GPGPU),从而显著加快计算密集型应用的运行速度。
在 CUDA 出现之前,GPU 主要用于图形渲染。CUDA 的诞生让开发者可以使用类 C/C++ 语言来编写在 GPU 上运行的代码,处理科学计算、人工智能、视频处理等任务
CUDA 的核心架构概念
CUDA 的设计核心是将计算任务拆分为成千上万个小的、可并行执行的任务。
异构计算 (Heterogeneous Computing)
CUDA 编程涉及两个主要角色:
Host(主机): 指 CPU 及其内存。负责控制逻辑、内存分配和数据准备。
Device(设备): 指 GPU 及其显存。负责大规模的并行计算。
编程模型:核函数 (Kernel)
Kernel 是 CUDA 编程的核心。它是在 GPU 上并行执行的函数。当你调用一个 Kernel 时,它不是只运行一次,而是由大量的 线程 (Threads) 同时运行。
CUDA 的层级结构 (Hierarchy)
为了管理数以万计的线程,CUDA 采用了三层逻辑结构:
Thread (线程): 最小的执行单位。
Thread Block (线程块): 一组线程的集合。同一个 Block 内的线程可以进行协作,通过共享内存交换数据。
Grid (网格): 所有的 Thread Block 组成了 Grid。一个 Grid 对应一次 Kernel 的启动。
硬件映射
SP (Streaming Processor): 也称 CUDA Core,是执行单个线程的硬件单元。
SM (Streaming Multiprocessor): 一个 SM 包含多个 SP。一个 Thread Block 会被调度到一个 SM 上执行。
CUDA 的工作流程
编写一个典型的 CUDA 程序通常遵循以下四个步骤:
分配显存: 在 GPU (Device) 上使用
cudaMalloc分配空间。拷贝数据: 将数据从 CPU (Host) 内存拷贝到 GPU 显存 (
cudaMemcpy)。启动 Kernel: 配置 Grid 和 Block 的维度,在 GPU 上并行执行计算任务。
写回结果: 将计算结果从 GPU 拷贝回 CPU 内存,并释放显存。
CUDA 与 CUDA Toolkit
PyTorch 自带的 CUDA (Runtime) —— “家具搬运工”
当你通过 conda install pytorch torchvision pytorch-cuda=12.1 安装时,你得到的是 CUDA Runtime(运行库)。
它的作用: 仅仅是为了让已经写好的程序(预编译好的模型)(
.so或.pyd文件)能在显卡上跑起来。
完整的 CUDA Toolkit —— “家具制造工具箱”
这是 NVIDIA 官方提供的完整开发包。
核心组件:
nvcc(CUDA 编译器)。它的作用: 当你需要把 C++/CUDA 源代码(比如你刚才安装的
diff-gaussian-rasterization)编译成电脑能识别的二进制文件时,必须用到它。
pytorch
PyTorch 的核心支柱
张量 (Tensors)
Tensor 是 PyTorch 中最基础的数据结构。它在数学上是一个多维数组,与 NumPy 的 ndarray 非常相似,但有一个致命的优势:Tensor 可以直接在 GPU 上运行,从而利用 CUDA 加速。
自动求导 (Autograd)
在神经网络中,计算梯度(反向传播)是最复杂的数学部分。PyTorch 的 torch.autograd 模块能够自动记录你在 Tensor 上执行的所有操作,并在你需要时自动计算导数。
你只需定义正向传播(Forward Pass)。
loss.backward()会自动完成复杂的链式法则计算。
动态计算图 (Dynamic Computational Graph)
这是 PyTorch 区别于早期 TensorFlow 的最大特征。
静态图: 必须先定义完整的网络结构,然后才能喂入数据(像建房子,图纸画好才能动工)。
动态图 (Define-by-Run): 图是在代码运行时实时构建的。这意味着你可以使用 Python 的
if分写、for循环来改变网络结构,调试起来就像调试普通 Python 程序一样简单。
核心模块
PyTorch 的标准工作流
准备数据: 将原始数据转换为 PyTorch Tensors。
构建模型: 继承
nn.Module类,在__init__中定义层,在forward中定义数据流向。定义损失与优化器: 选择衡量错误的标准(如交叉熵)和更新权重的方法。
循环训练:
清零梯度:
optimizer.zero_grad()。前向传播: 得到预测值。
计算损失: 比较预测值与真实值的差异。
反向传播:
loss.backward()计算每个参数的梯度。更新参数:
optimizer.step()。
PyTorch 与 CUDA
PyTorch 通过简单的指令就能将计算迁移到显卡上:
检测设备:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")搬运模型:
model.to(device)搬运数据:
data.to(device)
pip install -e 命令全流程(/data/cht/ky/gaus-slam/third_party/diff-gaussian-rasterization-w-depth为例)
解析与入口:pip 怎么决定“怎么装”
解析参数:确认是 本地路径、editable。
读项目元数据:
若有
pyproject.toml:按 PEP 517/518,用里面声明的 build-system(通常是setuptools.build_meta)当构建后端。若只有
setup.py:新版本 pip 仍可能生成/假定最小pyproject.toml或走 legacy,但 editable 在 pip 21+ 常走prepare_metadata_for_build_editable/build_editable这一套。
结论:对你这种带 CUDA 扩展 的包,pip 一定要跑一段“构建逻辑”(至少生成元数据,再编译扩展),不会只拷贝几个
.py就结束。
2. 默认(无 --no-build-isolation):隔离构建环境
创建临时目录,例如
/tmp/pip-build-env-xxxxx。Installing build dependencies:在该临时环境里安装pyproject.toml里[build-system] requires = ...列出的包(如setuptools、wheel,通常没有torch)。启动子进程(你日志里的
pip/_vendor/pyproject_hooks/_in_process/_in_process.py):这个子进程的
sys.path以临时环境为主,看不到你在gaus里装的 torch。
调用构建后端,例如:
get_requires_for_build_editable或prepare_metadata_for_build_wheel/prepare_metadata_for_build_editable
这一步会 执行 setup.py(或 setuptools 从 setup.py 读配置)。你的 setup.py 前几行是:
setup.pyLines 12-13
from setuptools import setup
from torch.utils.cpp_extension import CUDAExtension, BuildExtension因此 一进 setup.py 就要 import torch。隔离环境里 没有 torch → ModuleNotFoundError: No module named 'torch'(你第一次报错)。
此时还没执行 nvcc、也没去 GitHub——失败点就在 解释器 import。
3. 加上 --no-build-isolation 之后
不再用
/tmp/pip-build-env-...里那套隔离 Python 来跑构建钩子(或显著减少隔离)。构建子进程用的
sys.path包含当前已激活环境(如gaus)→import torch成功。继续
prepare_metadata_for_build_editable:仍会执行/分析setup.py,此时会进一步import torch.utils.cpp_extension。torch/utils/cpp_extension.py里有from pkg_resources import packaging(PyTorch 1.12)。若pkg_resources不可用(setuptools 82 等)→No module named 'pkg_resources'(你第二次报错)。
当我们遇到 import pkg_resources 失败时,我们是怎么知道 这个包来自于 setuptools 的,应该如何查阅信息?
当你遇到 ModuleNotFoundError: No module named 'xxx',但运行 pip install xxx 又提示找不到包时,可以采用以下几种方案
访问 pypi.org。
没法直接查到,因为它不是独立的项目:
pkg_resources就像是笔记本电脑自带的“触控板驱动”,它不是独立卖的,而是作为setuptools这个大礼包的一部分打包赠送的。截图里的第 5 个和第 6 个搜索结果透露了其原产地setuptools
如果在一个运行正常的环境中想验证来源,可以这样做:
import pkg_resources print(pkg_resources.__file__)
conda install setuptools 显示已安装,但 import pkg_resources 仍失败,为何能判定是 setuptools 版本过新 导致的
setuptools 新版本不再提供/不再暴露顶层 pkg_resources。
pip install --force-reinstall "setuptools==69.5.1" wheel解释此命令
仍然没有编译 CUDA——还是 纯 Python 导入链 阶段。
4. 元数据准备好之后:build_editable / 编译扩展
元数据阶段通过后,pip 会进入 真正构建(你日志里的 Building editable for diff_gaussian_rasterization):
setup.py里定义的ext_modules:你的项目是CUDAExtension(..., sources=[... .cu, ext.cpp])。cmdclass={'build_ext': BuildExtension}:由 PyTorch 的BuildExtension接管,内部会调nvcc/g++,按TORCH_CUDA_ARCH_LIST、可见 GPU、CUDA_HOME等生成diff_gaussian_rasterization._C这个扩展模块。只有走到这里,才涉及 CUDA 编译、驱动、
libcuda。你后来在_get_cuda_arch_flags或cuInit上的问题,都属于 这一阶段或运行阶段,和前面的torch/pkg_resourcesimport 是不同阶段。editable 的结果:在
site-packages里写入 指向源码目录的链接方式(.pth+ dist-info / 现代 editable 布局),使import diff_gaussian_rasterization使用/data/cht/ky/.../diff_gaussian_rasterization下的包 + 已编译的_C。
报错 IndexError: list index out of range
torch/utils/cpp_extension.py试图获取当前显卡的架构信息(例如sm_86或sm_80),以便告诉编译器该按什么标准编译 CUDA 代码。但是,因为以下原因,PyTorch 没能拿到任何架构信息,导致
arch_list变成了空的[]。当它尝试执行arch_list[-1] += '+PTX'(访问最后一个元素)时,就报了“索引超出范围”的错误。为什么系统检测不到 CUDA?
驱动是否正常: 输入 nvidia-smi。如果报错,说明宿主机显卡驱动有问题。
NVCC 是否安装: 输入 nvcc -V。如果你正在编译 CUDA 插件,必须安装完整的 CUDA Toolkit,而不仅仅是 PyTorch 自带的运行时。
权限问题: 如果你在 Docker 容器或特定的服务器环境下,请确保启动命令中包含了
--gpus all。python -c "import torch; print(torch.cuda.device_count(), torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'no cuda')" 确认 PyTorch 能不能通过驱动调动显卡进行计算。
在 执行上面这个python命令时,未发现显卡,警告 UserWarning: CUDA driver initialization failed, you might not have a CUDA gpu.
这通常意味着 PyTorch 找到了显卡,但打不开驱动的接口。可能是因为Conda 环境里混入了不兼容的 libcuda.so。
复习:动态链接库
在 Linux 中,它们通常以 .so(Shared Object)结尾;在 Windows 中,则是 .dll。
核心逻辑: 以前写程序,所有需要的代码都要塞进同一个文件里(这叫静态链接),导致程序又大又笨。 现在,程序员把常用的功能(比如如何绘图、如何计算数学公式、如何调用显卡)拆出来,做成独立的文件。
“共享”特性:一个
libcuda.so文件可以同时被 PyTorch、TensorFlow 和你的自定义代码使用。内存里只需要存一份,省空间。“动态”特性:程序运行的时候才去“借”这些代码,而不是在编译时就死死地绑在一起。
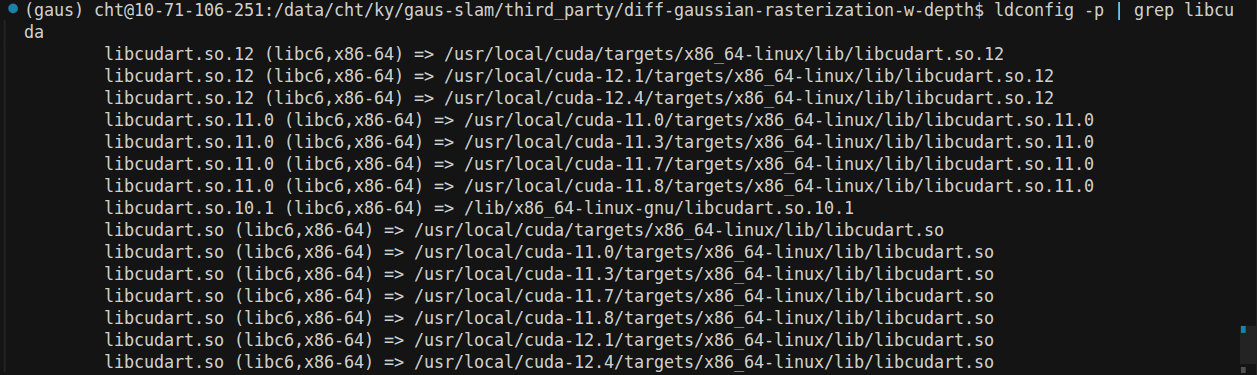
ldconfig -p | grep libcuda
ldconfig
Configure dynamic linker run-time bindings。
它是一个系统管理工具,用于配置动态链接器的运行绑定。它会扫描
/lib、/usr/lib等目录,并维护一个名为/etc/ld.so.cache的缓存文件,让系统能快速找到共享库(.so文件)。
-p (print)
作用:这个选项告诉
ldconfig打印(列出)当前缓存中所有已知的共享库名称及其对应的文件路径。
调用 CUDA Driver API 进行debug
(gaus) cht@10-71-106-251:/data/cht/ky/gaus-slam/third_party/diff-gaussian-rasterization-w-depth$ python << 'EOF'
> import ctypes
> lib = ctypes.CDLL("libcuda.so.1")
> cuInit = lib.cuInit
> cuInit.argtypes = [ctypes.c_uint]
> cuInit.restype = ctypes.c_int
> err = cuInit(0)
> print("cuInit returned:", err, "(0 = CUDA_SUCCESS)")
> if err != 0:
> # 可选:再打印 device count API
> pass
> EOF
cuInit returned: 3 (0 = CUDA_SUCCESS) python << 'EOF' ... EOF: 作用:它允许你在命令行里直接写多行 Python 代码,然后一次性喂给
python解释器执行,而不需要先创建一个.py文件。'EOF':这是一个标识符,告诉系统:“从这里开始是代码,直到再次看到 EOF 为止”。

3:代表CUDA_ERROR_NOT_INITIALIZED虽然系统里有libcuda.so文件(索引正常),但驱动程序无法与硬件(显卡)正常通信。
检查版本是否一致
(ffs) cht@10-71-106-251:/data/cht/ky/Fast-FoundationStereo$ dpkg -S /lib/x86_64-linux-gnu/libcuda.so.1 2>/dev/null || rpm -qf /lib/x86_64-linux-gnu/libcuda.so.1 2>/dev/null
Please ask your administrator.
(ffs) cht@10-71-106-251:/data/cht/ky/Fast-FoundationStereo$ ls -l /lib/x86_64-linux-gnu/libcuda.so.1
lrwxrwxrwx 1 root root 20 5月 29 2025 /lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.575.57.08
(ffs) cht@10-71-106-251:/data/cht/ky/Fast-FoundationStereo$ cat /proc/driver/nvidia/version
NVRM version: NVIDIA UNIX Open Kernel Module for x86_64 575.57.08 Release Build (dvs-builder@U22-I3-H04-01-5) Sat May 24 07:03:13 UTC 2025
GCC version: gcc version 9.4.0 (Ubuntu 9.4.0-1ubuntu1~20.04.2) 在 Linux 系统中,NVIDIA 驱动并不是一个单一的整体,而是分为两个核心部分,它们必须严格匹配才能工作
查看错误日志 dmesg | grep -i "NVRM" | tail -n 20
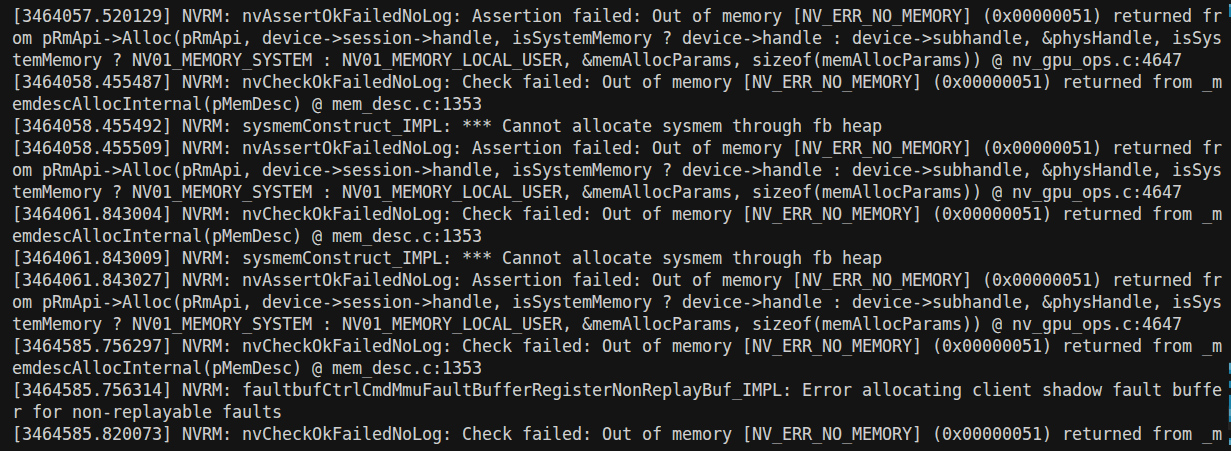
NV_ERR_NO_MEMORY(0x51)。这说明驱动程序在尝试初始化时,想要申请一部分系统内存(RAM)来作为管理缓存,但操作系统内核拒绝了这一请求
numpy : 入门到入土
核心数据结构:ndarray (多维数组)
NumPy 的灵魂是
ndarray对象。相比于 Python 自带的list,NumPy 数组的元素类型必须相同,这使得它在内存中连续存储,计算速度极快。
import numpy as np
# 从列表创建一维/二维数组
arr1 = np.array([1, 2, 3])
arr2 = np.array([[1, 2], [3, 4]])
# 常用内置创建函数
zeros_arr = np.zeros((3, 3)) # 创建 3x3 全 0 数组
ones_arr = np.ones((2, 4)) # 创建 2x4 全 1 数组
range_arr = np.arange(0, 10, 2) # 类似 range(),结果为 [0, 2, 4, 6, 8]
lin_arr = np.linspace(0, 1, 5) # 0到1之间等距生成5个数 [0., 0.25, 0.5, 0.75, 1.]数组属性查看
arr = np.array([[1, 2, 3], [4, 5, 6]])
print(arr.shape) # 输出 (2, 3) -> 表示2行3列
print(arr.ndim) # 输出 2 -> 数组维度(二维)
print(arr.size) # 输出 6 -> 元素总个数
print(arr.dtype) # 输出 int64 (或 int32) -> 数据类型索引与切片 (Indexing & Slicing) ★
arr = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
# 基础切片
print(arr[2:5]) # 输出 [2 3 4]
# 多维数组索引
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2d[1, 2]) # 输出 6 (第2行,第3列)
print(arr2d[:, 1]) # 输出 [2 5 8] (提取所有行的第2列)
# 布尔索引 (非常常用于数据过滤)
print(arr[arr > 5]) # 输出 [6 7 8 9]形状操作 (Shape Manipulation)
arr = np.arange(12) # 12个元素的1维数组
# 改变形状 (不改变数据本身)
reshaped = arr.reshape(3, 4) # 变成 3行4列 的二维数组
# 展平数组
flattened = reshaped.flatten() # 重新变回1维数组
# 数组拼接
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]])
np.concatenate((a, b.T), axis=1) # 沿列方向拼接数学运算与广播机制 (Broadcasting)
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
# 元素级运算
print(a + b) # [5 7 9]
print(a * b) # [4 10 18]
# 统计聚合
print(a.sum()) # 6
print(a.mean()) # 2.0 (平均值)
print(a.max()) # 3
# 广播机制 (Broadcasting)
# 当数组形状不同时,NumPy 会自动扩展它们以进行计算
print(a + 10) # [11 12 13] (10被"广播"到了每一个元素上)command
ffs
CUDA_VISIBLE_DEVICES=1
python scripts/zed_ffs_record_tum.py --out_dir ~/ky/datasets/zed_runb --max_frames n
python scripts/zed_stereo_record_tum.py --out_dir ~/ky/datasets/zed_runb --max_frames n
python scripts/zed_stereo_record_tum.py --svo_record --svo_preview --max_frames 3000 --out_dir ~/ky/datasets/zed_runc --target_fps 6
python scripts/run_ffs_offline.py ~/ky/datasets/zed_runc --zfar 12
ORB_ZED_ROBUST_ORB=1 bash ~/ky/Fast-FoundationStereo/scripts/run_orb_slam3_zed_tum.sh ~/ky/datasets/zed_runc
GSFUSION_POSE_MODE=orb bash ~/ky_mirror/Fast-FoundationStereo/scripts/run_gsfusion_on_tum.sh ~/ky_mirror/datasets/zed_runh
GSFUSION_ORB_START_LINE=266 GSFUSION_POSE_MODE=orb bash ~/ky/Fast-FoundationStereo/scripts/run_gsfusion_on_tum.sh ~/ky/datasets/zed_runf
————————————————————————————————————————————
guas
SKIP_FFS=1 USE_MP=1 bash ~/ky/Fast-FoundationStereo/scripts/run_gaus_slam_zed.sh ~/ky/datasets/zed_runc
CUDA_VISIBLE_DEVICES=1 && SKIP_FFS=1 bash ~/ky_mirror/Fast-FoundationStereo/scripts/run_gaus_slam_zed.sh ~/ky_mirror/datasets/zed_runh
export GAUS_LOCALMAP_FRAMES=24 && export GAUS_NUM_BA_ITER=80 && export GAUS_NUM_TRACK_ITER=80 && SKIP_FFS=1 bash ~/ky/Fast-FoundationStereo/scripts/run_gaus_slam_zed.sh ~/ky/datasets/zed_runf 2>&1 | tee ~/ky/datasets/zed_runf/gaus_slam_run.log
export CUDA_VISIBLE_DEVICES=2 && export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:64 && export GAUS_LOCALMAP_FRAMES=16 && export GAUS_NUM_BA_ITER=60 && export GAUS_NUM_TRACK_ITER=60 && export GAUS_NUM_COVIS_SUBMAPS=12 && GAUS_FRAME_STRIDE=1 SKIP_FFS=1 bash ~/ky/Fast-FoundationStereo/scripts/run_gaus_slam_zed.sh ~/ky/datasets/zed_runf 2>&1 | tee ~/ky/datasets/zed_runf/gaus_slam_run.log
cd ~/ky_mirror/gaus-slam
python scripts/convert_gaussians_ply_for_supersplat.py \
output/zed_chunked_run1/part000/save/gaussians.ply \
-o output/zed_chunked_run1/part000/save/gaussians_supersplat.ply
python scripts/chunked_gaus_zed.py --dataset ~/ky_mirror/datasets/zed_runf --out-root output/zed_chunke
d_run1 --chunk-size 400 --overlap 80
python scripts/downsample_gaussians_ply.py /home/cht/ky_mirror/gaus-slam/output/zed_chunked_run1/merged_gaussians.ply -o /home/cht/ky_mirror/gaus-slam/output/zed_chunked_run1/huge_5pct.ply --fraction 0.3 --seed 0
________________________________________________________________________________
datagen
cd ~/cht/SimpleProc && conda activate datagen && CUDA_VISIBLE_DEVICES=2 python datagen/run_local_scene_generation.py --output-dir output/stereo_batch --batch-start 51 --batch-end 100 --stereo-baseline 0.1 --batch-render
cd ~/cht/SimpleProc/infinigen && CUDA_VISIBLE_DEVICES=1 ../blender/blender -b -P ../datagen/render_stereo_video.py -- --input /home/cht/cht/SimpleProc/output/stereo_batch/scene_0/scene.blend --output /home/cht/cht/SimpleProc/output/stereo_video_run0 --frames 360 --arc_degrees 360 --orbit_axis Z --total_pixels $((576*768)) --save_cams 1 --save_depth 1
--frames 360 调的更高可以使得采样频率变高
cd ~/cht/SimpleProc/infinigen && CUDA_VISIBLE_DEVICES=1 ../blender/blender -b -P ../datagen/render_stereo_video.py -- --input /home/cht/cht/SimpleProc/output/stereo_batch/scene_0/scene.blend --output /home/cht/cht/SimpleProc/output/stereo_video_run1 --frames 360 --arc_degrees 540 --orbit_axis Z --total_pixels $((576*768)) --save_cams 1 --save_depth 1 --orbit_radius_factor 1.5 --random_motion_deg 10 --random_motion_smooth 25 --motion_seed 42 --wobble_deg 7 --wobble_cycles 3
--orbit_radius_factor(默认 1.0) 在挂到 StereoVideoOrbit 父物体之后,把两个 camrig 相对枢轴的 局部位移统一乘以该系数。大于 1 时等价于绕着场景枢轴退远一圈
--random_motion_deg(默认 0)
在主轴轨道之上叠加 平滑随机欧拉角,XYZ 三路独立噪声,峰值约为设定度数(帧间用滑动平均平滑)。
--random_motion_smooth(默认 21) 平滑窗口越大,抖动越「缓」、越不像抽搐
--arc_degrees:仍可加大总转角(例如 540、720**)做多圈或更大弧长
--wobble_deg:在与主轴垂直的平面内做 正弦摆动(近似椭圆 tilt)。
--wobble_cycles:整条序列里摆动的周期数(例如3)。
ffmpeg -y -framerate 30 -i /home/cht/cht/SimpleProc/output/stereo_video_run0/left/%06d.png -framerate 30 -i /home/cht/cht/SimpleProc/output/stereo_video_run0/right/%06d.png -filter_complex "[0:v][1:v]hstack=inputs=2[v]" -map "[v]" -c:v libx264 -pix_fmt yuv420p /home/cht/cht/SimpleProc/output/stereo_video_run0/stereo_sbs.mp4
————————————
infinigen
python -m infinigen.datagen.manage_jobs --output_folder outputs/hello_stereo --overwrite --num_scenes 1 --specific_seed 0 --configs desert.gin simple.gin extras/stereo_training.gin --pipeline_configs local_256GB.gin stereo.gin blender_gt.gin --pipeline_overrides LocalScheduleHandler.use_gpu=True
(deset_gin 可以换成 snowy_mountain.gin、forest.gin、mountain.gin、plain.gin、river.gin、coast.gin、cliff.gin、canyon.gin、cave.gin、arctic.gin、kelp_forest.gin、under_water.gin、coral_reef.gin)
双目单图
cd ~/cht/infinigen && python -m infinigen.datagen.manage_jobs --output_folder outputs/stereo_video_rrt --overwrite --num_scenes 1 --specific_seed 0 --configs desert.gin simple.gin extras/stereo_training.gin extras/rrt_cam_nature.gin --pipeline_configs local_256GB.gin stereo_video.gin blender_gt.gin --pipeline_overrides LocalScheduleHandler.use_gpu=True iterate_scene_tasks.frame_range=[1,120] iterate_scene_tasks.cam_block_size=24 --overrides fine_terrain.mesher_backend="OcMesher"
双目动态图像系列
________________________________________________________________________
pi3x
cd /home/cht/cht/Pi3 && PYTORCH_CUDA_ALLOC_CONF=expandable_segm
ents:True python scripts/waft_stereo_pi3x_baseline.py --left_dir /mnt/nas/share/home/cht/ky_mirror/datasets
/zed_runi/rgb --right_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runi/right --waft_root /home/cht/c
ht/WAFT-Stereo --waft_config configs/SynLarge/DAv2L-5.yaml --waft_ckpt /home/cht/cht/WAFT-Stereo/ckpts/SynL
arge/DAv2L-5.pth --baseline_m 0.54 --fx_pixel 536.7 --max_frames 1045 --pixel_limit 120000 --pi3x_ckpt /hom
e/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --out_dir /home/cht/cht/Pi3/out_vo --vo_fusion --vo_chunk_size 6
0 --vo_overlap 20
DS=/home/cht/ky_mirror/datasets/zed_runj
PI3=/mnt/nas/share/home/cht/cht/Pi3/out_vo
mv "$DS/depth" "$DS/depth_ffs_backup"
mkdir -p "$DS/depth"
for i in $(seq 0 1044); do
src=$(printf "$PI3/depth_%03d.png" "$i")
dst=$(printf "$DS/depth/%06d.png" "$i")
ln -sf "$src" "$dst"
done
CUDA_VISIBLE_DEVICES=5 GSFUSION_POSE_MODE=orb GSFUSION_MAX_FRAMES=1045 \
bash ~/ky_mirror/Fast-FoundationStereo/scripts/run_gsfusion_on_tum.sh ~/ky_mirror/datasets/zed_runj orb
CUDA_VISIBLE_DEVICES=7 PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python scripts/waft_stereo_pi3x_baseline.py --left_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runi/rgb --right_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runi/right --waft_root /home/cht/cht/WAFT-Stereo --waft_config configs/SynLarge/DAv2L-5.yaml --waft_ckpt /home/cht/cht/WAFT-Stereo/ckpts/SynLarge/DAv2L-5.pth --baseline_m 0.54 --fx_pixel 536.7 --max_frames 600 --pixel_limit 120000 --pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --out_dir /home/cht/cht/Pi3/out_vo4 --vo_fusion --vo_chunk_size 60 --vo_overlap 20 --depth_max_m 40 --interval 2
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=6 PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python scripts/waft_stereo_pi3x_baseline.py --left_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runj/rgb --right_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runj/right --waft_root /home/cht/cht/WAFT-Stereo --waft_config configs/SynLarge/DAv2L-5.yaml --waft_ckpt /home/cht/cht/WAFT-Stereo/ckpts/SynLarge/DAv2L-5.pth --baseline_m 0.54 --fx_pixel 536.7 --skip_frames 400 --max_frames 1600 --pixel_limit 120000 --pi3x_ckpt /home/cht/cht/Pi3/runs/pi3x_waft_2011_09_29/manifest_waft_finetune_epoch4_finetuned.safetensors --out_dir /home/cht/cht/Pi3/out_vo4 --vo_fusion --vo_chunk_size 60 --vo_overlap 20 --depth_max_m 10 --depth_cap_mode zero --interval 2
微调 pi3x
cd /home/cht/cht/WAFT-Stereo && CUDA_VISIBLE_DEVICES=6 python scripts/export_pi3_waft_depth_kitti.py --config-file configs/SynLarge/DAv2L-5.yaml --ckpt ckpts/SynLarge/DAv2L-5.pth --date_dir /mnt/nas/datasets/kitti/raw_data/2011_09_29 --out_dir /home/cht/cht/Pi3/kitti/2011_09_29/waft_depth_npy --remove_invisible --max_drives 0
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=6 python scripts/build_kitti_finetune_manifest.py --date_dir /mnt/nas/datasets/kitti/raw_data/2011_09_29 --depth_ann_root /mnt/nas/datasets/kitti/depth_annotated --waft_depth_root /home/cht/cht/Pi3/kitti/2011_09_29/waft_depth_npy --out_json /home/cht/cht/Pi3/kitti/2011_09_29/manifest_waft_finetune.json --max_drives 0
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=6 python scripts/train_pi3x_waft_depth_finetune.py --manifest /home/cht/cht/Pi3/kitti/2011_09_29/manifest_waft_finetune.json --out_dir /home/cht/cht/Pi3/runs/pi3x_waft_2011_09_29 --pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True CUDA_VISIBLE_DEVICES=6 python scripts/tr ain_pi3x_waft_depth_finetune.py --manifest /home/cht/cht/Pi3/kitti/2011_09_29/manifest_waft_fi netune.json --out_dir /home/cht/cht/Pi3/runs/pi3x_waft_2011_09_29 --pi3x_ckpt /home/cht/cht/ Pi3/ckpts/Pi3X/model.safetensors --freeze_depth_encoder --finetune_aux_heads_nograd --no trainray_embed --no-adamw_foreach --clip_frames 4 --clip_stride 1 --batch_size 1
cd /home/cht/cht/WAFT-Stereo && CUDA_VISIBLE_DEVICES=6 \
python scripts/export_pi3_waft_depth_tartanair.py \
--tartanair_root /home/cht/datasets/tartanair \
--out_dir /home/cht/cht/Pi3/data/tartanair/waft_depth_npy \
--config-file configs/SynLarge/DAv2L-5.yaml \
--ckpt ckpts/SynLarge/DAv2L-5.pth \
--remove_invisible
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=6 \
python scripts/build_tartanair_finetune_manifest.py \
--tartanair_root /home/cht/datasets/tartanair \
--waft_depth_root /home/cht/cht/Pi3/data/tartanair/waft_depth_npy \
--out_json /home/cht/cht/Pi3/data/tartanair/manifest_waft_finetune.json
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=4 \
python scripts/train_pi3x_waft_depth_finetune.py \
--manifest /home/cht/cht/Pi3/data/tartanair/manifest_waft_finetune.json \
--out_dir /home/cht/cht/Pi3/runs/pi3x_waft_tartanair \
--pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --clip_frames 4 --clip_stride 1 --batch_size 1 --local_xyz_w 1.0(--scenes amusement --difficulties Hard --max_trajs 5、--max_frames_per_traj 200 等与导出脚本对称。)
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=3 PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python scripts/waft_stereo_pi3x_baseline.py --left_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runj/rgb --right_dir /mnt/nas/share/home/cht/ky_mirror/datasets/zed_runj/right --waft_root /home/cht/cht/WAFT-Stereo --waft_config configs/SynLarge/DAv2L-5.yaml --waft_ckpt /home/cht/cht/WAFT-Stereo/ckpts/SynLarge/DAv2L-5.pth --baseline_m 0.11985699832439423 --fx_pixel 1067.725830078125 --fx_input_is_original --skip_frames 400 --max_frames 1600 --pixel_limit 120000 --pi3x_ckpt /home/cht/cht/Pi3/runs/pi3x_waft_tartanair_xyz/manifest_waft_finetune_epoch4_finetuned.safetensors --out_dir /home/cht/cht/Pi3/out_vo4 --vo_fusion --vo_chunk_size 60 --vo_overlap 20 --depth_max_m 10 --depth_cap_mode zero --interval 2 --debug_depth_stats --save_raw_depth_vis
细化,最节省显存
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=3 python scripts/train_pi3x_waft_depth_finetune.py --manifest /home/cht/cht/Pi3/data/tartanair/manifest_waft_finetune.json --out_dir /home/cht/cht/Pi3/runs/pi3x_waft_tartanair_xyz --pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --clip_frames 4 --clip_stride 4 --batch_size 1 --local_xyz_w 0.01 --freeze_depth_encoder --no_train_ray_embed --no-adamw_foreach --skip_camera_head_in_train --skip_conf_head_in_train --skip_global_points_in_train --skip_rays_in_train
24GB down
cd /home/cht/cht/Pi3 && CUDA_VISIBLE_DEVICES=3 python scripts/train_pi3x_waft_depth_finetune.py --manifest /home/cht/cht/Pi3/data/tartanair/manifest_waft_finetune.json --out_dir /home/cht/cht/Pi3/runs/pi3x_waft_tartanair_xyz --pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --clip_frames 4 --clip_stride 4 --batch_size 1 --local_xyz_w 0.01 --no-adamw_foreach --skip_camera_head_in_train --skip_global_points_in_train
保存全部 depth
CUDA_VISIBLE_DEVICES=3 PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python scripts/waft_stereo_pi3x_baseline.py --left_dir /home/cht/cht/Pi3/data/MPI/stereo/training/final_left/alley_1 --right_dir /home/cht/cht/Pi3/data/MPI/stereo/training/final_right/alley_1 --waft_root /home/cht/cht/WAFT-Stereo --waft_config configs/SynLarge/DAv2L-5.yaml --waft_ckpt /home/cht/cht/WAFT-Stereo/ckpts/SynLarge/DAv2L-5.pth --baseline_m 0.1 --fx_pixel 688.0000610351562 --fx_input_is_original --skip_frames 0 --max_frames 50 --pixel_limit 120000 --pi3x_ckpt /home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors --out_dir /home/cht/cht/Pi3/out_mpi_alley1 --vo_fusion --vo_chunk_size 20 --vo_overlap 5 --depth_max_m 80 --depth_cap_mode zero --interval 1 --debug_depth_stats --save_raw_depth_vis --save_depth_npy --save_pi3x_depth_vis
Motioncrafter
CUDA_VISIBLE_DEVICES=6 python run.py /home/cht/outputs/motioncrafter_alley2/alley_2.mp4 --save_folder /home/cht/outputs/motioncrafter_alley2 --unet_path /home/cht/cht/MotionCrafter/workspace/cache/MotionCrafter --vae_path /home/cht/cht/MotionCrafter/workspace/cache/MotionCrafter --cache_dir /home/cht/cht/MotionCrafter/workspace/cache --height 320 --width 640 --adjust_resolution True --num_frames 25 --model_type determ --low_memory_usage True
dggt
CUDA_VISIBLE_DEVICES=7 conda run -n dggt python inference.py --image_dir /home/cht/datasets/Sintel/training/final/alley_2 --scene_names 0 --input_views 1 --sequence_length 4 --start_idx 0 --mode 2 --ckpt_path /home/cht/cht/DGGT/weight/model_latest_waymo.pt --output_path /home/cht/outputs/sintel_alley2_dynamic_mask -point_cloud --point_cloud_max_points 200000 --point_cloud_source depth
Bash语法
Shebang
#!/usr/bin/env bash告诉系统 请使用
/bin/bash这个程序来解释并运行接下来的内容
变量 (Variables)
注意:赋值时
=两边不能有空格。
name="Gemini"
echo "Hello, $name"条件判断 (Conditionals)
Bash 的括号非常讲究,建议使用
[[ ... ]]。
if [[ $name == "Gemini" ]]; then
echo "识别成功"
else
echo "未知用户"
fi"$( ... )" 和 "${ ... }"
"$( ... )"
它的作用是:执行括号内的命令,并把命令打印出来的结果拿回来使用。
双引号""
作用: 防止路径中包含空格。
后果: 如果你的文件夹叫
My Projects(带空格),没有引号的话,Bash 会把空间切断,导致脚本报错“找不到 My 文件夹”。加上引号后,整个路径会被视为一个整体。
${ ... }:参数扩展防止歧义(边界定界)
name="data"
echo "$name_file" # 错误:系统会去找名为 $name_file 的变量
echo "${name}_file" # 正确:打印 data_file
默认值处理
# 如果 FFS_ROOT 没设置,就使用后面的默认路径
ROOT="${FFS_ROOT:-/default/path}"
ffs 和 guas-slam相关脚本 Fast-FoundationStereo/scripts/run_gaus_slam_zed.sh为例
set -euo pipefail
-e(errexit): 只要任何一个命令返回非零值(即出错),脚本立即退出。-u(nounset): 如果使用了未定义的变量,报错并退出。防止因为拼写错误(比如把$RESULT写成$RESUL)导致意想不到的后果。-o pipefail: 只要管道命令(如A | B | C)中任何一个环节失败,整个管道就被视为失败。默认情况下,Bash 只看最后一个命令的成功与否。
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
${BASH_SOURCE[0]}永远能拿到脚本文件本身的路径dirname 去掉路径中的文件名,只保留目录部分
cd ... && pwd—— 转换为绝对路径
"${FFS_ROOT:-$SCRIPT_DIR/..}"
:- 这是核心操作符,意思是:“如果左边的变量未设置或为空,则使用右边的值”
DS_INPUT="${1:?用法: $0 /path/to/zed_dataset}"
(核心作用是:“如果用户运行脚本时没给参数,直接报错并自毁。”)
:? 这是一个 “必填检查” 操作符。
如果
$1存在且不为空,它就返回 $1 的值。如果
$1为空或未设置,它会把后面的字符串作为错误信息打印到标准错误流(stderr),并立即终止脚本(退出状态码为 1)。
文件存在性校验
if [[ ! -f "$DS/meta.json" ]]; then
echo "错误: 缺少 $DS/meta.json" >&2
exit 1
fiif [[ ... ]]; then ... fi 是条件判断,[[...]]这样更稳健
-f:这是一个文件测试操作符,检查路径是否为普通文件(如果路径是一个目录或者不存在,则为假)。>&2
默认情况下,
echo的输出去往“标准输出 (stdout)”。在 Linux 规范中,报错信息应该通过“标准错误 (stderr)”通道发出。这样即使你把脚本的正常运行结果保存到文件里(例如 ./script.sh > output.txt),错误提示依然能直接显示在你的屏幕上,而不会混进结果文件里。
[[ -z "$(ls -A "$DS/depth" 2>/dev/null || true)" ]]
ls -A:列出目录下所有文件,但不包括.和..(当前目录和父目录)。2>/dev/null:如果文件夹不存在,
ls会报错。这行代码把错误信息扔掉,不显示在屏幕上。|| true:这是一个安全锁。防止 ls 报错导致整个脚本因为 set -e 而崩溃。$( ... ):获取命令执行的输出。-z:检查字符串是否为空。
结论:如果文件夹存在但里面没东西,该条件为“真”。
Scal3R 对 VGGT的利用
入口: run.py , run_inference
和上面我写的框架类似,run.py 组装好 request 和 config ,然后给 run_inference 进行最终的 command执行
辅助函数 load_data()
收集图片路径 (Image Collection)
if recorder is not None:
recorder.record('collect_images.begin', input_dir=args.input_dir, image_patterns=args.image_patterns)
image_paths = collect_image_paths(args.input_dir, args.image_patterns)
if args.max_images > 0:
image_paths = image_paths[:args.max_images]
# ... recorder 打点与 maybe_stop_after ...
功能: 根据传入的
input_dir和image_patterns(如*.png,*.jpg),扫描目标文件夹,获取所有符合条件的图片绝对路径。截断: 如果配置了
max_images(大于 0),则截取前 N 张图片,常用于快速测试或截断过长的序列。探针 (Recorder): 在开始和结束时记录状态(图片总数、首尾图片路径),并支持在收集完成后提前终止程序(
maybe_stop_after),方便调试。
加载与预处理图片 (Load & Preprocess)
# ... recorder 打点 ...
sequence, height, width = load_and_preprocess_images(
image_paths,
dataset_cfg,
preprocess_workers=args.preprocess_workers,
)
# ... recorder 打点与 maybe_stop_after ...
功能: 调用
load_and_preprocess_images,使用多线程(由preprocess_workers控制)并行读取图片。处理内容: 根据
dataset_cfg中的规则,这通常包括调整图片尺寸(Resize)、中心裁剪(Center Crop)或颜色归一化等操作。返回: 返回预处理好的图像序列(sequence),以及统一后的高度(height)和宽度(width)。
计算分块参数 (Chunking Math)
这是该函数中最核心的逻辑之一,用于将长序列拆分成模型可处理的小块,这也是 VGGT-Long 和 Scal3R 解决显存限制的关键策略 。
n_samples = len(sequence)
block_size, overlap_size = args.block_size, args.overlap_size
assert block_size > overlap_size, f'[ERROR] block_size {block_size} must be larger than overlap_size {overlap_size}'
n_srcs = block_size
n_blocks = (n_samples - overlap_size + (n_srcs - overlap_size) - 1) // (n_srcs - overlap_size)
if n_blocks == 0 or n_samples <= block_size:
block_size = n_samples
n_srcs = n_samples
n_blocks = 1
防御性编程: 确保块的大小(
block_size)严格大于重叠的大小(overlap_size),否则分块逻辑会陷入死循环或计算错误。计算总块数 (
n_blocks): 这是一个经典的滑动窗口计算公式。序列总长度为
n_samples。除了第一个块,后续每个块向前步进的距离是 (block_size - overlap_size)。
公式
(n_samples - overlap_size + step - 1) // step相当于向上取整,确保即使最后剩下的图片不足一个完整的block_size,也会被分配到一个新的块中。
极短序列兜底: 如果总图片数
n_samples还不如一个block_size大,那么就只划分 1 个块(n_blocks = 1),块的大小等于图片总数。默认 一个块 含 60张图
backend.py --> main()
@log_exceptions(logger, "Unhandled exception in backend")
def main():作用: 这是一个 Python 装饰器。由于
backend.py是被主进程(run.py)拉起的独立子进程,如果它在跑 GPU 算力时因为某些底层错误(比如显存溢出、张量维度不对)突然崩溃,直接抛出系统级的 Traceback 会非常难看,且容易导致父进程假死。优雅兜底: 这个装饰器会像一张网一样兜住 main() 函数里所有未被捕获的崩溃异常,用
logger把它工工整整地记录到日志文件里,然后再安全退出。
args = parse_args()
args.config = str(resolve_release_path(args.config))
args.result_dir = str(resolve_release_path(args.result_dir or get_default_output_dir("run")))
args.runtime_dir = str(resolve_release_path(args.runtime_dir) if args.runtime_dir else join(args.result_dir, 'runtime'))
if args.checkpoint:
args.checkpoint = str(resolve_release_path(args.checkpoint))
if args.loop_ckpt:
args.loop_ckpt = str(resolve_release_path(args.loop_ckpt))
if args.offload_dir:
args.offload_dir = str(resolve_release_path(args.offload_dir))
if args.probe_dir:
args.probe_dir = str(resolve_release_path(args.probe_dir))子进程 接受 参数,全换成绝对路径
device = torch.device(args.device)将传入的设备字符串(比如
cuda、cuda:0或cpu)转化为 PyTorch 能够识别的硬件对象。在此之后,所有的模型、张量(Tensor)都会认准这个device进行计算。
sampler, dataset_cfg = build_sampler_from_config(args.config, device, args.checkpoint)sampler是已加载权重、在指定设备上 eval 的 Scal3R 模型;dataset_cfg是与配置里 dataloader/val 对齐的、带默认补全的图像/相机预处理参数字典,供后续和训练时数据管线一致地预处理输入。
amp_enabled = bool(args.test_use_amp and device.type == 'cuda')
amp_dtype = torch.bfloat16 if device.type == 'cuda' and torch.cuda.get_device_capability(device)[0] >= 8 else torch.float16AMP 的意义: 开启混合精度后,PyTorch 会自动把一部分计算降级到 16 位浮点数。这不仅能将显存占用减半,还能在较新的显卡上让计算速度翻倍。
with torch.no_grad():
with torch.amp.autocast('cuda', enabled=amp_enabled, dtype=amp_dtype):
output = forward(sampler, batches, args, recorder=recorder)在训练模型时,PyTorch 会悄悄记录所有的计算步骤以便反向传播算梯度,这会吃掉海量的显存。因为我们现在是在做推理(Inference),加上这句,就彻底掐断了梯度记录机制
让刚才配置好的混合精度策略(AMP)在
forward运行期间全局生效。巨大的数据块被送进
forward函数(也就是送进了 VGGT 骨干网络和后续的各种 Decoder),吐出了一堆局部的相机位姿、深度图和 3D 点云(存放在output中)
processed, output, batches, indices, visualize = post_process(
output,
batches,
...
alignment='sim3_wet',
)神经网络跑出来的 output 并不是直接可用的。为什么? 因为在长序列拆分策略中,网络是“逐块(Chunk)”处理的。它算出来的 3D 坐标全是局部的(Local)。第一个块认为自己是世界中心,第二个块也认为自己是世界中心。
对齐与缝合:
post_process函数就是做几何对齐的。它利用相邻数据块之间的重叠区(Overlap),把所有局部的 3D 点云和相机轨迹,通过 Sim(3) 变换(旋转、平移、缩放)强制拼接到同一个全局绝对坐标系下。消除漂移: 如果之前检测到了闭环(
n_blocks_loop > 0),它还会在这里触发位姿图优化(PGO),把长时间累积的漂移误差狠狠地拉回正轨。
辅助函数 store_agg_state()
backend.py --> forward()
output = [None for _ in range(len(batches))]
batch0 = materialize_payload(batches[0])
B, S = batch0.meta.rgb.shape[:2]
H, W = batch0.meta.H[0].item(), batch0.meta.W[0].item()
N = len(batches)
del batch0
assert B == 1, f'[ERROR] this implementation only supports B=1 for sequential inference, got B={B}.'
探路兵
batch0:程序首先把第一个数据块(batch0)从硬盘或内存深处“具现化(materialize)”出来。提取关键维度:从
batch0的元数据(meta)中,提取出张量的核心维度:B: Batch size(批次大小),这里断言必须等于 1,因为目前做的是单序列的顺序推理。S: Sequence length(序列长度),也就是一个数据块里包含了几张图片(即block_size)。H,W: 图片的高和宽。N: 总数据块的数量。
agg_state_refs = [None for _ in range(len(batches))]
dpt_state_refs = [dict() for _ in range(len(batches))]
dpt_layer_set = set(model.agg_regator.intermediate_layer_idx)深度学习模型(特别是像 Transformer 这种基于序列的模型)在逐层、逐块处理数据时,需要极其精细的状态管理 (State Management)。
agg_state_refs(Aggregator States):这是一个列表,用来存放每个数据块在进入特征聚合网络(Aggregator)时的中间状态。dpt_state_refs(Depth/Point States):用来存放需要跨层传递的特征(往往是用于最后生成深度图或点云的中间层输出)。某层 forward_layer 若需要 temp_output,在 persist_dpt_state 里按 层号 写入
对每个 batch 各建一个「自己的」空字典
agg = attention 主干还在算时要带着跑的状态;dpt = 从指定层「抽出来」给头网络做 dense 预测的特征字典。
dpt_layer_set:从模型的配置中读取,记录“在第几层我们需要把特征提取出来,放进上面的dpt_state_refs里存着”。set 是 Python 的 集合 类型:无序、元素不重复,适合做 「某元素在不在集合里」 的 O(1) 平均查找。
为什么叫
_refs(References)? 因为如果你的数据量非常大,这些中间状态(巨大的张量)可能会爆掉显存。所以代码后续可能会采用一种叫“显存卸载(Offloading)”的技术——把这些状态临时写到硬盘上,内存里只存一个“引用(Reference)”。当需要用的时候,再通过这个引用把它从硬盘里读出来
for b, batch_ref in enumerate(batches):
batch = materialize_payload(batch_ref)
rgb = rearrange(to_cuda(batch.meta.rgb, args.device), 'b n (h w) c -> b n c h w', h=H, w=W)enumerate(batches) 遍历列表 batches,每次给出 (下标, 元素)。
具现化 (
materialize_payload): 为了省内存,前面的阶段可能已经把打包好的数据块卸载(Offload)到硬盘上了,内存里只有一个很小的引用(batch_ref)。这句话就是把真正几十兆的图片数据从硬盘瞬间拉回内存。上显卡 (
to_cuda): 把数据真正送入 GPU 的显存。张量整形 (
rearrange): 这是一句极其优雅的einops代码。图片数据在预处理阶段往往被展平了(h w 混在一起)。这句代码像变形金刚一样,把扁平的数据重新组装成标准的 5 维视频张量格式:B(批次),N(帧数),C(通道数 RGB),H(高度),W(宽度),以符合 3D 卷积或 Vision Transformer 的输入标准。来自
einops.rearrange:用 带名字的维度模式 描述 输入形状 → 输出形状;模式里的
h、w是 符号名,必须和 实际张量尺寸 对上。这里H、W是前面从 batch 里算好的 整型高宽,传给rearrange
agg_state = model.agg_regator.prepare(rgb)
agg_state_refs[b] = store_agg_state(agg_state, args, b)
...
del batch, rgb, agg_state
if should_release_runtime_state(args):
release_memory(args.device)Dino v2 提取特征
存储并换出 (
store_agg_state): 算出来的特征(agg_state)极大,如果把所有数据块的特征都堆在显存里,显卡秒爆。这个函数会把算好的特征安全地存起来(如果配置了--streaming_state,它甚至会把特征写到硬盘上),并返回一个极小的引用。阅后即焚 (
del): 毫不留情地利用 Python 的del关键字,手动删掉刚刚用完的原始图片张量(rgb)、载荷(batch)和特征(agg_state)。倒垃圾 (
release_memory): 光del还没用,显存通常会有碎片。这里底层通常调用了torch.cuda.empty_cache(),强制 PyTorch 把显存归还给操作系统,保证下一个数据块进来时,显存是绝对干净和充足的。
for j in range(model.agg_regator.aa_block_num):
forward_intermediate_layers = collect_intermediate_layers(model, j)
need_forward_outputs = len(forward_intermediate_layers) > 0
...
for b, _ in enumerate(batches):先遍历层 再遍历块
传统思维: 通常我们会把一个数据块(Block)完整地跑完网络的所有层(Layer 0 到 Layer 24),然后再跑下一个数据块。
Scal3R 的特殊设计(Layer-First): 这里是先把所有的数据块都跑完第 j 层,然后再让所有数据块一起进入第 j+1 层。
为什么要这样反直觉? 因为 Scal3R 架构中包含 TTT(测试时训练)。TTT 需要在某一层(比如第 11 层)收集**整个长视频(所有块)**的梯度,计算出一个全局更新的权重,然后再应用给所有块。如果不采用这种“齐头并进”的遍历方式,就无法实现跨块的信息同步。
aa.block_num : 整条交替注意力堆栈一共要调用多少次 forward_layer
collect_intermedia_layers
函数做的事:在 [start_index, start_index+1, …, start_index+aa_block_size-1] 里,筛出 落在 intermediate_layer_idx 集合里的那些层号,返回 list[int]。
为 DPT 分配/填充这些层输出 在做 3D 重建或深度图预测时,不仅需要网络最后一层的高级语义特征,还需要中间层的底层纹理特征
如果 函数为真的话,就在 下面的 batches用 temp_output接住 这一层的输出
agg_state = materialize_payload(agg_state_refs[b])
updated_state = model.agg_regator.forward_layer(
index=j, output=temp_output, **to_cuda(agg_state, args.device),
)提取状态: 把第 b 个数据块在上一层(j-1)算好的状态(
agg_state),从内存或硬盘里具现化并拉回 GPU(to_cuda)。进入注意力层: 调用
forward_layer。在这一层里,视频帧之间会进行密集的 Attention 计算,理解物体在不同视角下的遮挡和运动。算完后,吐出updated_state准备给下一层用。用在「函数调用」里,表示:把右边那个「字典类对象」拆成一组关键字参数; 若:
d = to_cuda(agg_state, args.device) # 假设得到 {"tokens": t, "pos": p, "B": B, ...}则:
forward_layer(index=j, output=temp_output, **d)等价于(键名要合法、且不能与已有参数冲突):
forward_layer(index=j, output=temp_output, tokens=t, pos=p, B=B, ...)也就是:把 agg_state 里各字段当作 forward_layer 的具名参数传进去。
agg_state_refs[b] = store_agg_state(updated_state, args, b)
if temp_output is not None:
persist_dpt_state(temp_output, dpt_state_refs[b], args, b)
del agg_state, updated_state, temp_output
if should_release_runtime_state(args):
release_memory(args.device)存储并卸载 (
store_agg_state&persist_dpt_state): 刚刚算出来的updated_state(本层状态)和temp_output(中间层特征)加起来可能好几 GB。程序绝不允许它们一直待在显卡里。它会立刻把这些张量踢回内存(甚至写入硬盘),在显存里只保留一个极小的“引用指针”。
with torch.amp.autocast('cuda', enabled=False):
if (model.agg_regator.frame_use_ttt or model.agg_regator.global_use_ttt) and j in model.agg_regator.ttt_layer_idx:
apply_ttt(model, agg_state_refs, dpt_state_refs, args, j, dpt_layer_set)autocast('cuda', enabled=False)
就在几行代码之前,我们开启了 test_use_amp(混合精度加速)。为什么到了这里,又要用 enabled=False 强行把它关掉?
致命的梯度消失: 前向推理(Forward)时,张量的数值比较大,用 16 位浮点数(FP16/BF16)算又快又省显存。但是,TTT 的本质是在推理时做了一次微型的反向传播(Backpropagation)。
物理极限: 梯度的数值往往极其微小(比如 $10^{-6}$ 级别)。如果继续用 16 位浮点数来算梯度,这些微小的数值会直接“下溢”变成 0(Gradient Underflow),导致模型学不到任何东西,甚至直接崩溃报 NaN。所以,在这里必须强行切回 32 位最高精度(FP32),这叫**“拿速度换稳定性”**。
apply_ttt 修改什么?
agg_state_refs(每个 block)
agg_state_refs[block_index] = store_agg_state(updated_state, args, block_index)updated_state 来自 ttt_apply,里面的 tokens 会 加上 该层用 更新后的 (w_0,w_1,w_2) 跑 global_blocks[layer_index].ttt(...) 的输出(见 aggregator.ttt_apply 里 tokens += ...)。
因此:每个 block 的 aggregator 状态里的 tokens(以及打包进 dict 的其它字段)被换成 TTT apply 之后的新状态;若开 streaming,则是 换磁盘引用
dpt_state_refs
当 layer_index in dpt_layer_set 时构造 temp_output,ttt_apply 里若 index in self.intermediate_layer_idx 会 改写 output[index](把 原 DPT 特征 与 新 tokens 视图 再 concat)

ttt_update
for b, dpt_state in enumerate(dpt_state_refs):
dpt_state[-1] = dpt_state[model.agg_regator.depth - 1]
remove_payload(agg_state_refs[b])
agg_state_refs[b] = None
``````````````````````````````````````````etc...
clear_dpt_state(dpt_state_refs[b])
del batch, block_output, cam_map
del cam_maps, xyz_map, xyz_cnf, dpt_map, dpt_cnf, rgb_feats, rgb
if should_release_runtime_state(args):
release_memory(args.device)
if recorder is not None:
recorder.record(
f'decoder_block_{b:02d}.done',
block_index=int(b),
offload_outputs=bool(args.offload_outputs),
)
maybe_stop_after(f'decoder_block_{b:02d}.done', args, recorder)
pbar.update()
pbar.close()
if recorder is not None:
recorder.record('decoder.done', n_blocks=int(N))
maybe_stop_after('decoder.done', args, recorder)
return output
执行三大解码头等等
cam_maps = model.cam_decoder(rgb_feats)
xyz_map, xyz_cnf = model.xyz_decoder(
rgb_feats, images=rgb, patch_start_idx=model.agg_regator.patch_start_idx,
)
dpt_map, dpt_cnf = model.dpt_decoder(
rgb_feats, images=rgb, patch_start_idx=model.agg_regator.patch_start_idx,
)aggregator.py --> forward_layer()
def forward_layer(
self,
index: int,
tokens: torch.Tensor,
B: int, S: int, P: int, C: int,
pos: torch.Tensor = None,
cameras: torch.Tensor = None,
camera_dropout: bool = False,
output: dict = None,
):index: 当前正在处理的注意力层的索引(Layer Index)。tokens: 输入的特征张量。B, S, P, C: 描述张量形状的四个核心维度:B (Batch): 批次大小。
S (Sequence): 序列长度(视频帧数或图像组的数量)。
P (Patch): 每张图像被划分的 Patch(块)数量。
C (Channel): 特征的通道维度。
pos: 旋转位置编码(Rotary Position Embedding, RoPE),用于注入空间位置信息。cameras/camera_dropout: 相机内参/外参的先验特征,以及是否应用 Dropout 以防止过拟合。output: 一个字典,用于暂存需要传递给下游解码器(如深度图预测)的中间层特征。
# Perform one layer of attention based on the aa_order
# NOTE: only pure original transformer block here, no TTT is enabled
for attn_type in self.aa_order:代码会遍历
self.aa_order(在初始化中默认为["frame", "global"])
if attn_type == "frame":
tokens, _, frame_intermediates = self._process_frame_attention(
tokens, B, S, P, C, index,
pos=pos, cam=cameras, cam_drop=camera_dropout,
enable_ttt=False,
)触发条件:当遍历到
"frame"时执行。行为:调用
_process_frame_attention方法。该方法会将tokens的形状视作 (B*S, P, C),这意味着注意力机制只在同一帧的 P 个 Patch 之间进行计算。目的:提取和强化单张图像内部的局部纹理和空间几何细节。
返回值:更新后的
tokens,以及提取出的帧内中间特征frame_intermediates。
elif attn_type == "global":
tokens, _, global_intermediates = self._process_global_attention(
tokens, B, S, P, C, index,
pos=pos, cam=cameras, cam_drop=camera_dropout,
enable_ttt=False,
output=output,
)触发条件:当遍历到
"global"时执行。行为:调用
_process_global_attention方法。该方法通常会将tokens的形状视作 (B, S*P, C),让注意力机制跨越时间维度,在所有 S 帧的所有 Patch 之间进行交互。目的:建立跨帧的匹配关系和全局 3D 几何一致性(类似传统 SfM 中的特征点匹配与三角测量)。
返回值:再次更新的
tokens,以及提取出的全局中间特征global_intermediates。
backend.py --> apply_ttt
def apply_ttt(model, agg_state_refs, dpt_state_refs, args, layer_index: int, dpt_layer_set: set[int]):
ttt_order_grad = deepcopy(model.ttt_order[0:1])
ttt_order_grad = [order._replace(use_cached=False)._replace(cache_last=False) for order in ttt_order_grad]
ttt_order_apply = deepcopy(model.ttt_order[-1:])
ttt_order_apply = [order._replace(use_cached=False)._replace(cache_last=False) for order in ttt_order_apply]
w0_grad_sum, w1_grad_sum, w2_grad_sum = None, None, None
shared_tokens = None何为 deepcopy?
model.ttt_order[0:1]:取列表ttt_order的 第 0 个元素,但保持 类型仍是 list(长度为 1),而不是单个元素。deepcopy(...):得到 一份全新的 list,且里面的TTTOperator(或类似 dataclass/namedtuple) 若是 可变嵌套结构,也会被 递归复制;之后对ttt_order_grad里对象的 原地修改(例如_replace、改字段)不会 改到model.ttt_order里那份。newdict = dict(lastdict) 浅拷贝,里面元素是 list 的话会被同步修改
ttt_order 哪来的?
ttt_order 是 Scal3R 模型上的一个 实例属性,在 Scal3R.__init__ 里赋值,来源是 default_ttt_order()。
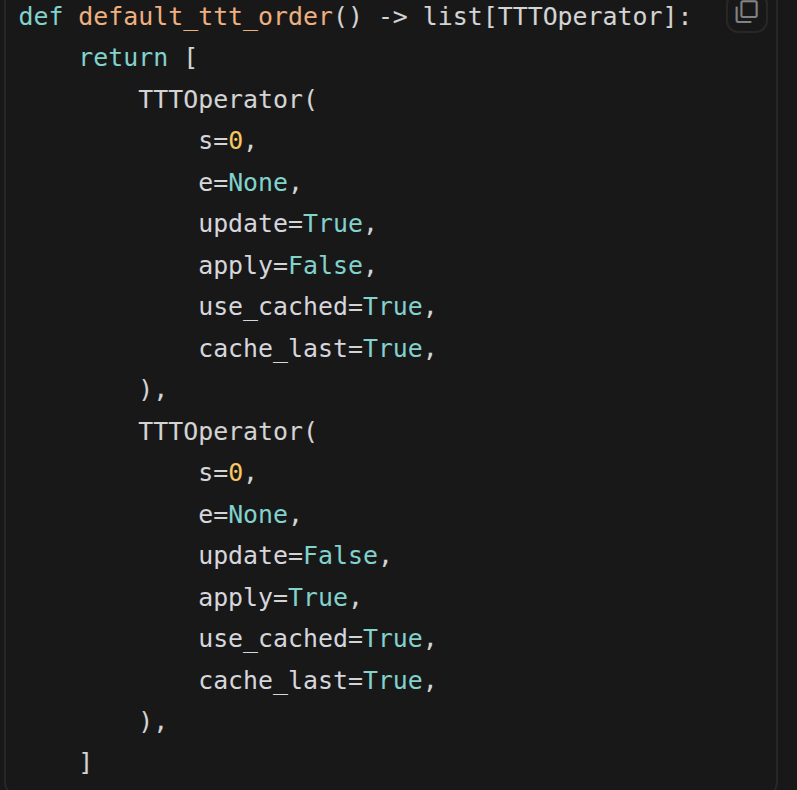
即:长度为 2 的列表,元素类型是 TTTOperator(在 scal3r/utils/ttt_utils.py 里定义)。语义上是 两阶段默认策略:先 只 update、不 apply,再 只 apply、不 update(具体由 ttt_utils 里读这些字段)
backend.py 中 有 scal3r 的 初始化?
backend.py里没有直接写Scal3R(...)这种「在文件里 new 一个Scal3R」的初始化。模型是在
main()里通过build_sampler_from_config间接建出来的:sampler, dataset_cfg = build_sampler_from_config(args.config, device, args.checkpoint)
_replace 返回一个新实例,只改你传入的字段,其余字段从旧
order拷贝。order._replace(use_cached=False)关闭了所有的缓存. 因为现在是在做跨 Block 的大循环累加,如果不关闭缓存,显存会随着处理的 Block 数量线性爆炸。这是一种极端的显存保护机制
w0_grad_sum, w1_grad_sum, w2_grad_sum = None, None, None
shared_tokens = Nonew0_grad_sum等:TTT 模块内部有三个需要更新的权重矩阵。这里初始化为None,准备在后续的循环中,把每个 Block 算出来的梯度“累加”到这些变量上(即 Gradient Accumulation)。这使得模型能在逻辑上“一次性”看到整个长视频的全局梯度,而物理上却是一块一块处理的。shared_tokens:用于暂存更新权重时需要的共享 Token 引用。
Aggregator 类核心方法 ttt_gradient。
在 Scal3R 的设计中,TTT 分为三个标准步骤:计算梯度(Gradient) -> 更新权重(Update) -> 应用特征(Apply)
第一步:在前向推理时,计算出用于微调模型权重的梯度,但不直接修改权重
""" Only global attention is used for TTT gradient computation """
assert self.global_use_ttt, "Global TTT must be enabled for compute_ttt_gradient"
assert not self.training, "Model must not be in training mode for compute_ttt_gradient"为什么只用全局注意力? 注释明确指出,只有全局(跨帧)注意力会被用于计算 TTT 的梯度。因为 TTT 的目的是让模型在当前视频序列中找到最佳的多视角几何一致性,这必须依赖跨帧的信息交互。
两个
assert断言:必须在配置中开启了全局 TTT (
global_use_ttt)。模型必须处于评估/推理模式 (
not self.training)。TTT 是“测试时”训练,如果在标准训练阶段调用它,会导致计算图和梯度更新的严重混乱。
# Deal with shape things
if tokens.shape != (B, S * P, C):
tokens = tokens.view(B, S, P, C).view(B, S * P, C)
if pos is not None and pos.shape != (B, S * P, 2):
pos = pos.view(B, S, P, 2).view(B, S * P, 2)它将
tokens的形状强制转换为(B, S * P, C)。
# Deal with TTT parameters
ttt_cache, ttt_fastw, ttt_steps = self._get_ttt_state(self.global_ttt_caches[index])模型需要知道当前层(
index)的 TTT 进度。通过访问self.global_ttt_caches,提取出三个核心变量:ttt_cache:历史缓存,用于加速梯度的自回归计算。ttt_fastw:当前的**快速权重(Fast Weights)**状态。ttt_steps:当前已经进行了多少步 TTT 迭代。
# Compute TTT inner loop update gradients, no actual update
w0_grad, w1_grad, w2_grad = self.global_blocks[index].ttt.gradient(
tokens, pos, ttt_order, ttt_cache, ttt_fastw, ttt_steps, self.block_token,
batch_size=B, S=S, P=P, C=C, patch_start_idx=self.patch_start_idx,
)
return w0_grad, w1_grad, w2_grad调用内部梯度函数:将整理好的数据和状态,传入当前层对应的
global_blocks[index].ttt.gradient方法中。返回梯度字典:计算完成后,返回
w0_grad, w1_grad, w2_grad。这些是针对 TTT 模块内部三个不同权重矩阵(通常对应于输入投影、隐藏层变换和输出投影)的梯度值。分离设计的精妙之处:请注意注释
no actual update。这个函数只负责“算”,不负责“改”。这种解耦设计使得系统可以将多个数据块(Batches)的梯度汇总(Gradient Accumulation)后,再统一执行更新(由ttt_update方法负责),这对于处理因显存限制而切分的长视频序列尤为重要。
aggregator.py --> processframe_attention()
def _process_frame_attention(
self, tokens, B, S, P, C, frame_idx,
pos=None, cam=None, cam_drop=False,
ttt_order=None, enable_ttt=True,
):
# If needed, reshape tokens or positions:
if tokens.shape != (B * S, P, C):
tokens = tokens.view(B, S, P, C).view(B * S, P, C).view(...):在 不拷贝数据(张量需 内存连续,否则可能要先 .contiguous())的前提下,只改「形状」解释方式
reshape功能类似可以接受不连续,若不连续 → 往往会 先拷贝成连续再 view,一般能成功,但可能 多一次拷贝。
if self.frame_use_ttt:
ttt_cache, ttt_fastw, ttt_steps = self._get_ttt_state(self.frame_ttt_caches[frame_idx])
else:
ttt_cache = None
ttt_fastw = tuple()
ttt_steps = 0代码首先检查是否启用了帧内 TTT (
self.frame_use_ttt)。如果启用,调用
_get_ttt_state从缓存self.frame_ttt_caches中提取当前层(frame_idx)的 TTT 状态。ttt_cache:用于加速 TTT 计算的缓存数据。ttt_fastw(Fast Weights):这是 TTT 的灵魂!它代表“快速权重”。与模型训练好后固定不变的“慢速权重”不同,快速权重是在推理当前序列时临时计算并叠加在基础权重上的。ttt_steps:记录当前 TTT 优化已经执行了多少步。
# by default, self.aa_block_size=1, which processes one block at a time
for _ in range(self.aa_block_size):
tokens = self.frame_blocks[frame_idx](
tokens, pos, cam, cam_drop,
ttt_order, ttt_cache, ttt_fastw, ttt_steps, self.block_token, enable_ttt, B, S, P, C, self.patch_start_idx,
)
frame_idx += 1
intermediates.append(tokens.view(B, S, P, C))self.aa_block_size:控制每次交替注意力(Alternating Attention)连续执行多少个同类型的 Transformer 块。注释中说明默认值为 1,即“算一层帧内,就算一层全局”,以此交替。self.frame_blocks[frame_idx](...):这是真正执行计算的地方。它调用了具体的 Transformer Block。输入参数极其丰富:除了常规的
tokens和位置编码pos,它还将刚刚准备好的ttt_fastw(快速权重)和控制 TTT 流程的ttt_order传了进去。结合上文讲到的张量形状重塑,此时模型正在并行的处理每一帧图像,提取其内部的局部特征。
收集结果:
frame_idx += 1:指针下移,为下一层做准备。intermediates.append(...):将计算完的tokens重新变回 4D 形状 (B, S, P, C),并存入intermediates列表中。这些中间结果后续会被提供给深度图解码器(DPT Head)使用。
DPT 出特征
scal3r/pipelines/backend.py → forward
初始化
dpt_state_refs = [dict() for _ in range(len(batches))],每个 block 一个 「层号 → 特征」 容器。dpt_layer_set = set(model.agg_regator.intermediate_layer_idx):哪些全局层要参与 DPT / TTT 里对output的读写。
Aggregator 阶段
对每个宏层
j:collect_intermediate_layers(model, j)(同文件):判断本步是否要向output里塞中间特征。model.agg_regator.forward_layer(..., output=temp_output)若 temp_output 非空:
persist_dpt_state(temp_output, dpt_state_refs[b], args, b)(offload_utils)→ 把本 block 本步产生的 各层 concat 特征 写入 dpt_state_refs[b][layer_id](可 offload)。
若该层要做 TTT:
apply_ttt(...)里会persist_dpt_state更新 对应层 在 dpt_state_refs 里的张量(与ttt_apply里改写的output[index]一致)。
Aggregator 结束后
整理传递给解码器的最终特征,并无情地清理掉不再需要的聚合器状态,以释放极为宝贵的显存或内存
for b, dpt_state in enumerate(dpt_state_refs): dpt_state[-1] = dpt_state[model.agg_regator.depth - 1] remove_payload(agg_state_refs[b]) agg_state_refs[b] = Nonedpt_state是一个字典,键(Key)是层号,值(Value)是那一层输出的特征张量。model.agg_regator.depth - 1代表聚合器的最后一层的绝对索引(例如,如果是 24 层的网络,最后一层就是索引 23)。 下游的解码器(比如相机预测头)通常会默认通过键-1来直接获取网络最深层、语义最丰富的全局特征remove_payload(...):因为聚合器(Aggregator)的前向传播和 TTT 权重更新已经彻底结束,这些庞大的状态数据已经完成了历史使命。remove_payload会在底层清理这些数据,如果它们之前被offload到了磁盘或内存,这里会直接将相关文件或缓存抹除。= None:解除 Python 变量对该对象的引用。这样一来,Python 的垃圾回收机制(GC)就会立即介入,将内存完全回收。
Decoder阶段
rgb = rearrange(batch.meta.rgb, 'b n (h w) c -> b n c h w', h=H, w=W).to(args.device) cam_maps = model.cam_decoder(rgb_feats) xyz_map, xyz_cnf = model.xyz_decoder( rgb_feats, images=rgb, patch_start_idx=model.agg_regator.patch_start_idx, ) dpt_map, dpt_cnf = model.dpt_decoder( rgb_feats, images=rgb, patch_start_idx=model.agg_regator.patch_start_idx, )rgb重排: 使用einops.rearrange将原始的 RGB 图像从展平的块状态(h w)还原为标准的 2D 卷积输入形状:(批次 Batch, 帧数 N, 通道 C, 高度 H, 宽度 W),并放入 GPU。相机解码头 (
cam_decoder):仅利用提取到的特征序列 rgb_feats,预测相机的内参和外参(位姿信息)。3D 坐标解码头 (
xyz_decoder):结合深层特征 rgb_feats 和原始图像 rgb,预测场景中每个像素在世界坐标系下的 3D 坐标 (xyz_map),同时输出模型对该预测的置信度 (xyz_cnf)。深度解码头 (
dpt_decoder):原理与xyz_decoder类似,但输出的是每个像素对应的深度图 (dpt_map) 和相应的深度置信度 (dpt_cnf)。
相机预测头(CameraHead)
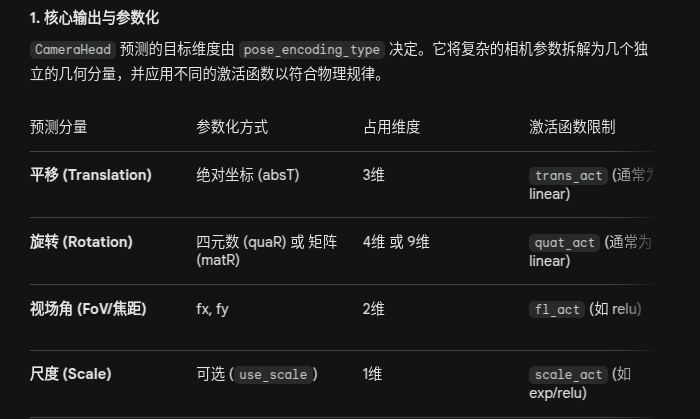
关键网络组件
该模块在 __init__ 中初始化了几个专门负责不同任务的子网络:
干线网络 (
self.trunk):由多个 Transformer 块(Block)组成的序列(深度默认为 4)。它负责在特征空间中处理和加工相机 Token。空位姿嵌入 (
self.empty_pose_tokens&self.embed_pose):因为预测是迭代的,第一次预测时没有“上一次的位姿”,所以系统学习了一个可优化的零向量作为初始状态。调制生成器 (
self.poseLN_modulation):一个包含 SiLU 激活的 MLP。它接收当前的位姿状态,输出用于特征调制的三个向量:shift(偏移)、scale(缩放)和gate(门控)。预测输出层 (
self.pose_branch):一个将高维特征(如 2048 维)降维映射到目标参数维度(如 9 维)的 MLP。

坐标 和 预测深度
在初始化阶段,
DPTHead搭建了特征重构和融合所需的各个组件:在
DPTHead中,处理这“多层数据”的核心逻辑是构建特征金字塔并进行自顶向下的多尺度融合。它并没有把所有层的数据一股脑全用上,而是经过了精心的挑选和加工。具体来说,
DPTHead对待这多层数据的处理流程可以分为四个关键步骤:1. 精准抽取与过滤 (Select & Filter)
模型并不需要骨干网络每一层的特征,而是挑选了几个具有代表性的“中间层”。
抽层:通过
intermediate_layer_idx(默认通常是[4, 11, 17, 23]),模型只提取这 4 层的特征。这 4 层分别代表了从浅层(高分辨率纹理)到深层(低分辨率全局语义)的阶梯型信息。过滤特殊 Token:提取出来的特征包含了
camera_token、register_token等辅助 Token。代码通过切片x[:, :, patch_start_idx:]将这些非图像特征剔除,只保留纯粹的图像 Patch 特征。
2. 空间重构与特征金字塔化 (Reshape & Pyramid)
ViT 骨干网络输出的是一维的序列(Sequence),必须将其还原为二维的图像结构。
序列转图像:利用
reshape和permute操作,将一维的 Token 序列重新拼接成二维的特征图形状(B*S, C, patch_h, patch_w)。通道投影 (
projects):通过一组 1x1 的卷积层,将这 4 层特征统一映射到预设的通道维度(例如[256, 512, 1024, 1024])。分辨率调整 (
resize_layers):为了后续能够对齐融合,这 4 层特征经过了不同的卷积/反卷积处理,形成了分辨率由大到小的特征金字塔:浅层特征(第 4 层):使用步长为 4 的反卷积进行大幅放大。
中层特征(第 11 层):使用步长为 2 的反卷积进行中幅放大。
中深特征(第 17 层):保持不变(Identity)。
深层特征(第 23 层):使用步长为 2 的卷积进行缩小。
反卷积

3. 倒序残差融合 (Reverse Residual Fusion /
scratch_forward)这是 DPT 架构的灵魂所在,也是它如何“糅合”这 4 层数据的关键。模型采用的是由深到浅、逐级上采样融合的策略:
第一步:取出最深层(第 23 层,语义最强但分辨率最低)的特征。
第二步:将其上采样(放大尺寸),并与次深层(第 17 层)的特征在
refinenet3(特征融合块)中相加,完成第一次融合。第三步:将融合后的结果再次上采样,与第 11 层的特征在
refinenet2中相加。第四步:重复此过程,直到与最浅层(第 4 层,细节最丰富)的特征在
refinenet1中完成最终融合。
巧妙的内存管理:在代码实现中,每完成一次两层的融合,就会立刻使用
del删掉前置层的特征(例如del layer_4_rn, layer_4),从而在处理多层庞大数据时极限节省 GPU 显存。4. 插值对齐与最终预测 (Interpolate & Predict)
经过彻底融合后的特征图,包含了深层的全局几何理解和浅层的局部边缘细节。
代码最后使用
custom_interpolate(双线性插值)将这张特征图强制放大回原始图像的绝对物理分辨率(H x W)。最后送入
output_conv2,将其压缩成目标维度(如深度图维数为 2,3D 坐标维数为 4),从而输出最终的密集几何预测。
总结来说,
DPTHead将多层数据视作不同层级的“积木”:最底层的积木提供大局观(如整体的房间结构),最高层的积木提供边缘细节(如桌子的轮廓)。通过提取、重构尺寸并逐级相加,完美地融合了这些积木,最终生成了高精度的 3D 重建结果。1
Fast-FoundationStereo
run_demo.py
parser = argparse.ArgumentParser()
parser.add_argument('--model_dir', default=f'{code_dir}/../weights/23-36-37/model_best_bp2_serialize.pth', type=str)
parser.add_argument('--left_file', default=f'{code_dir}/../demo_data/left.png', type=str)
parser.add_argument('--right_file', default=f'{code_dir}/../demo_data/right.png', type=str)
parser.add_argument('--intrinsic_file', default=f'{code_dir}/../demo_data/K.txt', type=str, help='camera intrinsic matrix and baseline file')
parser.add_argument('--out_dir', default='/home/bowen/debug/stereo_output', type=str)
parser.add_argument('--remove_invisible', default=1, type=int)
parser.add_argument('--denoise_cloud', default=0, type=int)
parser.add_argument('--denoise_nb_points', type=int, default=30, help='number of points to consider for radius outlier removal')
parser.add_argument('--denoise_radius', type=float, default=0.03, help='radius to use for outlier removal')
parser.add_argument('--scale', default=1, type=float)
parser.add_argument('--hiera', default=0, type=int)
parser.add_argument('--get_pc', type=int, default=1, help='save point cloud output')
parser.add_argument('--valid_iters', type=int, default=8, help='number of flow-field updates during forward pass')
parser.add_argument('--max_disp', type=int, default=192, help='maximum disparity')
parser.add_argument('--zfar', type=float, default=100, help="max depth to include in point cloud")
args = parser.parse_args()A. 基础输入/输出 (I/O)
--model_dir:预训练权重文件的路径。默认指向的是23-36-37这个模型。--left_file/--right_file:左右双目图像。--intrinsic_file:相机内参和基线(Baseline)。划重点:没有这个文件,模型就只能输出视差(像素单位),没法计算真实的深度(米单位)。--out_dir:保存结果的地方。
B. 算法性能调优 (Performance)
--valid_iters(默认 8):GRU 的迭代次数。次数越多越准,但越慢。--max_disp(默认 192):最大搜索视差。如果物体离镜头极近,需要调大。--scale(默认 1):图像缩放。如果显存不够或者想更快,可以设为 0.5。--hiera:是否开启层级(Hierarchical)推理,通常用于处理高分辨率图像。
C. 点云处理 (Post-processing)
--get_pc:是否生成 3D 点云。--remove_invisible:是否剔除左图看不到(由于遮挡或视场差异)的区域。--denoise_cloud:是否对点云进行去噪。点云由于匹配误差经常会有“毛刺”,开启后会调用 Open3D 进行滤波。--zfar:远端裁剪距离。超过这个深度的点(比如背景里的远山)会被丢弃。
model = torch.load(args.model_dir, map_location='cpu', weights_only=False)
model.args.valid_iters = args.valid_iters
model.args.max_disp = args.max_disp
model.cuda().eval()
scale = args.scalemodel.cuda() 这个方法的作用是将模型的所有参数(weights)和缓冲区(buffers)从系统的内存(CPU)移动到显卡的显存(GPU)中。它的含义: 告诉程序:“接下来的所有矩阵运算,请调用 NVIDIA 显卡的 CUDA 核心来跑,不要用 CPU。”
将模型设置为评估/推理模式。
Batch Normalization (BN):在训练时,BN 使用当前 Batch 的均值和方差;在
eval()模式下,它会固定使用训练期间累计的全局滚动平均值。Dropout:在训练时,它会随机丢弃一部分神经元;在
eval()模式下,它会关闭丢弃行为,让所有神经元都参与计算。
因为 .cuda() 和 .eval() 都会返回模型对象本身,所以你可以像“套娃”一样连着写; 可链式调用
img0 = imageio.imread(args.left_file)
img1 = imageio.imread(args.right_file)
if len(img0.shape)==2:
img0 = np.tile(img0[...,None], (1,1,3))
img1 = np.tile(img1[...,None], (1,1,3))
img0 = img0[...,:3]
img1 = img1[...,:3]
H,W = img0.shape[:2]解释在把图片塞给神经网络之前,必须确保它们的格式、通道数和维度是完全一致的。
1.2 行 , 使用
imageio库将图片文件读入为 NumPy 数组。如果
shape的长度是 2(只有 H 和 W),说明这是一张灰度图。np.tile(img0[..., None], (1, 1, 3))(像 EdgeNext 或 ViT 这样的深度学习骨干网络,通常要求输入必须是 3 通道的(RGB)。即使图片本身没颜色,也要伪造出 3 个通道。)...:前面所有轴原样保留,等价于 img0[:, :](对 2D 就是整幅图)。None,表示「在这里插入一个长度为 1 的新轴」。np.tile(a, reps):把a按reps在每个维度上重复拼接(不是广播成更大形状再算别的,就是沿轴堆叠副本)。
img0[...,:3]怎么读...(省略号)
表示「前面所有轴都取全范围」,等价于在...的位置补上足够多的:。若
img0形状是(H, W, 3),则 img0[...,:3] 等价于 img0[:,:,:3],结果仍是(H, W, 3)(若本来就是 3 通道,相当于不变)。若形状是
(H, W, 4)(例如 RGBA),则等价于img0[:,:,:3],丢掉第 4 通道,得到(H, W, 3)。

img0 = cv2.resize(img0, fx=scale, fy=scale, dsize=None)
img1 = cv2.resize(img1, dsize=(img0.shape[1], img0.shape[0]))
H,W = img0.shape[:2]
img0_ori = img0.copy()
img1_ori = img1.copy()
logging.info(f"img0: {img0.shape}")
imageio.imwrite(f'{args.out_dir}/left.png', img0)
imageio.imwrite(f'{args.out_dir}/right.png', img1)
img0 = torch.as_tensor(img0).cuda().float()[None].permute(0,3,1,2)
img1 = torch.as_tensor(img1).cuda().float()[None].permute(0,3,1,2)
padder = InputPadder(img0.shape, divis_by=32, force_square=False)
img0, img1 = padder.pad(img0, img1)解释尺度缩放 (Resizing)
fx=scale, fy=scale:按照你之前设置的args.scale(比如 0.5)进行等比例缩放。缩放是为了在推理速度和精度之间找平衡。备份原始图:
img0_ori = img0.copy()。这很重要,因为后续计算点云时,需要用这张图的颜色来给点云“上色”。
张量化与格式转换 (To Tensor & Permute)
torch.as_tensor(img0):将 NumPy 数组转换为 PyTorch 张量。.cuda():送入显存。.float():转换成浮点型(神经网络不吃uint8整数)。[None]:增加“批次”(Batch)维度。形状从 (H, W, C) 变成 (1, H, W, C)。.permute(0,3,1,2):最关键的一步。OpenCV 的顺序是 H, W, C(高度、宽度、通道),而 PyTorch 的卷积层要求顺序是 N, C, H, W(批次、通道、高度、宽度)。
边界填充 (Input Padding)
为什么要补齐? 深度学习模型(如 FFS 使用的 EdgeNext)通常包含多次下采样(Pooling/Stride Conv)。如果模型下采样 5 次,那么输入尺寸必须是 25 = 32 的倍数。
举例:如果缩放后的图像是 400 * 300,它不能被 32 整除。
InputPadder会自动计算,将其填充(补黑边或复制边界)到 416 * 320。
logging.info(f"Start forward, 1st time run can be slow due to compilation")
with torch.amp.autocast('cuda', enabled=True, dtype=AMP_DTYPE):
if not args.hiera:
disp = model.forward(img0, img1, iters=args.valid_iters, test_mode=True, optimize_build_volume='pytorch1')
else:
disp = model.run_hierachical(img0, img1, iters=args.valid_iters, test_mode=True, small_ratio=0.5)
logging.info("forward done")
disp = padder.unpad(disp.float())
disp = disp.data.cpu().numpy().reshape(H,W).clip(0, None)混合精度加速
推理策略:常规 vs. 层级
A. 常规模式 (
model.forward)这是标准流程,直接在当前分辨率下进行立体匹配。
iters: 之前提到的 GRU 迭代次数,决定了优化的精细度。test_mode=True: 告诉模型:“我现在是在考试,直接给我最终答案(最后的视差图)就好,不需要把中间过程的草稿纸(中间迭代结果)传回来。”optimize_build_volume: 指定构建成本体积的算法实现。
B. 层级模式 (
model.run_hierachical)这是处理高分辨率图像的利器。
原理:先将图片缩小(
small_ratio=0.5)跑一次,得到一个粗略的深度分布;然后利用这个“粗略答案”作为指引,在原图分辨率下进行精细匹配。优点:能更好地处理巨大的视差(Disparity),提高对大片平滑区域的匹配稳定性。
格式转换
padder.unpad(...): 还记得之前为了凑 32 的倍数补的“黑边”吗?这一步会精准地把它们切掉,恢复到原始的 H*W 尺寸。.float(): 强制转回全精度,避免后续计算出现舍入误差。.cpu().numpy(): 把数据从 GPU 搬回 CPU 内存,并转成我们熟悉的 NumPy 格式。.reshape(H, W): 将形状从 (1, 1, H, W) 压缩为二维的 (H, W) 矩阵。.clip(0, None): 这是一个物理常识过滤。视差(Disparity)不可能是负数,这行代码确保所有负值(通常是模型的一点噪声)都被修正为 0。
cmap = None
min_val = None
max_val = None
vis = vis_disparity(disp, min_val=min_val, max_val=max_val, cmap=cmap, color_map=cv2.COLORMAP_TURBO)
vis = np.concatenate([img0_ori, img1_ori, vis], axis=1)
imageio.imwrite(f'{args.out_dir}/disp_vis.png', vis)
s = 1280/vis.shape[1]
resized_vis = cv2.resize(vis, (int(vis.shape[1]*s), int(vis.shape[0]*s)))
cv2.imshow('disp', resized_vis[:,:,::-1])
cv2.waitKey(0)解释将模型计算出的“冷冰冰”的数值矩阵(视差图)转化成直观的彩色深度图,并将其与原始照片拼在一起显示出来
五维代价体积的 3维卷积 的具体过程
数据的形状:5 维张量 (5D Tensor)

3D 卷积的“立方体”滑动过程

foundation_stereo.py --> "外层" forward()
def forward(self, image1, image2, iters=12, test_mode=False, low_memory=False, init_disp=None, profile=False, optimize_build_volume='pytorch1'):
""" Estimate disparity between pair of frames """
B,C,H,W = image1.shape
low_memory = low_memory or (self.args.get('low_memory', False))
image1 = normalize_image(image1)
image2 = normalize_image(image2)
with torch.amp.autocast('cuda', enabled=self.args.mixed_precision, dtype=U.AMP_DTYPE):
out = self.feature(torch.cat([image1, image2], dim=0))
features_left = [o[:B] for o in out]
features_right = [o[B:] for o in out]
stem_2x = self.stem_2(image1)图像标准化 (
normalize_image)将图像像素值从 [0, 255] 转化到符合 ImageNet 统计分布的范围(通常是均值为 0,方差为 1 左右)
torch.cat([image1, image2], dim=0)
torch.cat(tensors, dim=d):在第 d 维上,把多个张量首尾相接拼成一条更长的轴(其它维尺寸必须一致)。dim=0:在**第 0 维(batch 维)上拼接。(torch.cat([image1, image2], dim=0)→(2B, C, H, W))self.feature(...):把拼好的张量送进同一个特征网络(通常是 ResNet/DINO 等),得到多尺度特征列表。这样做的合理性
左右共用同一套
self.feature、同一组权重:左、右应经过完全相同的编码;拆成两次self.feature(image1)和self.feature(image2)在数学上等价于一次feature(cat([image1, image2], dim=0))再切开(在典型批量归一化推理/固定统计下行为一致;训练时若 BN 依赖 batch 统计,大 batch 会略有差异,但立体匹配里常见做法是共享 backbone,这样写是标准技巧)。
if optimize_build_volume=='pytorch1':
gwc_volume = build_gwc_volume_optimized_pytorch1(features_left[0], features_right[0], self.args.max_disp//4, self.cv_group, normalize=self.args.normalize)
elif optimize_build_volume=='triton':
gwc_volume = build_gwc_volume_triton(features_left[0], features_right[0], self.args.max_disp//4, self.cv_group, normalize=self.args.normalize)
else:
raise RuntimeError(f"Invalid optimize_build_volume: {optimize_build_volume}")
left_tmp = self.proj_cmb(features_left[0])
right_tmp = self.proj_cmb(features_right[0])
concat_volume = build_concat_volume_optimized_pytorch1(left_tmp, right_tmp, maxdisp=self.args.max_disp//4)
del left_tmp, right_tmp
comb_volume = torch.cat([gwc_volume, concat_volume], dim=1)
del concat_volume, gwc_volume解释构建代价空间(Cost Volume)
构建 GWC 体积 (分组相关性 - 算相似度)
GWC (Group-wise Correlation) 是一种计算左右图特征“内积”的方法。它把特征通道分成几组(
cv_group),然后在每个给定的视差(d ∈ [0,max_disp//4])下,计算左图和右图特征的相似度。数值越大,说明越匹配。为什么是
max_disp//4? 因为输入的特征图 features_left[0] 分辨率已经是原图的 1/4(这一缩放是在 self.feature(Feature.forward)里完成的),所以搜索范围也要相应缩小到 1/4
构建 Concat 体积 (特征拼接 - 存全局语义)
self.proj_cmb
为什么需要这一层?
d_out[0] 较大:直接用它建 concat volume 会让 3D 卷积(
corr_stem等) 的输入通道变胖,需对特征进行降维/压缩。1×1 投影:把参与 concat 分支 的特征压到固定 12 维,使 concat 代价体固定为 24 通道,和网络其它超参(如
volume_dim、corr_stem)对齐。
定义 self.proj_cmb = nn.Conv2d(self.feature.d_out[0], self.concat_channel//2, kernel_size=1, padding=0)
类型:1×1 卷积(nn.Conv2d,kernel_size=1),只做逐像素线性变换
输入通道:self.feature.d_out[0],即 Feature 输出的第一档特征 features_*[0] 的通道数(EdgeNeXt+FPN 里最“细”、分辨率最高的那层,约为 1/4 尺度(通道数最多))
输出通道:
self.concat_channel // 2= 24 // 2 = 12。左右 共用同一个 proj_cmb,保证左右特征在同一低维空间里
concat_volume = build_concat_volume_optimized_pytorch1(left_tmp, right_tmp, maxdisp=self.args.max_disp//4)
为什么要用 Concat? GWC 算的是“相对相似度”,这会导致一个问题:两个全黑的像素(比如阴影),它们算出来的相似度也很高。模型会犯迷糊。
输入是 已对齐 的左右特征(本项目里
proj_cmb之后的 1/4 尺度):refimg_fea:(参考)图特征(B, C, H, W)

comb_volume = torch.cat([gwc_volume, concat_volume], dim=1)
将“算相似度”的 GWC 体积和“存语义”的 Concat 体积在通道维度(
dim=1)合并,形成一个终极的 组合成本体积 (comb_volume)。这让模型既具备精确的局部匹配能力,又具备全局的语义推理能力
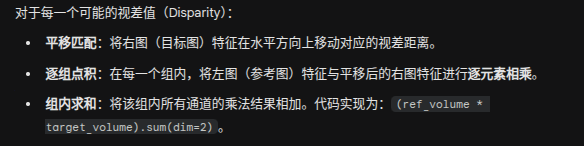
信息融合、降维压缩和初步去噪
comb_volume = self.corr_stem(comb_volume)其中,定义为
self.corr_stem = nn.Sequential(
nn.Conv3d(self.proj_cmb.out_channels*2+self.cv_group, volume_dim, kernel_size=1),
BasicConv(volume_dim, volume_dim, kernel_size=3, padding=1, is_3d=True),
ResnetBasicBlock3D(volume_dim, volume_dim, kernel_size=3, stride=1, padding=1),
ResnetBasicBlock3D(volume_dim, volume_dim, kernel_size=3, stride=1, padding=1),
)corr_stem的任务就是对这个巨大的 4D 张量(通道、视差、高度、宽度)进行信息融合、降维压缩和初步去噪nn.Conv3d
proj_cmb.out_channels*2:这是左图特征和右图特征拼接(Concat)后的通道数kernel_size=1的作用:在 3D 空间中,1x1x1 卷积不改变空间和视差的分辨率,它的唯一作用是跨通道混合信息。它把相似度分数(GWC)和语义特征(Concat)揉捏在一起。降维 (
volume_dim):3D 卷积极其消耗显存!这里强行把臃肿的输入通道数压缩到一个固定的、较小的值(volume_dim,通常在 Fast 架构中是 28 或 32)。这不仅提取了精华,还是 FFS 能实现实时推理的核心显存优化手段。、
BasicConv(volume_dim, volume_dim, kernel_size=3, padding=1, is_3d=True)
3D 视野:它在 (H, W, Disparity) 三个维度上同时滑动一个 3x3x3 的立方体窗口(一共有五维 B, H, W, C, D)。
在 H 和 W 维度上,它能平滑图像的噪点。
在 Disparity 维度上,它能平滑匹配概率。如果视差为 10 的概率很高,那么它会“顺便”让视差为 9 和 11 的概率也稍微提高,让深度分布变得连续。
图像特征引导的注意力机制(Feature-Guided Attention)
comb_volume = self.corr_feature_att(comb_volume, features_left[0])这句代码
comb_volume = self.corr_feature_att(comb_volume, features_left[0])是立体匹配算法中一个非常经典且极其有效的设计,被称为 “图像特征引导的注意力机制(Feature-Guided Attention)”。在经历上一层
corr_stem的 3D 卷积处理后,comb_volume已经是一个包含了丰富匹配信息的 4D 空间,但它有一个致命的弱点:它容易“忘本”。在构建这个 3D 空间时,原始图像的结构信息(哪里是边缘,哪里是平滑的墙面)被淡化了。这句代码的任务,就是把左图(参考图)的 2D 图像特征作为“向导”,重新注入到 3D 匹配空间中。
类定义
class FeatureAtt(nn.Module):
def __init__(self, cv_chan, feat_chan):
super(FeatureAtt, self).__init__()
self.feat_att = nn.Sequential(
BasicConv(feat_chan, feat_chan//2, kernel_size=1, stride=1, padding=0),
nn.Conv2d(feat_chan//2, cv_chan, 1)
)
def forward(self, cv, feat):
'''
@cv: cost volume (B,C,D,H,W)
@feat: (B,C,H,W)
'''
feat_att = self.feat_att(feat).unsqueeze(2) #(B,C,1,H,W)
cv = torch.sigmoid(feat_att)*cv
return cv在 PyTorch 里,tensor.unsqueeze(dim) 表示:在维度下标 dim 的位置插入一个长度为 1 的新轴,不改变实际数据,只改「形状怎么解释」。
输入
feat:也就是传入的features_left[0]。它是骨干网络提取的左图 1/4 分辨率特征图(未做代价体积的原图)(包含形状、纹理、颜色分布等信息),形状是(B, C_feat, H, W)。降维映射:通过两个 1x1 卷积(先压缩到一半通道,再映射到和代价体积一样的通道数
cv_chan),网络从左图中提取出一张 “注意力权重图”。此时它的形状是(B, C_cv, H, W)。广播(Broadcasting):在随后的乘法中,这个权重图会沿着
D维度复制(广播)。意思是:对于左图上的某一个像素 (H, W),无论它在右图的哪个视差 D 位置进行匹配,都共享同一个注意力权重。
Sigmoid激活:把刚才算出来的注意力权重压缩到0 到 1之间。相当于生成了一张“滤网”。
* cv(逐元素相乘):将滤网盖在庞大的 3D 代价体积上。
代价聚合(Cost Aggregation)
comb_volume = self.cost_agg(comb_volume, features_left)在立体匹配中,这一步被称为代价聚合(Cost Aggregation)。它使用的是一个经典的 3D 沙漏网络(Hourglass / U-Net 架构)。
如果说前面的代码是“在局部找相似”,那么这段代码的任务就是“联系全局上下文,修正局部错误”。比如:一面纯白的墙,局部看哪里都一样(匹配概率乱七八糟),沙漏网络通过“看大局”,依靠墙边缘的深度,把整面墙的深度推导出来。
def forward(self, x, features):
conv1 = self.conv1(x)
conv1 = self.feature_att_8(conv1, features[1])
conv2 = self.conv2(conv1)
conv2 = self.feature_att_16(conv2, features[2])
conv3 = self.conv3(conv2)
conv3 = self.feature_att_32(conv3, features[3])
if not hasattr(self, 'post32_to_16') or self.post32_to_16 is None:
conv3_up = self.conv3_up(conv3)
conv2 = torch.cat((conv3_up, conv2), dim=1)
conv2 = self.agg_0(conv2)
conv2 = self.feature_att_up_16(conv2, features[2])
else:
conv2 = self.post32_to_16(conv2, conv3, features[2])
if not hasattr(self, 'post16_to_8') or self.post16_to_8 is None:
conv2_up = self.conv2_up(conv2)
conv1 = torch.cat((conv2_up, conv1), dim=1)
conv1 = self.agg_1(conv1)
conv1 = self.feature_att_up_8(conv1, features[1])
else:
conv1 = self.post16_to_8(conv1, conv2, features[1])
conv = self.conv1_up(conv1)
if not hasattr(self, 'post8_to_4') or self.post8_to_4 is None:
x = self.conv_patch(x)
x = self.atts["4"](x)
x = F.interpolate(x, scale_factor=4, mode='trilinear', align_corners=False)
conv = conv + x
conv = self.conv_out(conv)
else:
conv = self.post8_to_4(x, conv)
return conv
A. 下采样(Encoder:获取全局视野)
输入的
comb_volume是 1/4 原图分辨率。conv1-->conv2-->conv3:利用stride=2的 3D 卷积,将空间分辨率依次压缩到 1/8、1/16、1/32。物理意义:随着分辨率越来越小,网络“一眼”能看到的实际图像范围越来越大(感受野变大)。在 1/32 的极小分辨率下,网络能理解诸如“这是一整块天空”或“这是一辆完整的车”这样的全局语义,从而解决大面积无纹理区域的匹配难题。
分辨率是什么?
数字图像是由无数个色彩点组成的方阵,这些点被称为“像素”。当你改变分辨率时,你最直接改变的是这个方阵的行数和列数。
改变分辨率并不是简单的“变大变小”,而是一个数学计算过程。当你强制改变分辨率时,计算机会面临以下问题:
缩小图像: 必须丢弃一部分像素。为了不让图像失真,计算机会对邻近像素进行加权平均。
放大图像: 需要“凭空”创造出原本不存在的像素。
B. 上采样与跳跃连接(Decoder:恢复高清边缘)
conv3_up-->conv2_up-->conv1_up:利用 3D 反卷积(Deconv),把分辨率一步步从 1/32 还原回 1/4。torch.cat(跳跃连接):在还原的过程中,如果只用极度压缩的信息,物体的边缘会糊成一团。因此,代码使用了经典的 U-Net 技巧:比如把反卷积得到的 1/16 特征,和下采样时保留下来的 1/16 原汁原味特征(conv2)拼接在一起,再通过agg_0融合。这保证了既有全局大局观,又有局部清晰度。内部经典操作:先 kernel_size = 1 融合 通道C,然后 经过 三维卷积,视差上的跨度尤其大 (kernel_disp=17)
FFS 优化细节
在普通的模型里,图像特征只在最开始注入一次。但在 FFS 的沙漏网络里 它在每一个分辨率层级(1/8, 1/16, 1/32),无论是下楼还是上楼,都把对应分辨率的左图 2D 特征(
features[1], features[2], features[3])拿过来相乘过滤一遍!conv1 = self.feature_att_8(conv1, features[1]) conv2 = self.feature_att_16(conv2, features[2]) conv3 = self.feature_att_32(conv3, features[3]) ... conv2 = self.feature_att_up_16(conv2, features[2])
非对称卷积减负 (Conv3dNormActReduced)
传统的 3D 卷积在处理代价体积(Cost Volume)时极其缓慢,因为它需要同时在三个维度(视差 D、高度 H、宽度 W)上滑动机法。
Conv3dNormActReduced的核心思想是 “空间与视差的因子分解(Factorization)”def forward(self, x): # x 形状: (B, C, D, H, W) x = self.conv1(x) # 负责平面 H, W x = self.conv2(x) # 负责纵深 D return x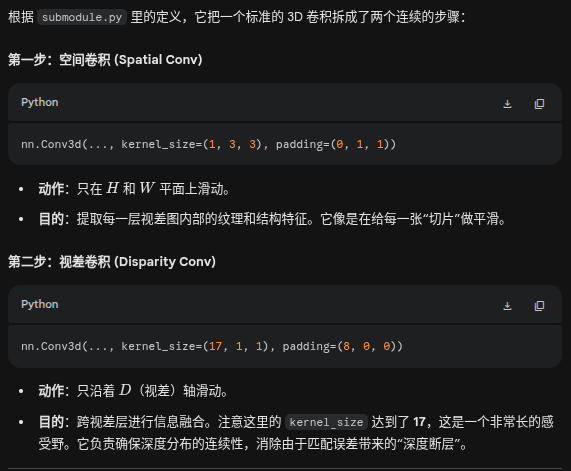
深度在物理世界中通常是连续变化的。长卷积实际上是在 D 轴上施加了一个平滑先验。
抗噪: 17 个位置的上下文信息被强制融合。这意味着某个位置想要成为“赢家”,不仅自己概率要高,还得看周围兄弟节点的支持。
抹掉假峰: 孤立的噪声峰值因为缺乏周围权重的支持,在经过这种长距离的加权平均后,会被周围的低概率值“稀释”掉。
视差 Transformer 旁路
conv = self.conv1_up(conv1) if not hasattr(self, 'post8_to_4') or self.post8_to_4 is None: x = self.conv_patch(x) x = self.atts["4"](x) x = F.interpolate(x, scale_factor=4, mode='trilinear', align_corners=False) conv = conv + x conv = self.conv_out(conv) else: conv = self.post8_to_4(x, conv)self.conv_patch = nn.Sequential( nn.Conv3d(in_channels, in_channels, kernel_size=4, stride=4, padding=0, groups=in_channels), nn.BatchNorm3d(in_channels), )self.atts = nn.ModuleDict({ "4": CostVolumeDisparityAttention(d_model=in_channels, nhead=4, dim_feedforward=in_channels, norm_first=False, num_transformer=4, max_len=self.cfg['max_disp']//16), })在代码实现中,
hourglass的主线任务是通过一系列 3D 反卷积(conv1_up,conv2_up等)将压缩的特征还原。“旁路”逻辑如下:
输入分流:它直接取沙漏网络的输入
x(即原始的 1/4 分辨率代价体积)。并行处理:它不经过复杂的沙漏下采样/上采样,而是通过一个轻量级的 conv_patch 快速下采样,然后进入
CostVolumeDisparityAttention(视差注意力模块)。ormer 只在这个维度上结果融合:处理完的结果经过插值还原后,直接通过
conv = conv + x加回到主线特征中。
这就像在主干道旁边修了一条高架快车道,专门处理主干道(卷积层)处理不好的特殊信息。
核心机制:针对“视差轴”的注意力

为什么要专门处理“视差轴”?
在复杂的场景下(如重复纹理、半透明物体、细小前景),代价值在 D 轴上往往会出现多个峰值。
卷积的局限:3D 卷积只能通过局部的加权平均来平滑峰值,容易被错误的强假峰(False Positive)带偏。
Transformer 的优势:它具有全局感受野。通过注意力机制,它能分析整个视差概率分布的形状。如果它发现远处的视差分布更符合全局几何逻辑,它可以利用注意力权重直接加强远处的真正峰值,并抑制近处的假峰。
for i in range(len(self.sa)): x = self.sa[i](x, window_size=window_size)自注意力(Self-Attention):在这个像素的深度轴上,视差 10 处的特征会去“观察”视差 50、视差 100 处的特征。 (空间维度 (H, W) 和批次 B 合并了)
解决多峰歧义:在面对重复纹理(比如一排长得一模一样的栅栏)或透明反光物体时,代价体积在 D 轴上往往会算出好几个高分(假峰值)。3D 卷积由于视野有限(只看周围几个点),很容易选错。
降维打击:Transformer 拥有全局感受野。它能一次性统观所有视差的得分分布,结合自身的 C 通道语义,瞬间判断出:“虽然视差 50 和 100 得分都很高,但根据全局语义逻辑,视差 50 才是真身,100 是玻璃反光产生的倒影”。于是,它会通过注意力权重,狠狠地压制视差 100 的得分,提拔视差 50。
对于官方的 nn.Transformer ,输入为 (N, L, C);
N(Batch/独立样本数):这部分数据是完全平行、互不干扰的,L(Sequence Length/序列长度):Transformer 只在这个维度上计算注意力(互相观察)。所以这里 B * H * W 是独立的
为什么要加上 BatchNorm?
nn.BatchNorm3d(C) 的实现原理

为什么 conv_patch 需要加 BatchNorm?
A. 为 Transformer 准备“标准化”输入
conv_patch之后紧接着就是CostVolumeDisparityAttention(基于 Transformer 的自注意力模块)。注意力敏感性:Transformer 内部的
Softmax函数对输入数值的绝对大小非常敏感。如果输入值过大,Softmax会进入饱和区,导致梯度消失。标准化作用:BN 确保了送入 Transformer 的“Token”特征分布稳定,使得注意力权重的计算更加平滑且有效
B. 沙漏主路(
conv)经过了多层BasicConv处理,每一层内部通常都带有 BN。逻辑一致性:为了让两路特征在相加(Element-wise sum)时不会因为量级差异太大(例如一路是 1.0 左右,另一路是 100.0 左右)而导致其中一路被“淹没”,旁路也必须使用 BN 来保证两者的特征分布处于相似的统计区间。
为什么 BasicConv 中也要加 BatchNorm?
痛点:在训练时,前一层权重的微小更新,会导致输出的数据分布发生变化。这种变化经过几十层网络的传递和放大,会让后面的网络层无所适从,导致训练极度不稳定。
BN 的作用:它像一个“稳压器”,强行把每一次卷积输出的特征分布拉回到均值为 0,方差为 1 的标准状态。这确保了无论网络多深,每一层接收到的数据都是可预期的,从而防止了梯度的消失或爆炸。
转化 2D 视差图
logits = self.classifier(comb_volume).squeeze(1)
prob = F.softmax(logits, dim=1)
if init_disp is None:
init_disp = disparity_regression(prob, self.args.max_disp//4) 解释self.classifier
self.classifier = nn.Sequential( BasicConv(volume_dim, volume_dim//2, kernel_size=3, padding=1, is_3d=True), ResnetBasicBlock3D(volume_dim//2, volume_dim//2, kernel_size=3, stride=1, padding=1), nn.Conv3d(volume_dim//2, 1, kernel_size=7, padding=3), )先将通道数降维到一半,再经过残差块
最后经过 Conv3d, 其通道数变为 1, 给出一个具体的打分;用巨大的
kernel_size=7
在视差维度(
dim=1,即 D 轴)上应用 Softmax 函数。disparity_regression

效果:假设视差 10 的概率是 0.6,视差 11 的概率是 0.4。如果是硬取最大,视差就是 10。但在 Soft-Argmax 下,视差会是 10 0.6 + 11 0.4 = 10.4。
视差微调(Refinement)
cnet_list = self.cnet(features_left[0], features_left[1], features_left[2])
cnet_list = list(cnet_list)
net_list = [torch.tanh(x[0]) for x in cnet_list]
inp_list = [torch.relu(x[1]) for x in cnet_list]
inp_list = [self.cam(x) * x for x in inp_list]
att = [self.sam(x) for x in inp_list]cnet
self.cnet = ContextNetSharedBackbone(args, c04=self.feature.d_out[0], c08=self.feature.d_out[1], c16=self.feature.d_out[2], output_dim=[args.hidden_dims, context_dims])class ContextNetSharedBackbone(nn.Module): def __init__(self, args, c04, c08, c16, output_dim=[(128,128,128), (128,128,128)], norm_fn='batch', downsample=3): super().__init__() self.args = args self.conv04 = nn.ModuleList([ nn.Conv2d(c04, output_dim[0][0], kernel_size=3, padding=1), nn.Conv2d(c04, output_dim[1][0], kernel_size=3, padding=1), ]) def forward(self, x4, x8, x16): outputs04 = [] for i in range(len(self.conv04)): outputs04.append(self.conv04[i](x4)) return (outputs04,)这是这段代码的核心。它包含了两个并行的 3 * 3 卷积层。它们都接收 1/4 分辨率的特征(
c04),但输出不同的维度:第一个卷积 (
output_dim[0][0]):负责生成 GRU 的初始隐藏状态(Hidden State)。对应之前参数args.hidden_dims。第二个卷积 (
output_dim[1][0]):负责生成 GRU 的上下文输入(Context Feature)。对应之前参数context_dimshidden_dims 是配置里的一个 列表/元组,表示 迭代更新视差(GRU / update_block 一路)里「隐状态」在各层的通道宽度
context_dims:本质就是 args.hidden_dims 的别名
(第一个卷积被训练成了“记忆提取器”,第二个卷积被训练成了“当前线索提取器”。)
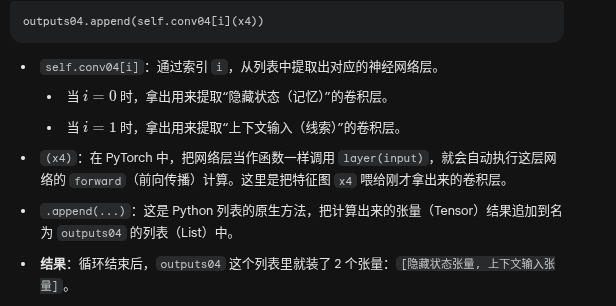
加上逗号后,再加上(), 返回一个元组
net_list = [torch.tanh(x[0]) for x in cnet_list]
提取 x[0], 即给即将上场的 GRU 准备的初始隐藏状态(Hidden State)
torch.tanh
双曲正切函数的数学公式如下:
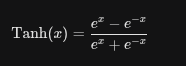
具有以下三个极其关键的特性:
严格的边界 [-1, 1]:无论输入的数值有多极端(比如输入 10000),输出也只会被无限压缩逼近 1;如果输入 -10000,输出就无限逼近 -1。
零中心化(Zero-centered):当输入 x = 0 时,输出 y = 0。并且它在原点附近是高度对称的(中心对称的奇函数)。
非线性变形:在靠近 0 的区域(大约 [-2, 2]),它近似于一条直线(线性),这意味着特征能原汁原味地传递
在此使用,可以 避免梯度爆炸

BN 不能放在循环神经网络中 。 在 GRU 中,第 1 次迭代的记忆分布和第 15 次迭代的记忆分布是截然不同的。 如果你为所有迭代步骤共享同一个均值和方差,这在数学上是完全错误的,因为记忆在不断演化。
可以用layernorm,都能在不污染他人记忆的前提下,稳定自身的数值分布. 但这里为了效率,直接用 函数映射了
线性整流函数(Rectified Linear Unit)
通道注意力机制(Channel Attention Mechanism)
inp_list = [self.cam(x) * x for x in inp_list]self.cam(x)的任务是输出一个 (B, C, 1, 1) 的权重向量,也就是给每一个特征通道打一个 0 到 1 之间的分数. 然后将 inp_list 乘以权重
空间注意力机制(Spatial Attention Mechanism)
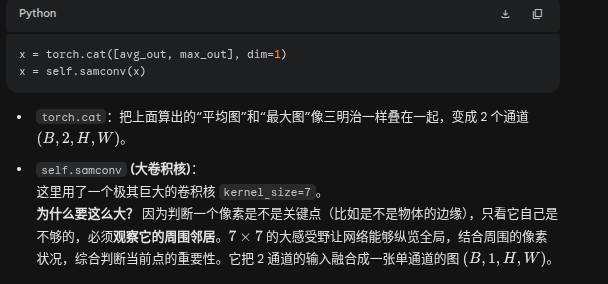
avg_out = torch.mean(x, dim=1, keepdim=True) max_out, _ = torch.max(x, dim=1, keepdim=True)动作:在通道维度 (
dim=1) 上进行操作。对于图像上的任意一个坐标点 (h, w),它背后本来有 C 个特征数值。torch.mean(平均值):把这 C 个数值加起来求平均。物理意义:计算这个像素点上“所有特征激活的平均强度”。torch.max(最大值):找出这 C 个数值里最大的那个。物理意义:寻找这个像素点上“最强烈的单一显著性特征”。结果:原本厚厚的特征张量 (B, C, H, W),被无情地拍扁成了两张单通道的灰度图 (B, 1, H, W)。
拼接与大视野审视 (7 * 7 卷积)
return self.sigmoid(x)
通过
Sigmoid函数,把卷积出来的数值强行压缩到 0 到 1 之间。最终产出:一张黑白分明的 2D 空间热力图(Heatmap)。数值越接近 1(越亮),代表这个像素点在立体匹配中越关键、越容易出错(比如复杂的遮挡边缘、树叶交错处);数值越接近 0(越暗),代表这个区域越平坦简单(比如一大片纯白色的墙)
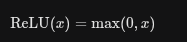
准备 GRU 迭代微调
geo_fn = Combined_Geo_Encoding_Volume(features_left[0].to(self.dtype), features_right[0].to(self.dtype), comb_volume.to(self.dtype), num_levels=self.args.corr_levels)
b, c, h, w = features_left[0].shape
coords = torch.arange(w, dtype=torch.float, device=init_disp.device).reshape(1,1,w,1).repeat(b, h, 1, 1)
disp = init_disp.to(self.dtype)
disp_preds = []Combined_Geo_Encoding_Volume: 将左图特征、右图特征以及之前辛苦算好的代价体积(
comb_volume)打包,构建一个geo_fn(几何编码体积函数)在初始化伊始,它会调用静态方法
corr处理左右图的初始特征图(init_fmap1和init_fmap2):全对相关性计算:利用torch.einsum计算左图每个像素与右图同水平线上所有像素的内积。结果形状:生成的init_corr形状为 (B, H, W1, 1, W2),代表了原始的、未经神经网络进一步加工的几何匹配强度。处理原始相关性矩阵:将
init_corr变形为 (B* H * W, 1, 1, W2); 将输入的geo_volume(形状为 (B, C, D, H, W))重排并变形为 (B * H * W, C [init = 1], 1, D)。self.geo_volume_pyramid.append(geo_volume) self.init_corr_pyramid.append(init_corr) for _ in range(self.num_levels-1): geo_volume = F.avg_pool2d(geo_volume, [1,2], stride=[1,2]) self.geo_volume_pyramid.append(geo_volume) for _ in range(self.num_levels-1): init_corr = F.avg_pool2d(init_corr, [1,2], stride=[1,2]) self.init_corr_pyramid.append(init_corr)标准的 2D 池化接收的格式是
(Batch, Channels, Height, Width)。当我们对形状为(N, C, 1, D)的张量应用F.avg_pool2d(..., [1,2], stride=[1,2])时,在 Height (高度) 维度上:核大小是1,步长也是1。因为高度本身就是 1,所以它在这个维度上什么都没做。在 Width (视差 D) 维度上:核大小是2,步长也是2。这意味着它会两两一组,且不重叠地框住相邻的数据。
获取当前工作分辨率(通常是原图的 1/4)下的批次大小 b、通道数 c、高度 h 和宽度 w。
构建基准 X 坐标网格
torch.arange(w):生成一个从 0 到 w-1 的数列(比如 0, 1, 2... 79)。.reshape(1,1,w,1)和.repeat(b, h, 1, 1):把这根一维的线,沿着高度方向(h)和批次方向(b)复制,铺满整个屏幕。最终得到形状为
(b, h, w, 1)的张量。对于图像上的任意一点 (y, x),这个张量里存的值就是它的绝对横坐标 x。
将上一阶段 Soft-Argmax 算出来的初稿视差图(
init_disp),正式赋值给工作变量disp。初始化一个空列表。物理意义(深层监督):在接下来的每一次 GRU 循环(比如迭代 12 次)结束后,都会把当前更新好的
disp存进这个列表里在训练阶段,模型不会只拿着最后一次的结果去算误差(Loss),而是会把这 12 次所有的中间结果都拿去和真实深度图(Ground Truth)算误差,这被称为深层监督(Deep Supervision)。它能迫使网络在初期的几次迭代中就快速向正确答案靠拢,大幅加速模型收敛,并防止梯度消失
ConvGRU
门控
如果没有门控,神经网络就像一个没有记忆滤网的漏斗,旧的信息很快会被新信息冲刷掉(这就是 RNN 梯度消失的原因)。
门控机制通常由两个部分组成:一个 Sigmoid 函数 和 一个逐元素乘法
在具体的模型里,这些“门”各司其职
遗忘门/重置门(Forget/Reset Gate): “断舍离”。决定哪些旧的垃圾记忆该扔掉了。
更新门/输入门(Update/Input Gate): “记笔记”。决定哪些新的信息值得被存入大脑。
输出门(Output Gate): “深思熟虑”。决定当前大脑里的所有信息,哪些应该拿出来作为当前的结论。
门控机制的出现,本质上是为了解决长程依赖问题。
在传统的神经网络中,信息传递是一层压一层,传递路径越长,梯度就越容易在连乘中变成 0(梯度消失)。门控机制通过“加法更新”而非单纯的“乘法堆叠”,为梯度提供了一条“高速公路”,使得模型能够学习到几百甚至上千个时间步之前的关键信息。

重置门
重置门 rt 的计算方式与其它门类似,都是基于当前输入 xt 和上一个时刻的隐藏状态 ht-1
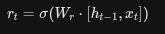
ht-1 表示上一时刻的隐藏状态,xt 表示现在输入给模型的数据,Wr 是可学习的权重矩阵,矩阵乘法,它将高维的输入映射到一个特征空间,算出每一个记忆维度的“相关性得分”。
Sigmoid 函数,它的唯一任务是把计算结果压缩到 (0, 1) 之间 ; 结果趋近于 1:代表“完全保留”,门是大开的。结果趋近于 0:代表“完全抹除”,门是关闭的
rt 是一个与隐藏状态维度相同的向量,是一个信号 . 如果你看到 rt 接近 0:说明模型认为之前的记忆ht-1 跟当前的任务没关系,直接“重置”掉,


重置门最关键的一步发生在计算 候选隐藏状态 的时候。公式如下
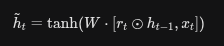

更新门

GRU

ConvGRU
为什么要从 GRU 升级到 ConvGRU?
在标准的 GRU 中,输入 Xt 和隐藏状态 Ht-1 必须被拉平成一维向量。
后果: 图像中像素与像素之间的空间位置关系(比如左边和右边是相连的)被彻底破坏了。
ConvGRU 的对策: 保持输入是三维张量 (Channels, Height, Width),用一个滑动窗口(卷积核)去扫描。这样,模型在记住时间的同时,也能记住物体的形状和位置。

迭代微调循环(Refinement Loop)
for itr in range(iters):
disp = disp.detach()
geo_feat = geo_fn(disp, coords, dx=self.dx, low_memory=low_memory)
with torch.amp.autocast('cuda', enabled=self.args.mixed_precision, dtype=U.AMP_DTYPE):
net_list, mask_feat_4, delta_disp = self.update_block(net_list, inp_list, geo_feat.to(self.dtype), disp, att)
disp = disp + delta_disp.to(self.dtype)
if test_mode and itr < iters-1:
continue
# upsample predictions
disp_up = self.upsample_disp(disp.to(self.dtype), mask_feat_4.to(self.dtype), stem_2x.to(self.dtype))
disp_preds.append(disp_up)
geo_fn
在 Python 中,并不是只有函数(
function)才能加括号运行。如果一个类定义了__call__方法,那么这个类的实例就会变成一个可调用对象。当你写下
obj(args)时,Python 解释器在底层会自动将其转化为obj.__call__(args)。def __call__(self, disp, coords, dx, low_memory=True): b, _, h, w = disp.shape out_pyramid = [] for i in range(self.num_levels): with torch.profiler.record_function(f"make disp_lvl {i}"): geo_volume = self.geo_volume_pyramid[i] x0 = dx + disp.view(b*h*w, 1, 1, 1) / 2**i获取当前视差图
disp的尺寸。遍历之前在
__init__中准备好的几何特征金字塔。 粗对齐 + 精对齐(这里 self.geo_volume_pyramid 是根据comb_volume这个聚合完的特征 制作的 金字塔 )
(disp是 将 c 归一化,然后对不同视差评分加权平均(d化为1)的结果) (这时候数值的意思不是C,而是视差应该是多少)
(dx = torch.arange(-r, r+1, requires_grad=False, dtype=torch.int8).reshape(1, 1, 2*r+1, 1))
with torch.profiler.record_function(f"bilinear_sampler geo_volume {i}"): if low_memory: geo_volume = bilinear_sampler1d(geo_volume, x0, mode='bilinear', align_corners=True) else: y0 = torch.zeros_like(x0) disp_lvl = torch.cat([x0,y0], dim=-1) geo_volume = bilinear_sampler(geo_volume, disp_lvl, low_memory=low_memory) geo_volume = geo_volume.view(b, h, w, -1) #(b, h, h, 3x3xC)神经网络生成的代价体积(Cost Volume)是离散的像素点,但 GRU 预测的视差(Disparity)通常是连续的浮点数(例如 10.42)。
bilinear_sampler的任务就是:当你给出一个不落在整数坐标上的视差值时,通过“四点取样”帮你算出一个合理的、平滑的特征值(算一个 猜出来的C)在
geo_volume这一行数据中,10.4 并不是一个真实存在的索引。bilinear_sampler会立刻锁定它周围最靠近的整数索引提供梯度 (Gradient Flow): 这是最关键的一点。如果直接“取整”采样(Nearest Neighbor),函数是阶跃的,导数为 0,模型没法训练。 双线性采样是线性可导的。 当 GRU 微调视差时,采样出的
geo_feat会随之发生连续变化。这让 Loss 产生的梯度能顺着这条“线性电缆”反向传播,告诉 GRU 应该往哪个方向继续修正。
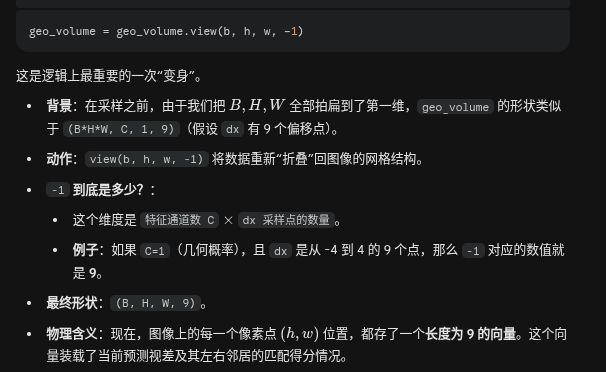
geo_volume = bilinear_sampler(geo_volume, disp_lvl, low_memory=low_memory) 的 意思是 用 disp_lvl 这个 左图中每个像素对应的深度值{D}以及其余 dx 个 在 {D}上做偏移的 一系列 {D+x1, D+x2....} , 作为索引,去插值好的 geo_volume 中取出 匹配特征值
with torch.profiler.record_function(f"make init_coords_lvl {i}"): init_corr = self.init_corr_pyramid[i] # (B*H*W, 1, 1, W2) init_x0 = coords.view(b*h*w, 1, 1, 1)/2**i - disp.view(b*h*w, 1, 1, 1) / 2**i + dx # X on right image变量解释
coords(绝对横坐标) , 代表了左图像素的原始物理位置 (x_left)。在代码中,它是由torch.arange(w)生成并铺满全图的,表示图像中每一个点在水平方向上的绝对索引。dx(局部偏移量):它代表了以预测点为中心的搜索窗口半径。它是一个相对位移向量(例如[-4, -3, ..., 0, ..., 4]),用于在当前预测值附近进行微调探测。此时 将 init_corr 形状 为 (B* H * W, 1, 1, W2). 是全对相关性矩阵(All-pairs Correlation), 即同一个高度上两张图片的每一个像素都会做运算.
coords - disp的结果就是该左图像素点在右图中对应的预测横坐标。+ dx:局部搜索偏移。
这让
init_x0不仅仅指向右图的一个点,而是指向以预测点为中心的 9 个邻居点。
. 为什么要用
coords - disp?(对比geo_volume)这是理解这段代码最难的一点:
对于
geo_volume:它的维度本身就是“视差轴”。你只需要告诉它“我要看视差为 10 的地方”,所以采样坐标只需要disp + dx。对于
init_corr:它是全对相关性矩阵(All-pairs Correlation)。它的最后一个维度 W_2 代表的是右图的列索引。如果你想知道某个视差下的匹配好不好,你必须亲自算出这个视差对应右图的哪个位置(即 x_left - d),然后去右图那个位置“抠”特征。
out_pyramid.append(geo_volume) out_pyramid.append(init_corr) with torch.profiler.record_function(f"make out_pyramid"): out_pyramid = torch.cat(out_pyramid, dim=-1) return out_pyramid.permute(0, 3, 1, 2) #(B,C,H,W)在
for循环内部,每一层级采样出的geo_volume和init_corr都会被存入out_pyramid列表动作:将列表中所有的张量沿着最后一个维度(通道维度)拼接起来。
维度计算:
每个采样结果的形状是 (B, H, W, 9)(假设采样半径 r=4,即
dx有 9 个点)。如果
num_levels=2,拼接后的总通道数就是:9 (geo0) + 9 (corr0) + 9 (geo1}) + 9 (corr1}) = 36。


with torch.amp.autocast('cuda', enabled=self.args.mixed_precision, dtype=U.AMP_DTYPE): net_list, mask_feat_4, delta_disp = self.update_block(net_list, inp_list, geo_feat.to(self.dtype), disp, att)self.update_block(通常是一个 ConvGRU)
GRU 全过程
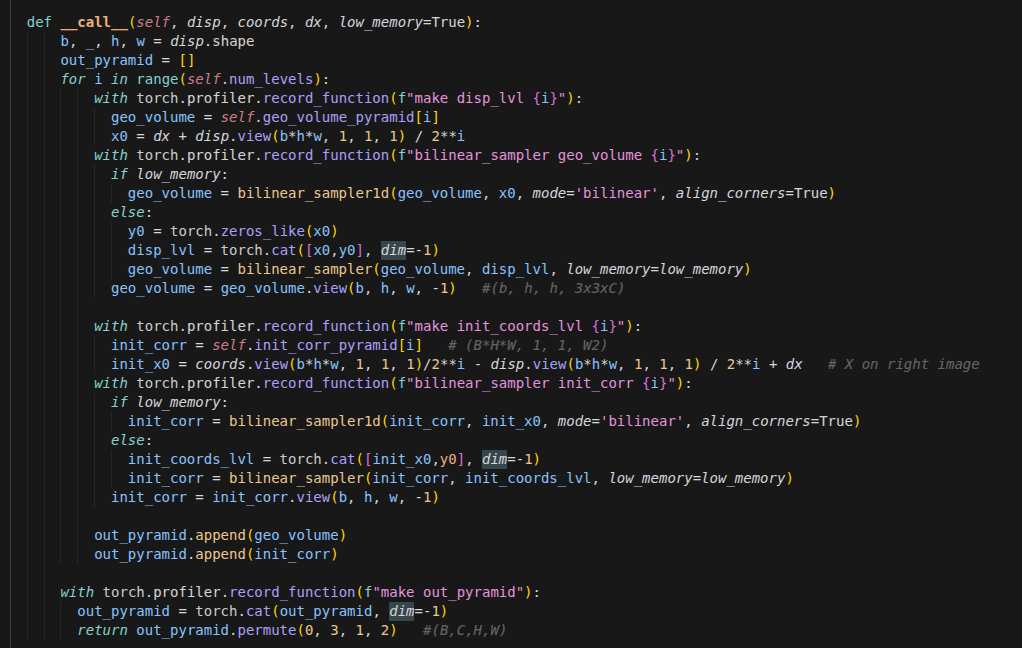
geometry.py (line 33)
这段 call 的作用,可以一句话概括成:
给当前这一步的 disp,在多尺度上提取“围绕当前匹配位置的一小段局部证据”,然后拼成一个 (B,C,H,W) 的特征图,喂给后面的 GRU 做下一次 disparity 更新。
它在取什么
这个类在 init 里提前准备了两类金字塔:
self.geo_volume_pyramid
这是从 cost/geometry volume 来的,shape 本质上是每个像素对应一条“沿 disparity 轴的特征曲线”。self.init_corr_pyramid
这是 left-right 的 all-pairs correlation,本质上是每个左图像素,对右图所有 x 位置的相关性曲线。所以 call 并不是重新算 volume,而是:
拿当前 disp
在这两类 1D 曲线上,围绕当前估计位置做局部采样
把采样结果拼起来
逐段解释

当前 disparity 是 (B,1,H,W),每个像素一个标量视差。 out_pyramid 用来收集所有 level 的特征。

这是多尺度采样。第 i 层表示第 i 个金字塔 level。 因为金字塔每层都会把 disparity 轴 / width 轴缩小 2 倍,所以后面都会看到 / 2**i
第一支:从 geo_volume_pyramid 采样

dx 是一个固定的小窗口偏移,比如 [-4,-3,...,3,4] disp.view(b*h*w,1,1,1) 把每个像素的 disparity 摊平,变成一条条独立的查询 x0 = disp + dx 的意思是: 以当前 disparity 为中心,在它附近采一个局部窗口
所以如果当前某个像素估计 disp=20,dx=[-4..4],那它就会去采 16..24 这一段。 再除以 2**i,是因为第 i 层已经下采样了。

geo_volume 预先被整理成 (B*H*W, C, 1, D),也就是: 每个像素一条 1D 特征曲线 曲线横轴是 disparity
现在用 x0 去这条曲线上做 1D 双线性采样,取出窗口特征。
采完后 reshape 回 (B,H,W,C_window)。所以这部分得到的是:
“当前 disparity 附近,这个像素在 geometry volume 上看到的局部证据”
第二支:从 init_corr_pyramid 采样

这部分和上面很像,但语义不一样。 coords 是左图每个像素自己的 x 坐标。 在 rectified stereo 里,匹配关系是:x_right = x_left - disp . 所以: coords - disp 表示当前 disparity 估计下,这个左图像素在右图里对应到哪里。再加上 dx,就是:
围绕当前右图匹配点,再采一个局部窗口。

init_corr 预先是 (B*H*W, 1, 1, W2),也就是每个左图像素对右图整行位置的相关性曲线。
现在在 x_right = x_left - disp 附近采样。所以这部分得到的是:
“当前匹配位置附近,这个像素在初始相关性曲线上的局部证据”
最后拼接
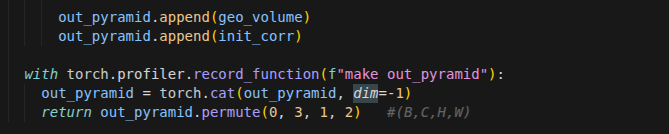
每个 level 都会贡献两块特征: geo_volume 的局部窗口 init_corr 的局部窗口 多层全部拼起来,最后变成标准卷积格式 (B,C,H,W)。 这个输出就是后面 update_block 里的 corr / geo_feat 输入。
这整个函数本质上在做:
以当前 disp 为中心, 从多尺度 matching 曲线里裁一小段局部特征, 把这段局部特征交给 GRU, 让 GRU 预测下一步的 delta_disp
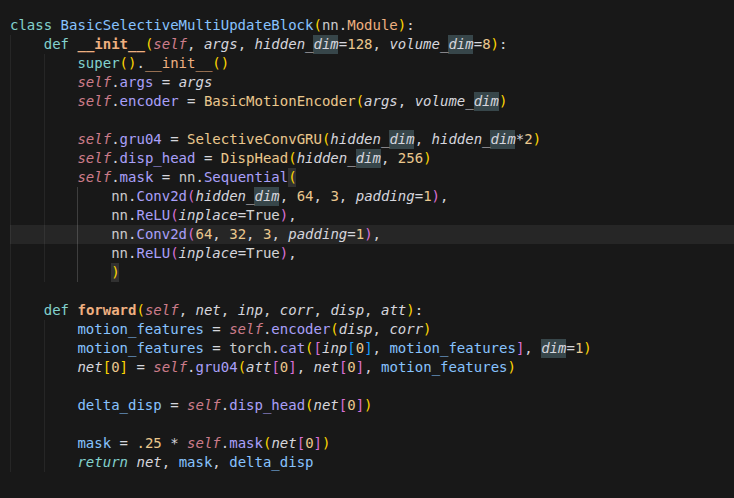
update.py (line 99)
这段 forward() 是 一次 GRU refinement step 的核心。它接收当前状态 net、静态上下文 inp、当前匹配特征 corr、当前视差 disp、注意力 att,输出:
更新后的隐藏状态 net 上采样用的 mask 这一步预测的视差增量 delta_disp

它把两类动态信息编码到一起: disp:当前这一轮的视差估计 . corr:刚才从几何/相关性体里按当前 disp 采出来的局部匹配证据
输出的 motion_features 可以理解成: “如果当前视差是这个值,那么周围匹配证据长什么样” 也就是给 GRU 的“观测”。

inp[0] 不是动态量,而是从 context network 提前提取好的静态上下文特征。它来自主网络里这一段,见 foundation_stereo.py (line 228):
所以这一步是在把两种信息拼起来: inp[0]:这个像素本身的语义/边缘/局部上下文 ; motion_features:当前 disparity 下的匹配线索 GRU 不只看“匹配像不像”,还看“这里是不是边界、纹理、平坦区”。

这是这段最关键的一行。 net[0]:当前 hidden state, motion_features:本轮输入, att[0]:空间注意力图
self.gru04 是 SelectiveConvGRU,定义在 update.py (line 60)。
它内部不是一个 GRU,而是 两个 ConvGRU:一个小卷积核 GRU
一个大卷积核 GRU
最后按 att 混合
所以这行的真实含义是: 用当前输入 motion_features 去更新隐藏状态 net[0],并且让不同空间位置自适应选择“小感受野更新”还是“大感受野更新”。

隐藏状态更新完后,用 DispHead 从新状态里直接回归一个 delta_disp。
这里预测的不是最终 disparity,而是: “当前估计应该再往哪边修、修多少”

这不是 GRU 的门控 mask,而是 上采样 mask 的特征。 后面会送进 upsample_disp(),再经 spx_gru 和 context_upsample(),把 1/4 分辨率 disparity 上采样到全分辨率,见 foundation_stereo.py (line 182)。
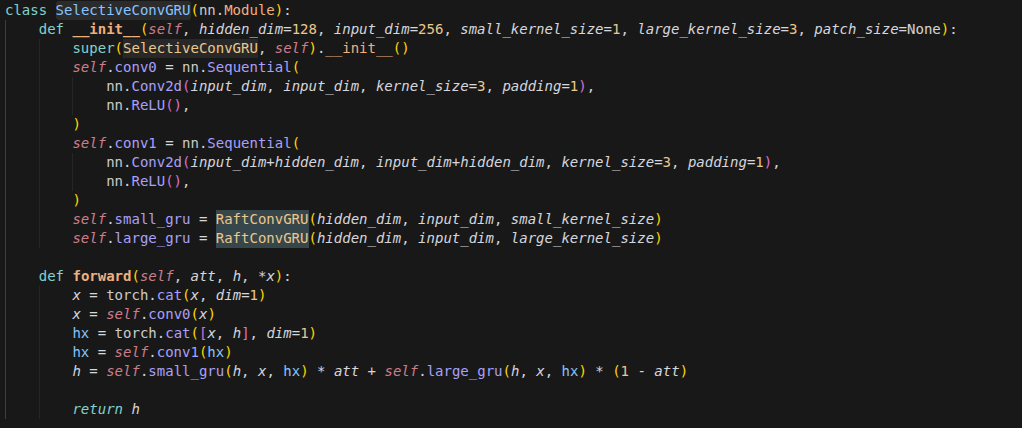
SelectiveConvGRU
普通 ConvGRU 的更新卷积核大小是固定的,比如全用 3x3。
但 stereo refinement 里,不同位置其实想要的更新范围不一样:在物体边界、细纹理处,希望更新更“尖锐”、更局部
在弱纹理、大平面、模糊区域,希望更新更“平滑”、更大感受野
这个类就是在做这种自适应:
small kernel GRU 负责精细局部更新 large kernel GRU 负责更宽区域更新 att 决定每个像素更信哪一个
conv0 先对输入特征 x 做一次轻量预处理


它不改通道数,只做一次 3x3 空间混合,让输入更适合后面的 GRU
conv1 是对 x 和当前 hidden state h 拼起来后的结果做一次预融合


因为后面 GRU 的门控会依赖 x 和 h 的联合信息,这里先用一个 3x3 卷积把它们混一下,相当于提前做一层局部交互。
注意这里有个设计点:
x 本身保留,用于候选状态 q
hx 是 x+h 的融合版本,用于算 z/r 这些门

这里真正定义了两个 GRU 分支: small_gru:默认 1x1 large_gru:默认 3x3 所以两者的区别不是公式不同,而是门控卷积核大小不同

先分别算两份候选新 hidden state: small_gru(...) large_gru(...) 然后按 att 做逐像素混合。
而 普通 ConvGRU: h_new = GRU(h, x) 这里只有一种更新方式。
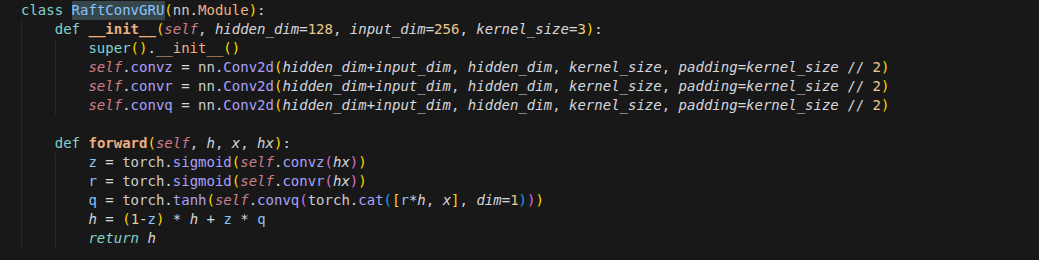
RaftConvGRU
它做的事可以概括成: 给定旧 hidden state h 和当前输入 x,算出一个新的 hidden state h_new

这三个卷积分别对应 GRU 的三部分: convz:更新门 z convr:重置门 r convq:候选状态 q
pi3x 训练
启动入口在 train_pi3.py (line 7)。Hydra 先把 configs/default.yaml 里的各组配置合并好,然后执行 main(hydra_cfg)
accelerate launch --config_file configs/accelerate/ddp.yaml \
--num_processes 8 --num_machines 1 \
scripts/train_pi3.py train=train_pi3_highres name=pi3_highres \
model.ckpt=<path-to-lowres-checkpoint>进入 Pi3/scripts/train_pi3.py ,然后
Pi3/scripts/train_pi3.py
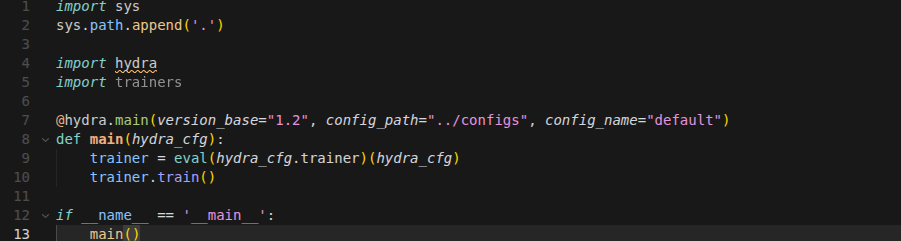
trainer = eval(hydra_cfg.trainer)(hydra_cfg)
等价于trainer_cls = eval(hydra_cfg.trainer) # 得到「类对象」
trainer = trainer_cls(hydra_cfg)
main() 里按 hydra_cfg.trainer 反射实例化 trainer,然后直接调 trainer.train(),见 train_pi3.py (line 8)。这里默认 trainer 是 trainers.pi3_trainer.Pi3Trainer,见 train_pi3_lowres.yaml (line 3)。
Pi3Trainer.__init__() 先进入 BaseTrainer.__init__()
依次做
建 accelerator,base_trainer_accelerate.py (line 66)
实例化 model,base_trainer_accelerate.py (line 72)
创建 train/test dataloader,base_trainer_accelerate.py (line 83)
建 optimizer + scheduler,base_trainer_accelerate.py (line 90)
auto resume、准备日志/ckpt,base_trainer_accelerate.py (line 120)

(先把学习率调度器建出来,再把训练正式接到 accelerate 的运行体系里)
self.iters_per_epoch = ... 决定“每个 epoch 按多少个 step 算”。如果配置里的 train.iters_per_epoch > 0,就直接用配置值;否则才用 len(self.train_loader)。 这意味着你可以“人为规定”一个 epoch 跑多少步,而不一定严格等于 dataloader 的长度
build_scheduler(...) 的作用就是:根据配置,创建一个“学习率调度器对象”,并挂到 self.lr_scheduler 上。
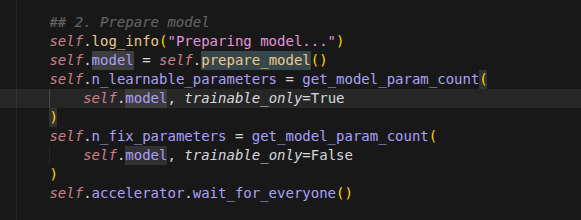
model 的实例化来自 pi3.yaml (line 4),真正建的是 pi3.models.pi3_training.Pi3,见 pi3_training.py (line 26)。
在 prepare_model (line 189) 里真正实例化模型
等价于

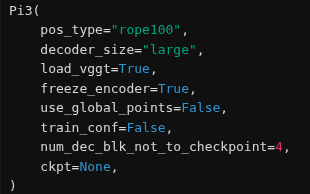
Q & A for Pi3.py
图像 在 pi3_training.py 的哪一步 切成 patch大小的?
在 encoder 内部完成 . 在 patch_embed.py (line 56) 里,关键是这句: self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_HW, stride=patch_HW). 这里 patch_HW = (14, 14),所以它是一个: kernel_size = 14 stride = 14. 的卷积.假设输入是 [B*N, 3, H, W] , 那么经过这个卷积后 [B*N, embed_dim, H/14, W/14] . 卷积后 , [B*N, embed_dim, h, w] -> [B*N, embed_dim, h*w] -> [B*N, h*w, embed_dim] 为最终输出 ( [B*N, num_patches, embed_dim])
使用多头注意力,把一个 特征向量 拆成好几份分别做attention, 这不会把 不同head对应的向量之间的特征隔绝开, 从而丢失信息吗?
qkv(x) 会经过线性层,因此每一个head仍然保留全局信息
为什么 这里 BlockRope 的forward 要先做 attn的 残差连接,再做 mlp 的残差连接?
第一步:Attention(注意力机制)—— 全局信息混合 (Token-mixing)
作用: 它的任务是“看周围”。对于图像中的某一个 Patch(Token),Attention 会计算它与图像中所有其他 Patch 的相关性,并把其他 Patch 的信息按权重聚合到自己身上。
结果: 经过这一步,原本孤立的 Token 拥有了全局上下文(Context)。
第二步:MLP(前馈神经网络)—— 局部特征提取 (Channel-mixing)
作用: 它的任务是“向内消化”。MLP 不会让 Token 之间产生交互,而是对每一个拥有了新上下文的 Token 独立进行升维、非线性激活(GELU)和降维。
在计算局部点云Loss 的时候, loss = |pred - gt| 这是一一对应然后相减的吗?如何找到这个一一对应关系呢?
关键在于 valid_masks 是同一个布尔掩码,并且作用在两个张量上: aligned_local_pts[valid_masks] gt_local_pts[valid_masks]
它们筛出来的是同一组像素位置,顺序也一样。
如何理解 pi3x point head 输出的 xyz?
针孔相机模型的反投影(Back-projection)公式
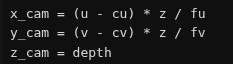
当你已经知道了图像上某个像素的二维坐标
(u, v),并且通过模型(比如 WAFT 加上你的双目公式)算出了它对应的物理深度depth,这三行代码就能算出这个点在真实物理世界中(以相机镜头为原点)的三维空间坐标(x_cam, y_cam, z_cam)依据: 相似三角形定理 “真实世界 X 坐标 / 真实深度” 必然等于 “像素 X 偏移 / 相机焦距”
Pi3X 只是把 ((u-cx)/fx, (v-cy)/fy) 这种“射线斜率”直接学成了 xy,再乘上深度 z 得到真正的 X,Y,Z。
class Pi3 init()
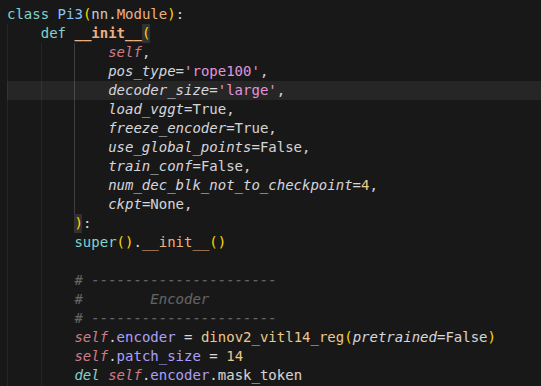
decoder_size:decoder 规模 load_vggt:是否加载 VGGT 权重 freeze_encoder:是否冻结 encoder use_global_points:是否启用 global points 分支 train_conf:是否训练 confidence 分支 num_dec_blk_not_to_checkpoint:前几个 decoder block 不做 gradient checkpoint ckpt:额外 checkpoint 路径
self.encoder = dinov2_vitl14_reg(pretrained=False) 创建编码器,也就是 backbone。 这里用的是 DINOv2 的 vitl14_reg 版本,可以理解成一个 ViT-L/14 编码器。 pretrained=False 表示“这里先不要从这个构造函数内部自动加载默认预训练权重”。 这个项目后面会自己决定是否从 VGGT 或 ckpt 里加载权重,所以这里先把结构建出来就行。
self.patch_size = 14
记录这个 encoder 的 patch size 是 14。
后面前向里会用它把图像尺寸换算成 patch 网格大小,比如 forward (line 252) 里有 patch_h, patch_w = H // 14, W // 14。del self.encoder.mask_token 把 encoder 里的 mask_token 删掉。 mask_token 一般是给 masked-image-modeling 这类预训练任务用的;这个项目当前这条推理/训练路径不需要它,
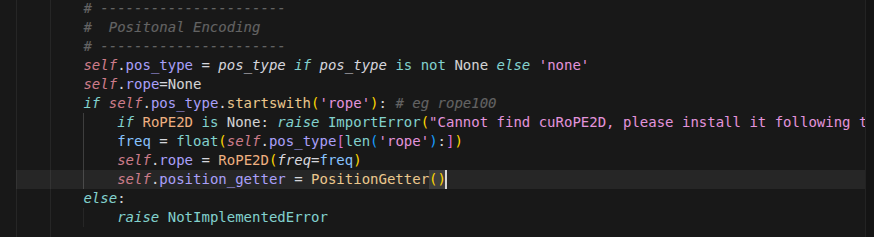
self.pos_type = pos_type if pos_type is not None else 'none' 把外面传进来的 pos_type 记到模型里。 如果调用时没传,就退回成字符串 'none'。 你当前配置里是 rope100,所以这里最终会得到: self.pos_type = 'rope100'
self.rope = RoPE2D(freq=freq) 真正创建 2D RoPE 模块,并保存到 self.rope。 后面 decoder 里的 attention/block 会直接用这个对象。
self.position_getter = PositionGetter() 再创建一个位置索引生成器。 它的作用通常是根据输入的 patch 网格大小,生成每个 token 的二维坐标位置,后面给 RoPE 用。
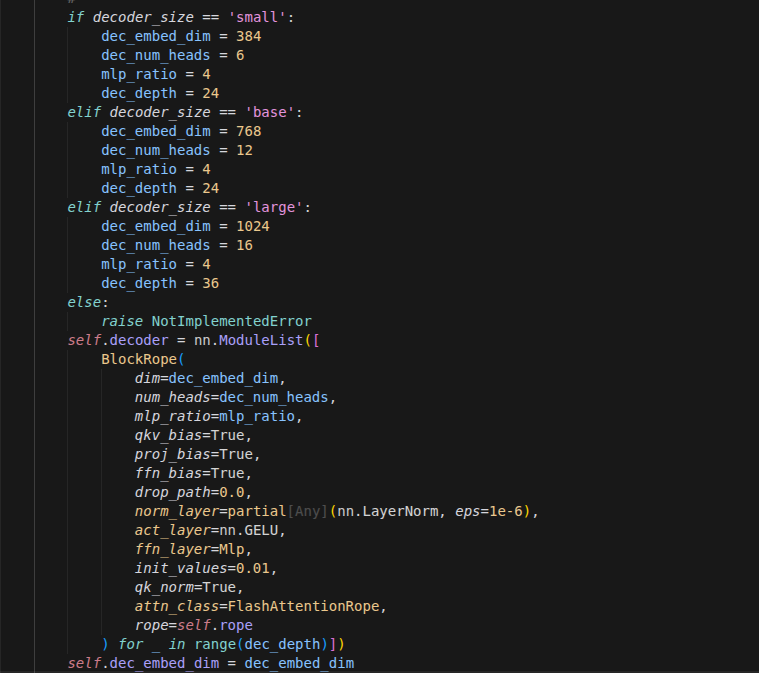
根据 decoder_size 选规模; 例如 , decoder_size == 'small' 用较小配置:embed_dim=384,heads=6,depth=24
创建
self.decoder = nn.ModuleList([... for in range(decdepth)]) 创建一个长度为 dec_depth 的 block 列表。 ModuleList 是 PyTorch 用来注册“很多子模块”的容器,这样这些 block 的参数才能被 model.parameters()、state_dict()、.to(device) 正确管理。 每个元素都是一个 BlockRope(...) 也就是说 decoder 不是一个单独的大模块,而是由很多个同结构的 transformer block 叠起来。
BlockRope(...) 里的关键参数: dim=dec_embed_dim 每个 token 的特征维度,比如现在是 1024 num_heads=dec_num_heads 多头注意力的头数,比如现在是 16 . mlp_ratio=mlp_ratio block 里前馈网络的扩张比例 qkv_bias=True, proj_bias=True, ffn_bias=True 给 attention/MLP 里的线性层启用 bias drop_path=0.0 不用 stochastic depth norm_layer=partial(nn.LayerNorm, eps=1e-6) 指定归一化层类型,并把 eps 固定成 1e-6 act_layer=nn.GELU MLP 的激活函数用 GELU ffn_layer=Mlp block 里的前馈层实现使用 DINOv2 那套 Mlp init_values=0.01 一般是给 layer scale 一类机制的初始值 qk_norm=True 对 attention 里的 query/key 做归一化 attn_class=FlashAttentionRope 注意力实现使用支持 RoPE 的 FlashAttention 版本 rope=self.rope 把前面初始化好的二维 RoPE 位置编码对象传进每个 block,让 attention 能感知空间位置
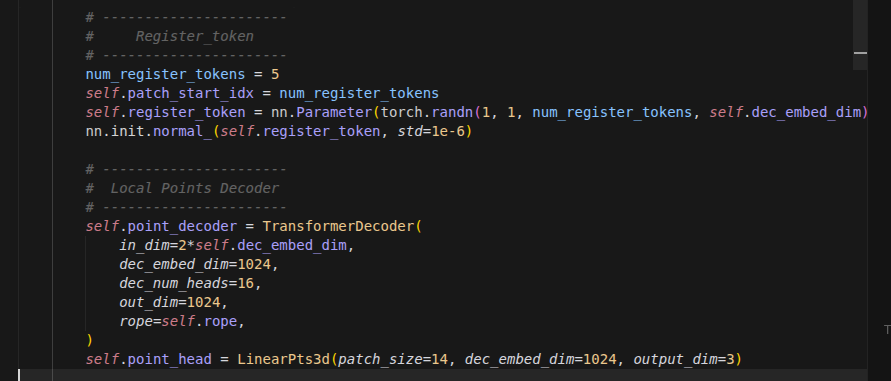
Register Token
num_register_tokens = 5 定义每张图前面要插入 5 个特殊 token。它们有点像额外的全局记忆槽,不对应具体 patch。
创建一个可训练参数,形状是 [1, 1, 5, D],其中 D=self.dec_embed_dim
nn.init.normal_(self.register_token, std=1e-6) 用非常小的高斯噪声初始化,让这些 token 一开始接近 0,训练中再慢慢学出作用。
Local Points Decoder
in_dim=2*self.dec_embed_dim 输入维度是 2 * dec_embed_dim,因为前面的 decode() 最后把倒数两个阶段的输出拼接起来了
Point Head
这是把 token 特征真正变成 3D 点的输出头。 每个 patch token 预测一个 14 x 14 x 3 的局部结果 再通过 pixel_shuffle 还原到整张图的分辨率 最终输出 H x W x 3
Camera Pose Decoder
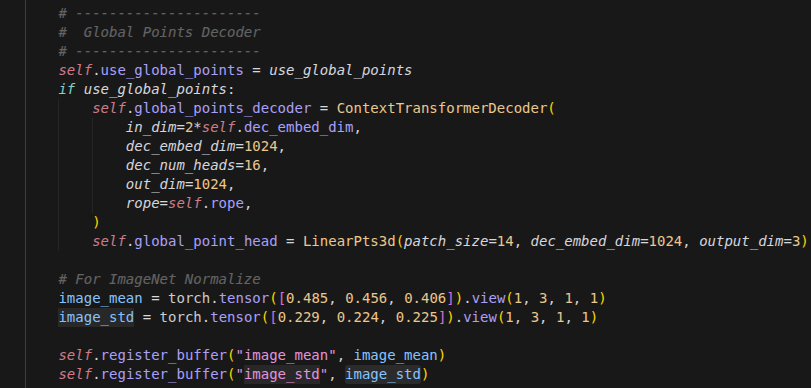
这是标准的 ImageNet RGB 均值和方差,shape 变成 [1, 3, 1, 1] 是为了后面能对整批图片自动广播。
register_buffer 的意思是: 它们属于模型状态 会跟着 model.to(device) 一起搬到 GPU 会进 state_dict() 但不是可训练参数,不会被 optimizer 更新
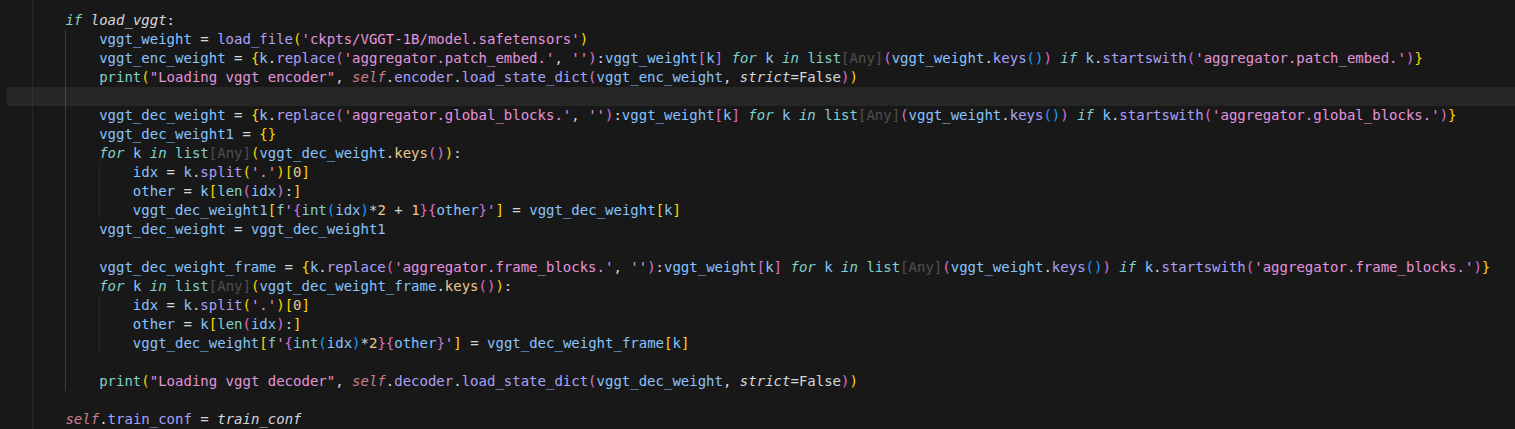
replace 用法 k = "aggregator.patch_embed.proj.weight" k.replace('aggregator.patch_embed.', '')
str.startswith(前缀) 用法:返回True or False "aggregator.patch_embed.foo".startswith("aggregator.patch_embed.")
VGGT 类型 dict[str, torch.Tensor] , 分为 aggregator.patch_embed.* aggregator.global_blocks.* aggregator.frame_blocks.*
Encoder 部分
vggt_enc_weight = { ... if k.startswith('aggregator.patch_embed.') } 只挑出 VGGT 里属于 aggregator.patch_embed.* 的参数,也就是和 patch embedding / encoder 相关的权重。 同时把键名里的前缀
Decoder部分
vggt_dec_weight = { ... if k.startswith('aggregator.global_blocks.') } 先取出 VGGT 里 global_blocks 的参数。 这些参数对应的是 Pi3 decoder 里的“奇数层” block
vggt_dec_weight_frame = { ... if k.startswith('aggregator.frame_blocks.') } 再取出 VGGT 里 frame_blocks 的参数。 vggt_dec_weight[f'{int(idx)*2}{other}'] = ... 这次把它们映射到 Pi3 decoder 的偶数位置上。
self.decoder.load_state_dict(vggt_dec_weight, strict=False) 最后把整理好的 decoder 权重加载进 self.decoder
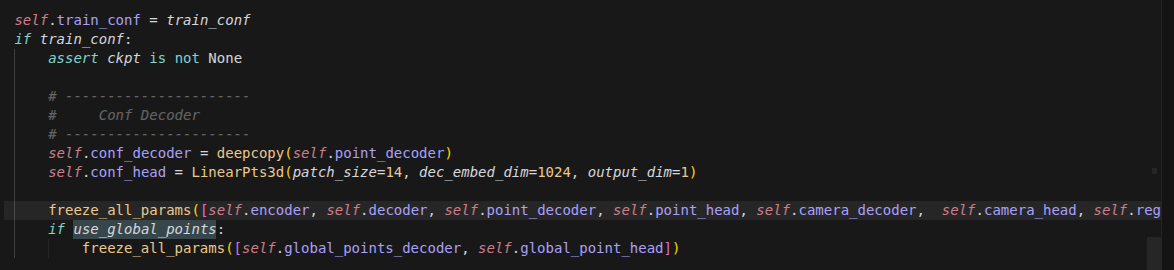
self.conf_decoder = deepcopy(self.point_decoder) 复制一份 point_decoder,作为 confidence 分支的 decoder。
self.conf_head = LinearPts3d(..., output_dim=1) 创建 confidence 输出头。 和点云头不同,这里 output_dim=1,表示每个像素输出一个标量置信度,而不是 3 维点坐标。
freeze_all_params([...])把一大串模块全部冻结:encoder decoder point_decoder point_head camera_decoder camera_head register_token 冻结的意思是这些参数 requires_grad=False,训练时不会更新。

checkpoint = torch.load(ckpt, weights_only=False, map_location='cpu') 从磁盘读取 checkpoint。
res = self.load_state_dict(checkpoint, strict=False) 把 checkpoint 里的参数灌进当前模型。 strict=False 的意思是: 当前模型有、checkpoint 没有的参数先忽略 checkpoint 有、当前模型没有的参数先忽略 这适合你这个项目,因为模型结构可能加了新分支、改了 head,没法要求完全一致。
checkpoint 是一个 模型的 state_dict
load_state_dict 会按 key 名字递归匹配当前模型里的所有: nn.Parameter , register_buffer 的 buffer 子模块里的子参数 比如模型里有: self.encoder = ... self.decoder = nn.ModuleList([...]) self.register_buffer("image_mean", ...) 那么它会去找这些对应名字的键,比如: encoder.patch_embed.proj.weight ; decoder.0.attn.qkv.weight ; image_mean 只要: 名字对得上 shape 对得上 就把 checkpoint 里的 tensor 拷贝进去。
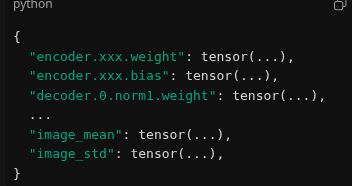
class Pi3 decode()
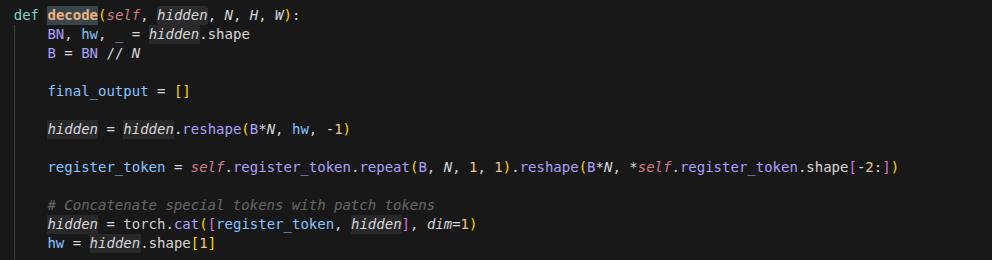
def decode(self, hidden, N, H, W): hidden 是 encoder 输出的 token 特征。 N 是每个样本里有几个视角。 H, W 是原图尺寸。 BN, hw, _ = hidden.shape 说明此时 hidden 形状是 [B*N, token数, 通道数]。
final_output = [] 用来保存 decoder 最后几层的输出,后面会拼接成最终特征。
register_token = self.register_token.repeat(B, N, 1, 1).reshape(B*N, self.register_token.shape[-2:]) 把可学习的 register_token 复制到每个 batch、每个视角上。 原始形状大概是 [1, 1, 5, C],复制后变成 [BN, 5, C]。(给register token标位置)
hidden = torch.cat([register_token, hidden], dim=1) 把 5 个特殊 token 拼到 patch token 前面。(对每个 batch 里的每个视角,都在该视角的 patch token 序列前拼上 5 个 register token)
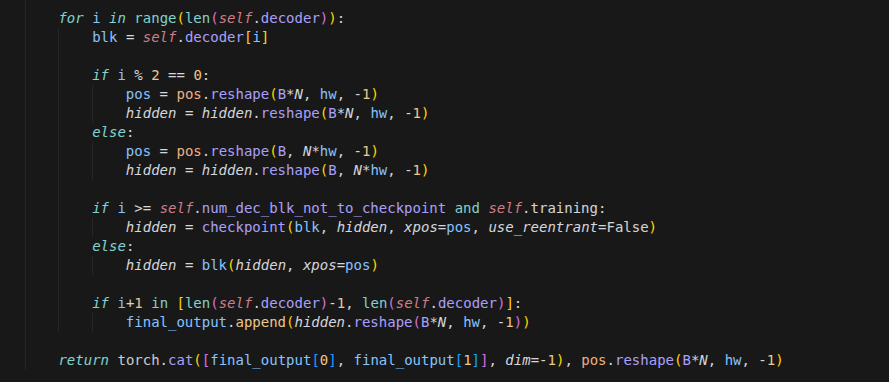
pos = self.position_getter(B N, H//self.patch_size, W//self.patch_size, hidden.device) 生成二维网格位置坐标。 这里的 pos 通常对应每个 patch token 的 (x, y) 位置,形状大致是 [BN, patch_num, 2]
(0,0), (0,1), ..., (0,w-1),
(1,0), (1,1), ..., (1,w-1),
pos = pos + 1 把所有 patch token 的位置整体往后挪一位。 这是为了给“特殊 token 位置 = 0”留出空间
pos = torch.cat([pos_special, pos], dim=1) 把特殊 token 的位置和 patch token 的位置拼起来。 最终 pos 的长度和 hidden 的 token 数完全对齐。
[0,0] [0,0] [0,0] [0,0] [0,0] [patch1] [patch2] ... [patch16]
blk解释 详见下面的栏目
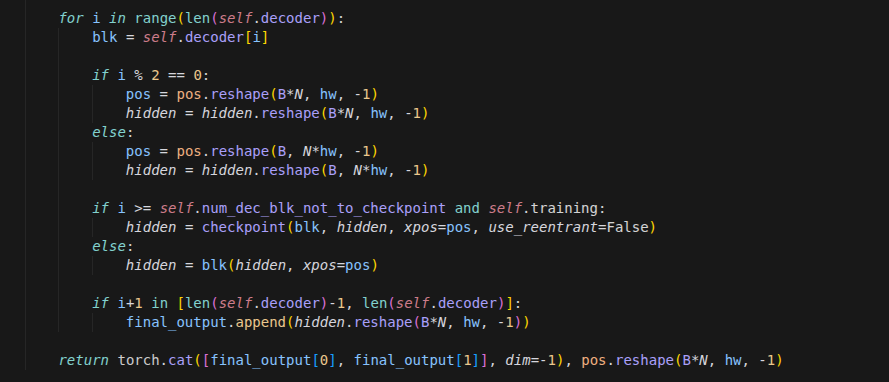
if i >= self.num_dec_bdlk_not_to_checkpoint and self.training: 如果当前层已经超过“不做 checkpoint 的前几层”,并且模型在训练模式,就启用 gradient checkpoint。
hidden = checkpoint(blk, hidden, xpos=pos, use_reentrant=False) 通过 checkpoint 运行这个 block。 好处是省显存,因为中间激活值不全部保存,反向传播时再重算。
checkpoint 是 PyTorch 的 gradient checkpointing 函数,一般来自 torch.utils.checkpoint.checkpoint。 它的作用是: 前向传播时,不保存某些中间激活值; 反向传播时,再把这段前向重新算一遍 这样做的核心收益是: 省显存 代价是: 多一点计算
blk 是当前的一个 BlockRope ; hidden 是输入 token 特征; xpos=pos 是位置编码
else: hidden = blk(hidden, xpos=pos) 前面几层或者非训练时,直接正常前向。
if i+1 in [len(self.decoder)-1, len(self.decoder)]: 如果当前层是倒数第二层或最后一层,就把输出存起来。 final_output.append(hidden.reshape(B*N, hw, -1))
把最后两层的特征在通道维拼接起来, 同时返回对应的位置编码 pos
Pi3 forward()
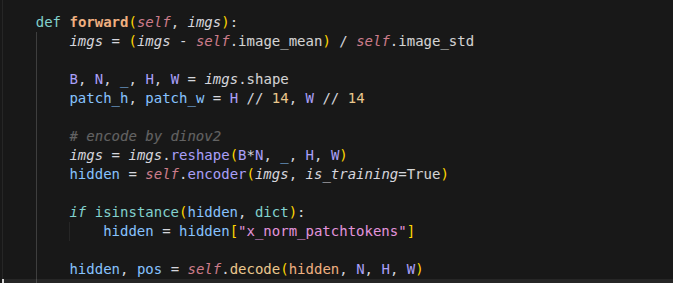
把图像送进 DINOv2 encoder,得到图像 token 特征。
把 encoder 输出的 token 交给 decode(),进一步加入 register token、RoPE 位置编码,并经过主 decoder。 返回: hidden:更高层的 token 特征 pos:对应的位置坐标

point_hidden = self.point_decoder(hidden, xpos=pos) 用 point_decoder 处理 hidden,得到“局部 3D 点”分支的特征。 这里 xpos=pos 会把 RoPE 位置编码传进去,让 decoder 知道每个 token 的空间位置。
conf_hidden = self.conf_decoder(hidden, xpos=pos) 用和点分支类似的结构,生成置信度分支特征。 这条分支通常是从 point_decoder 拷贝出来的,但参数独立。
context = hidden.reshape(B, N, patch_h*patch_w+self.patch_start_idx, -1)[:, 0:1].repeat(1, N, 1, 1).reshape(B*N, patch_h*patch_w+self.patch_start_idx, -1) 从 [B*N, tokens, C] 变成 [B, N, tokens, C] , 取每个样本里的第一个视角 (形状变成 [B, 1, tokens, C])。 把这个第一个视角复制 N 份,变成: [B, N, tokens, C]. 再把 [B, N, tokens, C] 拉回 [B*N, tokens, C]
global_point_hidden = self.global_points_decoder(hidden, context, xpos=pos, ypos=pos) 把当前视角的 hidden 和参考上下文 context 一起送进 ContextTransformerDecoder。
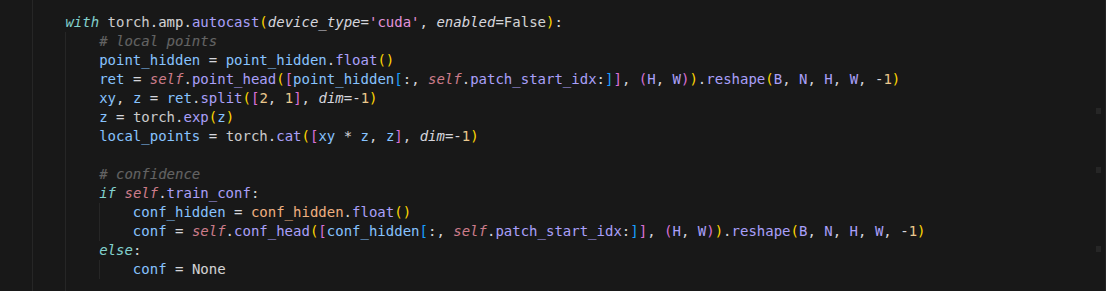
显式关闭 autocast
ret = self.point_head([point_hidden[:, self.patch_start_idx:]], (H, W)).reshape(B, N, H, W, -1) 先只取 point_hidden 里真正的 patch token,跳过前面的 register_token。 然后送进 point_head,它会把 token 特征还原成每个像素的预测。最后 reshape 成 [B, N, H, W, 3] 左右的形状。
xy, z = ret.split([2, 1], dim=-1) 把最后一维拆成两部分: xy:前 2 维 z:最后 1 维
z = torch.exp(z) 对深度做指数变换,保证 z > 0
local_points = torch.cat([xy * z, z], dim=-1) 把最终 3D 点组出来。 这里的含义是: xy 先乘上深度 z 再把 z 作为第三维拼回去
如果启用了置信度分支,就额外预测每个像素的 confidence
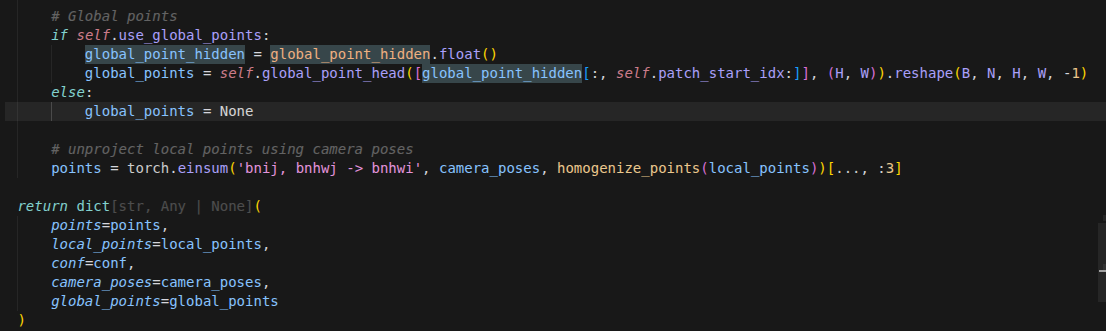
points = torch.einsum('bnij, bnhwj -> bnhwi', camera_poses, homogenize_points(local_points))[..., :3]
local_points:前面算出来的局部 3D 点 homogenize_points(local_points):把点变成齐次坐标,通常会在最后补一个 1 camera_poses:每个视角对应的 4x4 变换矩阵 torch.einsum('bnij, bnhwj -> bnhwi', ...):做批量矩阵乘法,把每个点从局部坐标系变换到相机/世界坐标系 ;[..., :3]:只取前 3 个坐标,丢掉齐次坐标那一维 所以这里的 points 是最终输出的 3D 点。
FlashAttentionRope
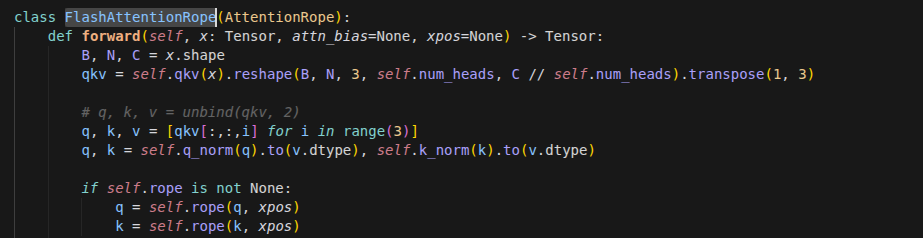
前向函数输入: x:token 特征,形状通常是 [B, N, C]; attn_bias:注意力偏置,这个实现里基本没重点用; xpos:二维位置坐标,会传给 RoPE
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).transpose(1, 3); 先用线性层把 x 一次性投影成 q/k/v 三份,然后 reshape 成多头格式。 transpose 后:[B, heads, 3, N, head_dim]
q, k, v = [qkv[:,:,i] for i in range(3)] 从第三维取出 q/k/v,每个形状类似 [B, heads, N, head_dim]
q, k = self.q_norm(q).to(v.dtype), self.k_norm(k).to(v.dtype) ; 内部是 self.q_norm = norm_layer(head_dim) if qk_norm else nn.Identity() , 由于 创建 BlockRope 的时候穿参了 qk_norm=True, 所以对 q 和 k 的最后一维,也就是每个 head 的特征维 head_dim,做 LayerNorm
q = self.rope(q, xpos) k = self.rope(k, xpos) 二维 RoPE 位置编码,也就是把 token 的空间位置信息“旋转”进 q/k 向量里
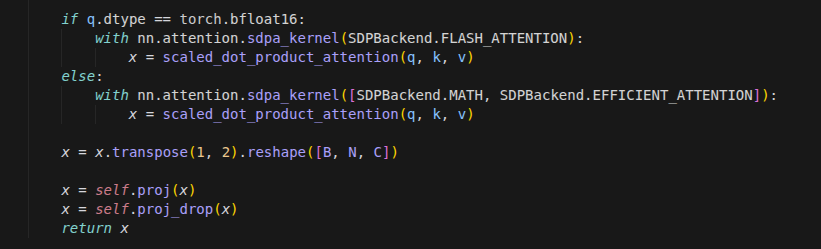
scaled_dot_product_attention(q, k, v) 是标准的 self-attention
Attention(Q,K,V) = softmax(QK^T / sqrt(d)) V
输入形状通常是: q, k, v: [B, heads, N, head_dim] 输出形状还是: x: [B, heads, N, head_dim]
x = x.transpose(1, 2).reshape([B, N, C]) 把多头结果合并回 token 表示 . 也就是从: [B, heads, N, head_dim] 变成: [B, N, heads * head_dim]
x = self.proj(x) x = self.proj_drop(x) 这两步是 attention 输出后的线性映射: self.proj: Linear(C -> C) self.proj_drop: dropout
decode[i].forward

输入形状 [B, N, C] , (外层调用输入 有可能是hidden = hidden.reshape(B*N, hw, -1) 或 hidden = hidden.reshape(B, N*hw, -1) , 要看是全局还是局部 transformer )
self.norm1 = norm_layer(dim)
如果 x 的形状是 [B, N, C],那么它对每个位置上的 C 维向量做:
y = (x - mean(x)) / sqrt(var(x) + eps) * gamma + beta
mean(x):对最后一维 C 求均值; var(x):对最后一维 C 求方差; eps=1e-6:防止除零、让数值更稳定 ;gamma:可学习缩放参数 beta:可学习平移参数
每个 token 独立归一化; 不依赖别的样本; 不依赖同一个 batch 里的其他 token
attn 见 上面
LayerScal
实现 self.gamma = nn.Parameter(init_values * torch.ones(dim))
构造 BlockRope 时传的是 init_values=0.01 它的作用是让训练更稳,尤其是深层 Transformer
这个块里最终是: x = x + self.ls1(attn_out)

MLP x -> fc1 -> GELU -> dropout -> fc2 -> dropout 源码里是: self.fc1 = nn.Linear(in_features, hidden_features) self.act = nn.GELU() self.fc2 = nn.Linear(hidden_features, out_features) self.drop = nn.Dropout(drop)
将维度放大 4 倍提供了一个更宽广的高维空间。在低维空间中纠缠在一起的复杂特征,映射到高维空间后往往会变得更容易区分(线性可分)。MLP 的逻辑是先把特征“摊开”在高维空间中进行复杂的非线性映射,过滤并提炼出更丰富的表达,然后再将精华“压缩”回原始维度,这极大地提升了模型的表征容量(Capacity)。
当通过第一层线性变换(fc1)将维度放大 4 倍时,模型的参数量和表达能力呈爆炸式增长。虽然这让模型有了极强的特征提取能力,但也带来了一个致命风险——模型很容易“死记硬背”训练数据,导致在训练集上表现极好,但在没见过的测试集上表现很差。 Dropout 会在每次前向传播(训练过程)中,以一定的概率(比如 0.1 或 0.5)随机让一部分神经元“失活”(权重归零)。
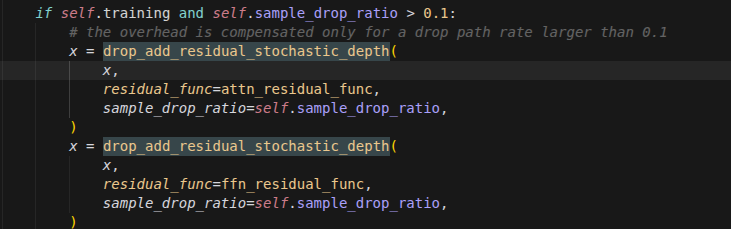
drop_add_residual_stochastic_depth(...) 的思路是: 从 batch 里随机抽一部分样本, 只对这部分样本计算 residual 分支, 再把结果按比例加回到原 batch
为什么 sample_drop_ratio > 0.1 才用? 因为这个优化本身也有开销 , 如果 drop_path 太小,节省的计算不一定能抵消这些额外开销,所以代码里只在 drop_path > 0.1 时才启用这个版本
它会分别对两部分 residual 做 stochastic depth: attention residual + ffn residual
drop_path1 是什么? 它是一个 DropPath(drop_path): 训练时按样本随机丢弃某些残差路径 , 保留时会做相应缩放,维持期望值稳定 推理时不丢
attention residual 的 drop path FFN residual 的 drop path 共享了同一个模块对象。
如果不是训练,或者 drop_path == 0,就直接做标准 residual:
end of Pi3
Loss
Local Points
pred_local_pts 取模型预测的局部 3D 点,通常形状是 [B, N, H, W, 3]。
valid_masks = gt['valid_masks'] 取有效像素掩码,表示哪些位置有真实 3D 点可监督。
details = dict[Any, Any]() 用来记录各项 loss 的字典,后面会往里塞 local_pts_loss、normal_loss 等
gt_local_pts[..., 2] 取 GT 3D 点的第 3 个坐标,通常可以理解成深度 z
weights_ = weights_.clamp_min(0.1 * weighted_mean(weights_, valid_masks, dim=(-2, -1), keepdim=True))
只在有效像素 valid_masks 上,计算 weights_ 在 H, W 维度上的平均值; keepdim=True 表示结果还保留 H, W 这两个维度,方便广播
0.1 * ... 把这个平均值乘 0.1,作为一个较小的参考下限; clamp_min(...) 把 weights_ 里所有小于这个下限的值,都抬高到这个下限
1 / (weights_ + 1e-6) 把深度变成“倒数权重”; 所以最终效果是: 深度越大,权重越小

xyz_pred_local = self.prepare_ROE(pred_local_pts.reshape(B, N, H, W, 3), valid_masks.reshape(B, N, H, W), target_size=self.local_align_res).contiguous()
“先从预测点图里,按照 mask 取出有效点,再压成统一长度的一批点,供后面的尺度对齐函数使用。”
返回通常是 [B, N, target_size, 3]
local_align_res 就是“局部点对齐时,统一采样到多少个点”的超参数,默认是 4096
align_points_scale(...) 输入是预测点 xyz_pred_local、GT 点 xyz_gt_local、以及点权重 xyz_weights_local . 它会求一个最优缩放系数 S_opt_local 目标是让:
S_opt_local * pred ≈ gt
S_opt_local[S_opt_local <= 0] *= -1 如果算出来的尺度是非正的,就把它变成正的
aligned_local_pts = S_opt_local.view(B, 1, 1, 1, 1) * pred_local_pts 把每个 batch 对应的尺度变成 [B,1,1,1,1] , 这样可以广播到整个 [B, N, H, W, 3] 的预测点图上
local_pts_loss = self.criteria_local(aligned_local_pts[valid_masks].float(), gt_local_pts[valid_masks].float()) * weights_[valid_masks].float()[..., None]
局部点 loss = 有效像素上的加权 L1(对齐后预测点, GT 点)
一般来讲 , aligned_local_pts.shape = [B, N, H, W, 3] , valid_masks.shape = [B, N, H, W] , 结果一般为 [num_valid, 3]
criteria_local 是一个 逐元素 L1 损失, 如果输入是: pred = aligned_local_pts[valid_masks]; gt = gt_local_pts[valid_masks] 那它做的是: loss = |pred - gt| . 输出为 [num_valid, 3] , 代码里马上又乘了权重: * weights_[valid_masks].float()[..., None] 这会把 [num_valid] 扩成 [num_valid, 1],再广播到 [num_valid, 3]。 所以最终就是: 加权后的逐坐标绝对误差 然后后面再做 .mean(),变成一个标量。

预测的局部表面朝向,要和 GT 的局部表面朝向一致

if 'global_points' in pred and pred['global_points'] is not None: 只有开启了 global points 分支,才计算这项 loss。
pred_global_pts = pred['global_points'] * S_opt_local.view(B, 1, 1, 1, 1) 把预测的 global points 乘上前面算出来的局部尺度对齐因子 S_opt_local。 这是为了让 global points 也和 GT 在同一尺度上比较。
global_pts_loss = self.criteria_local(...) * weights_[valid_masks].float()[..., None] 对有效像素上的预测点和 GT 点做 L1 loss,然后再乘上深度相关的权重。
Camera Loss
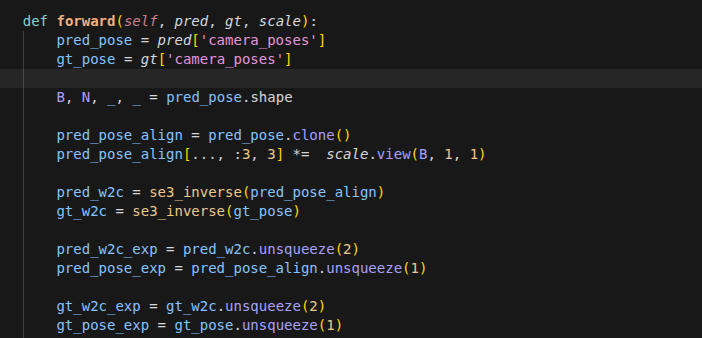
pred_pose = pred['camera_poses'] gt_pose = gt['camera_poses'] , 形状通常是 [B, N, 4, 4]
pred_pose_align[..., :3, 3] *= scale.view(B, 1, 1) 只对平移向量做尺度缩放。
pred_w2c = se3_inverse(pred_pose_align) gt_w2c = se3_inverse(gt_pose) 把 camera pose 反过来,得到 world-to-camera 变换
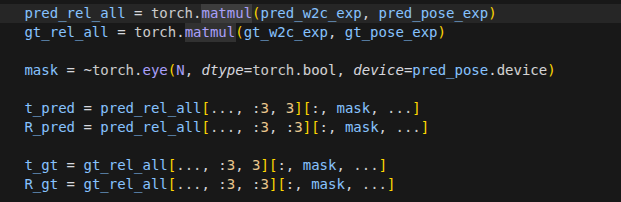
pred_rel_all = torch.matmul(pred_w2c_exp, pred_pose_exp) gt_rel_all = torch.matmul(gt_w2c_exp, gt_pose_exp) 这两个张量会在视角维上形成两两组合, 可以理解为
pred_rel_all[i, j] = pred_w2c[i] @ pred_pose[j]
“从 i 的坐标系看 j 的位姿关系”
mask = ~torch.eye(N, dtype=torch.bool, device=pred_pose.device)
生成一个 N x N 的布尔矩阵: 对角线是 False, 非对角线是 True(i == j 的时候,不比较自己和自己, 只比较不同视角之间的相对关系)
t_pred = pred_rel_all[..., :3, 3][:, mask, ...]
R_pred = pred_rel_all[..., :3, :3][:, mask, ...]
pred_rel_all 的最后两个维度是一个 4x4 齐次变换矩阵: [..., :3, :3] 取旋转矩阵, R [..., :3, 3] 取平移向量 t , 然后 [:, mask, ...] 用刚才那个布尔 mask 只保留非对角线项。
final_loss = point_loss + 0.1 * camera_loss
Debug
如何安全阅读safetensors
最常用:只看有哪些 tensor、shape、dtype,不把 5.1G 全部读进内存
model.safetensors 里面是一个 PyTorch 模型权重文件,包含 1873 个 tensor 参数。你打印的是前 50 个参数的名字、形状和数据类型
conda run -n waft-stereo python -c "
from safetensors import safe_open
path='/home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors'
with safe_open(path, framework='pt', device='cpu') as f:
keys = f.keys()
print('num tensors:', len(keys))
for k in list(keys)[:50]:
t = f.get_tensor(k)
print(k, tuple(t.shape), t.dtype)
"
如何检查权重是否坍塌?
cd /home/cht/cht/Pi3 && /home/cht/miniconda3/envs/waft-stereo/bin/python -c "
from safetensors.torch import load_file
import torch
p='/mnt/nas/share/home/cht/cht/Pi3/runs/pi3x_waft_tartanair/manifest_waft_finetune_epoch3_finetuned.safetensors'
sd=load_file(p, device='cpu')
print('num tensors:', len(sd))
for name, t in sd.items():
if not torch.is_floating_point(t):
continue
nan = torch.isnan(t).any().item()
inf = torch.isinf(t).any().item()
zero_frac = (t == 0).float().mean().item()
if nan or inf or zero_frac > 0.99 or name.startswith(('metric_', 'point_', 'depth_', 'ray_embed')):
print(name, tuple(t.shape), t.dtype,
'min', float(t.min()),
'max', float(t.max()),
'mean', float(t.mean()),
'std', float(t.std()) if t.numel() > 1 else 0.0,
'zero_frac', zero_frac,
'nan', nan,
"nan = torch.isnan(t).any().item()
torch.isnan(t) : 逐个元素地检查张量
t中的值是不是 NaN(Not a Number)。返回一个与t形状完全相同的新张量,里面的数据类型是布尔值(Boolean).any()作用:对上一步得到的布尔张量执行“逻辑或(OR)”操作, 返回一个只包含单个元素(0维标量)的张量..item()作用:将只包含单个元素的 PyTorch 张量(Tensor)转换回 Python 的原生数据类型(如普通的bool,float,int等)
zero_frac = (t == 0).float().mean().item()
计算张量中数值为 0 的比例
输出太长,我看不到?
你的命令 | tee output.txt
tee命令的作用是从标准输入(Standard Input, stdin)读取数据,然后同时将其输出到标准输出(Standard Output, stdout)和一个或多个文件中
两个模型的参数差别比较
/home/cht/miniconda3/envs/waft-stereo/bin/python - <<'PY'
from safetensors import safe_open
import torch
base = '/home/cht/cht/Pi3/ckpts/Pi3X/model.safetensors'
ft = '/mnt/nas/share/home/cht/cht/Pi3/runs/pi3x_waft_tartanair/manifest_waft_finetune_epoch3_finetuned.safetensors'
groups = [
'encoder', 'decoder', 'depth_encoder', 'point_decoder', 'point_head',
'metric_decoder', 'metric_head', 'camera_decoder', 'camera_head',
'conf_decoder', 'conf_head', 'ray_embed', 'depth_emb', 'bf_prior_mlp',
'pose_inject_blk', 'register_token', 'metric_token'
]
stats = {g: {'n': 0, 'changed': 0, 'max_abs': 0.0, 'mean_abs_sum': 0.0} for g in groups}
with safe_open(base, framework='pt', device='cpu') as fb, safe_open(ft, framework='pt', device='cpu') as ff:
bkeys = set(fb.keys())
fkeys = set(ff.keys())
common = sorted(bkeys & fkeys)
print('common', len(common), 'base_only', len(bkeys - fkeys), 'ft_only', len(fkeys - bkeys))
if fkeys - bkeys:
print('ft_only keys:', sorted(fkeys - bkeys))
for k in common:
g = next((x for x in groups if k == x or k.startswith(x + '.')), None)
if g is None:
continue
a = fb.get_tensor(k)
b = ff.get_tensor(k)
s = stats[g]
s['n'] += 1
if a.shape != b.shape or a.dtype != b.dtype:
s['changed'] += 1
s['max_abs'] = float('inf')
continue
if not torch.equal(a, b):
d = (a.float() - b.float()).abs()
s['changed'] += 1
s['max_abs'] = max(s['max_abs'], float(d.max()))
s['mean_abs_sum'] += float(d.mean())
for g, s in stats.items():
mean_changed = s['mean_abs_sum'] / s['changed'] if s['changed'] else 0.0
print('{:<18s} tensors={:4d} changed={:4d} max_abs={:.6g} mean_abs_changed={:.6g}'.format(
g, s['n'], s['changed'], s['max_abs'], mean_changed
))
PYcommon = sorted(bkeys & fkeys) print('common', len(common), 'base_only', len(bkeys - fkeys), 'ft_only', len(fkeys - bkeys))
集合操作
g = next((x for x in groups if k == x or k.startswith(x + '.')), None)
k.startswith(x + '.'):处理子模块/权重的情况 ; 假设 k 是 'encoder.layer1.weight',而 x 是 'encoder'
next(... , None)
短路机制(极高效率):因为生成器是按需计算的,所以
next()只要找到了第一个满足条件的 x,就会立刻停止遍历。哪怕groups里有 1000 个元素,只要第 1 个匹配上了,后面 999 个根本就不会执行。这比使用列表推导式[x for x in groups if ...][0]的效率要高得多。安全兜底(
None):如果k属于一个未知的模块(比如k = 'optimizer.step'),生成器里一个符合条件的x都没有。正常情况下next()会报错(抛出StopIteration异常)。但我们在第二个参数位置传了None(即next(生成器, 默认值)),这样当找不到任何结果时,代码不会报错,而是安全地返回None。
WAFT
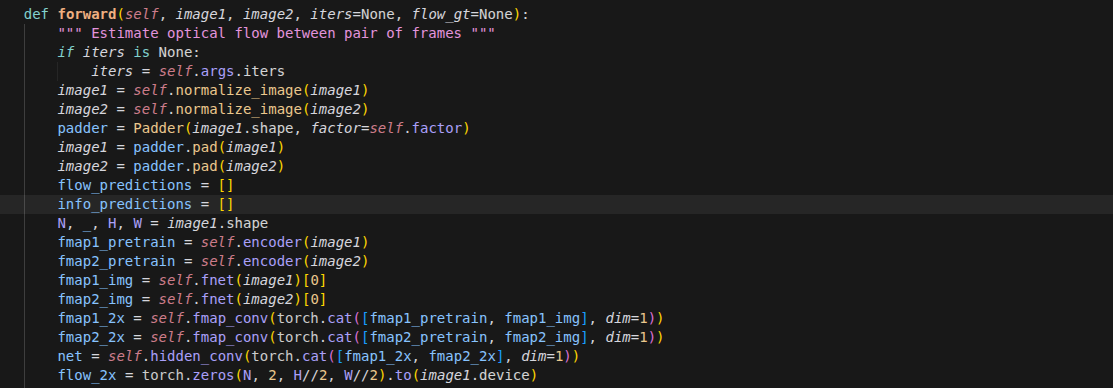
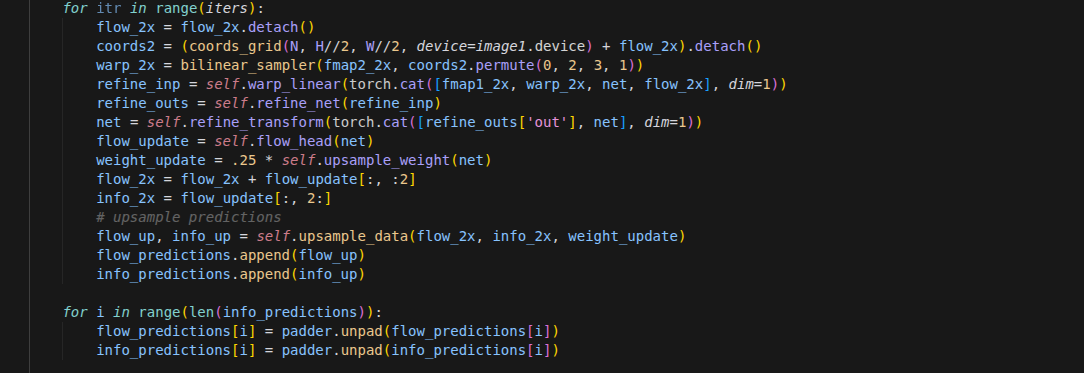
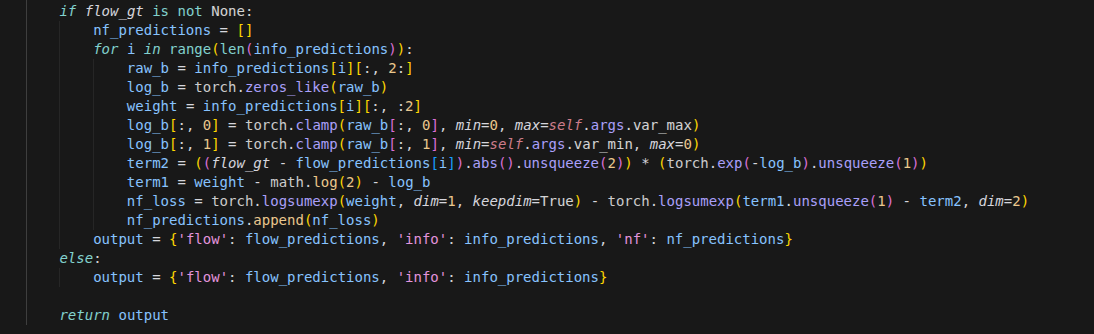
forward()
初始化

image1 和 image2 是前后两帧图像,通常形状都是 (N, 3, H, W)。 iters 是迭代更新 flow 的次数。 flow_gt 是真值光流,只在训练或算辅助输出时用,纯推理时一般是 None

对两张图做归一化。这个 normalize_image 里做的是: 先把像素从 0~255 缩到 0~1 ; 再按 ImageNet 的 mean/std 标准化

flow_predictions:每轮的光流预测
info_predictions:每轮附带的额外信息分支输出

这里的 self.encoder 是预训练特征编码器,在 init 里按配置选成 twins、dav2 或 dinov3 之一 model/waft_a2.py (line 66)。 它输出的是“语义更强”的高层特征,通常已经是半分辨率,也就是大致 (N, pretrain_dim, H/2, W/2)。

这里的 self.fnet 是一个单独的可训练 CNN 分支 model/waft_a2.py (line 78),ResNet18Deconv 会返回多尺度特征 [out_1, out_2, out_3, out_4] model/waft_a2.py (line 34)
取 [0] 就是最高分辨率那一级,也是在 H/2, W/2 上。它更偏向保留图像局部纹理、边缘这类细节。

torch.cat(..., dim=1) 是在通道维拼接,所以先把“语义特征 + 图像细节特征”合在一起。 然后 self.fmap_conv 是一个 1x1 conv model/waft_a2.py (line 81),作用是:
融合这两类信息
把通道数投影到后面 iterative transformer 需要的维度 iter_dim

这里把两帧的融合特征再拼起来,经过另一个 1x1 conv model/waft_a2.py (line 82),得到初始隐藏状态 net。
这个 net 不是最终光流,而是后面每轮 refinement 都会更新的内部状态。你可以把它看成:当前两帧的联合上下文表示
供后面 transformer 迭代更新使用的“记忆”

初始化一个全零光流,形状是 (N, 2, H/2, W/2):
第 1 个通道是水平位移 dx
第 2 个通道是垂直位移 dy
它从“无运动”开始,然后在后面的循环里一轮一轮加上更新量。
预测一个“增量修正”,反复迭代
先看这轮迭代的输入是什么
fmap1_2x, fmap2_2x:两帧在半分辨率上的融合特征。(N, C, H/2, W/2)
net:当前隐藏状态,表示“到目前为止模型对这两帧关系的内部记忆”。(N, C, H/2, W/2)
flow_2x:当前半分辨率光流估计,初始是 0。 (N, 2, H/2, W/2)

flow_2x = flow_2x.detach():把“上一轮的 flow 估计”当成常量,不让后一轮的梯度再回传到前一轮
整体效果是:每一轮只负责学自己的增量修正,而不是让后面的轮次穿过 warping 一路改前面的轮次

coords_grid(...) 定义在 utils/utils.py (line 87),返回的是一个规则像素网格: 每个位置先有自己的基础坐标 (x, y) , 形状是 (N, 2, H/2, W/2)
把 flow_2x 加上去后,得到: coords2[x, y] = (x + u, y + v) . 也就是说,对第一帧当前位置 (x, y),去第二帧的 (x+u, y+v) 取特征。 这正是“用当前 flow 把第二帧往第一帧对齐”的几何意义

注意 coords2 本来是 (N, 2, H/2, W/2),而 grid_sample 需要 (N, H/2, W/2, 2),所以先 permute
输出 warp_2x 的形状和 fmap2_2x 一样,仍然是 (N, C, H/2, W/2),但语义变了: fmap2_2x:原始第二帧特征 warp_2x:按当前 flow 对齐到第一帧坐标系后的第二帧特征
这一步就是 WAFT 的关键思想: 它不先构造大 cost volume,而是直接用当前 flow 去 warp 第二帧特征,然后看 warp 后还差多少

把当前轮需要的所有信息拼起来
fmap1_2x:第一帧当前参考特征; warp_2x:按当前 flow 对齐过来的第二帧特征; net:历史隐藏状态; flow_2x:当前估计的光流. 拼接后通道数是 3C + 2
然后 self.warp_linear 是一个 1x1 conv,把它重新投影回迭代模块需要的通道维度。
这一步的意义是:不是只比较两帧特征而是让模型同时看到“当前对齐结果、历史记忆、当前位移假设”

这里进入真正的 iterative module,也就是 VisionTransformer,定义在 model/backbone/vit.py (line 18)。
它做的事情是: 把 refine_inp 切成 patch 用 transformer blocks 做全局交互 再通过 DPT-style 头把 token 还原成 2D feature map

这一步是在更新隐藏状态 net
把 transformer 这一轮产生的新特征 refine_outs['out']
和旧的 net
再拼起来做一次卷积融合

用新的隐藏状态预测本轮输出。
flow_head 在 init 里定义成输出 6 通道:前 2 通道:delta flow
后 4 通道:info
所以这一步不是只回归位移,还顺带回归一些不确定性/混合分布参数,训练时会用于后面的 nf 相关损失。

这一行不是更新 flow 本身,而是预测“怎么从半分辨率上采样到全分辨率”。
upsample_weight(net) 会输出一个用于 convex upsampling 的 mask。
后面在 model/waft_a2.py (line 98) 的 upsample_data 里,它会被 reshape 成每个像素位置对应 3x3 邻域的权重,然后做 softmax。

当前 flow = 旧 flow + 本轮增量

这里把半分辨率结果上采样回全分辨率。
upsample_data 定义在 model/waft_a2.py (line 98)。它不是普通双线性插值,而是 learned convex upsampling:
先取低分辨率 3x3 邻域
用 weight_update 预测的 softmax 权重加权组合
得到每个高分辨率位置的值
所以这一步输出的是:
flow_up: (N, 2, H, W)
info_up: (N, 4, H, W)

把这一轮的全分辨率结果存起来。
这样做有两个用途:
训练时可以对每一轮都施加监督
推理时可以观察迭代过程,最后通常取最后一轮结果作为最终输出
收尾
先看这段代码进来之前,手里有什么
flow_predictions
每一轮的全分辨率 flow,列表长度等于 iters,每个元素形状大致是 (N, 2, H_pad, W_pad)info_predictions
每一轮的辅助输出,形状大致是 (N, 4, H_pad, W_pad)

执行完这两行后:
flow_predictions[i] 变成 (N, 2, H, W)
info_predictions[i] 变成 (N, 4, H, W)
如果有 flow_gt,就根据 info 计算 nf_predictions

如果有 flow_gt,就根据 info 计算 nf_predictions (训练用)

这里把 info 的 4 个通道拆成两部分:
weight: (N, 2, H, W)
这是两个 mixture component 的未归一化权重 logitsraw_b: (N, 2, H, W)
这是两个 component 的原始尺度参数先造一个和 raw_b 形状完全一样的全 0 张量,准备把“处理过、裁剪过范围的 log_b”写进去
注意:weight 还不是 softmax 后的概率,只是 logits。
在 WAFT 里,log_b 和 weight 不是光流本身,而是“这份光流预测有多不确定”的参数
更准确地说,它在每个像素上预测了一个“两分量混合的 Laplace 误差分布”:
p(e) = Σ_k π_k * (1 / 2b_k) * exp(-|e| / b_k)这里:
e = flow_gt - flow_pred,也就是光流误差
π_k 由 weight 决定
b_k = exp(log_b_k),由 log_b 决定
所以:
log_b 是每个分量的 log(scale),表示误差分布有多“宽”。
log_b 越大,b 越大,分布越宽,同样的误差被看得更“正常”,也就是不确定性更高。
log_b 越小,b 越小,分布越尖,对误差更敏感,也就是更自信。weight 是两个分量的未归一化权重,也可以理解成 logits。
后面通过 softmax 或 logsumexp 变成混合系数 π,表示这个像素更像由哪个分量解释。

对两个 log_b 分量做约束 ; 因为 b = exp(log_b),所以这等价于:
第 1 个分量:b >= 1,偏“宽”
第 2 个分量:b <= 1,偏“窄”

flow_gt - flow_predictions[i]是预测误差,形状 (N, 2, H, W)
.abs()变成逐像素的绝对误差
unsqueeze(2)变成 (N, 2, 1, H, W)
另一边:
exp(-log_b) = 1 / b
unsqueeze(1) 后形状是 (N, 1, 2, H, W)
两边相乘后,广播得到:
term2: (N, 2, 2, H, W)
这两个 2 分别表示:
一个是 flow 的两个分量:u, v
一个是 mixture 的两个分量
所以 term2 本质上就是:
|error| / b
误差越大,term2 越大。
尺度 b 越小,惩罚也越大。

常数项和 mixture logits
如果把某个 mixture component 的尺度记成 b,那 Laplace 分布的密度里有一项1 / (2b)
取 log 后就是:- log(2) - log(b)
bilinear_sampler

fmap2_2x:第二帧特征图,形状是 (N, C, H/2, W/2); coords2:每个位置要去第二帧哪里取样,形状是 (N, 2, H/2, W/2)
coords2 = base_grid + flow_2x 表示对第一帧位置 (x, y),去第二帧的 (x+u, y+v) 取特征
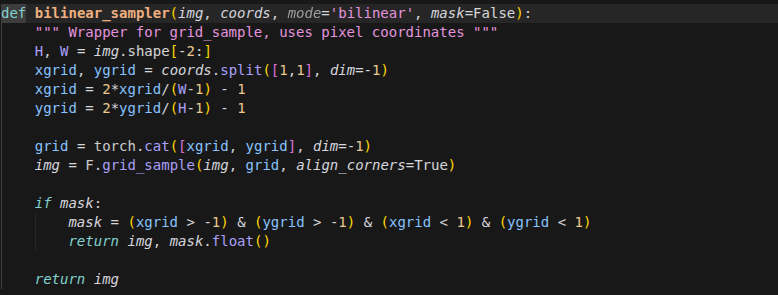
xgrid, ygrid = coords.split([1,1], dim=-1) 把最后一维的 2 个坐标拆开: xgrid:横坐标 , ygrid:纵坐标 . 它们形状都是 (N, H/2, W/2, 1)
xgrid = 2*xgrid/(W-1) - 1; ygrid = 2*ygrid/(H-1) - 1 . 所以这两行就是把: x in [0, W-1] 映射到 [-1, 1] ; y in [0, H-1] 映射到 [-1, 1]
grid = torch.cat([xgrid, ygrid], dim=-1) 得到 (N, H/2, W/2, 2) 的 grid,每个位置都是一个 (x, y) 采样点
img = F.grid_sample(img, grid, align_corners=True)
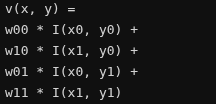
权重由 (x, y) 距离四个邻点的远近决定,越近权重越大。
refine_net
self.refine_net = VisionTransformer(args.iterative_module, self.iter_dim, patch_size=8)
refine_net 的输入 refine_inp 是一个 2D 特征图,形状大致是
(N, iter_dim, H/2, W/2)
refine_net 接手时,所有“这一轮该如何修”的证据已经准备好了
它的实现类在 model/backbone/vit.py (line 18)。本质上是一个“ViT blocks + DPT-style dense decoder”的结构。可以把它拆成三段:
PatchEmbed
Transformer blocks
DPTHead 解码回 2D 特征图
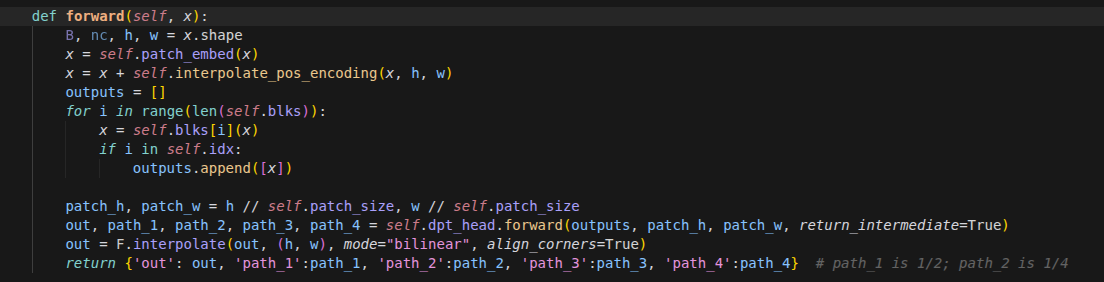
先获得 B:batch size nc:通道数 h, w:空间分辨率
x = self.patch_embed(x) : 它本质上是一个:nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) 把输入特征图按 patch_size x patch_size 切块 每个 patch 投影成一个 token 向量
x = x + self.interpolate_pos_encoding(x, h, w) , Transformer 本身不知道 token 原来在图上的哪个位置,所以需要位置编码。

这里 self.blks 是从 timm 的预训练 ViT 拿来的 transformer block 列表 model/backbone/vit.py (line 20)。
每经过一个 block: token 会和所有其他 token 做 self-attention 得到带全局上下文的新 token 表示
outputs 最后会是一个列表,大致包含 4 组 token 特征。
patch_h, patch_w = h // self.patch_size, w // self.patch_size 因为前面把输入分成 patch 了,所以这里要知道 token 在 2D 上对应的网格尺寸。
out, path_1, path_2, path_3, path_4 = self.dpt_head.forward(outputs, patch_h, patch_w, return_intermediate=True)
dpt_head 的实现来自 thirdparty/DepthAnythingV2/depth_anything_v2/dpt.py (line 117)。
这一层做的事分成两部分:
把每一层 token 从 (B, N, D) reshape 回 (B, D, patch_h, patch_w)
用多尺度融合路径把这些层逐步融合成更适合 dense prediction 的 2D 特征图
返回值里: out:主输出特征图; path_1 ~ path_4:中间多尺度路径特征 这几个 path_* 是 DPT 解码器里的不同阶段结果。 注释里说: path_1 接近较高分辨率 path_2 更低一层 等等 在 WAFT 里主要用的是 out,但保留这些中间量有利于调试或扩展。
out = F.interpolate(out, (h, w), mode="bilinear", align_corners=True)
把 out 上采样回输入分辨率 dpt_head 产出的 out 还不是和输入 x 完全同分辨率,所以这里再做一次双线性插值,恢复到最开始输入特征图的空间大小 (h, w)
dpt.py
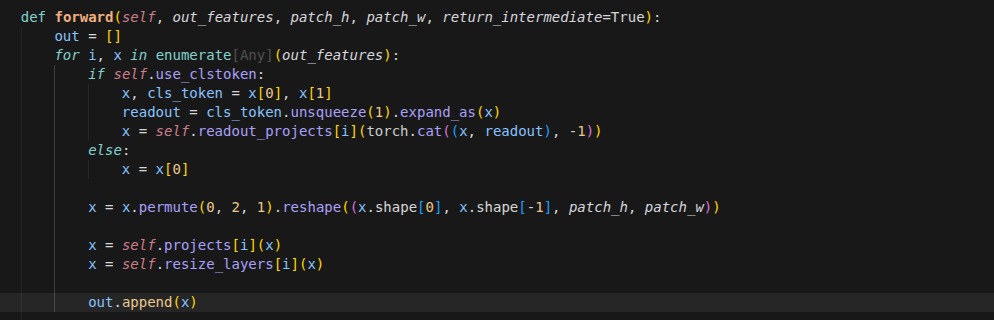
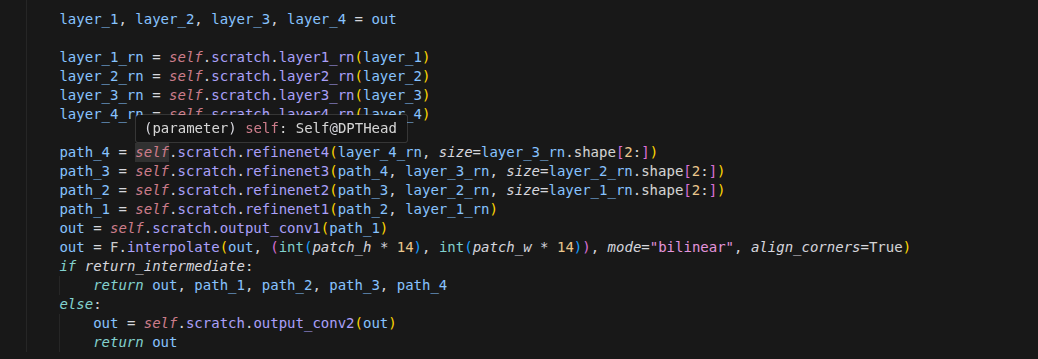
forward 输入
out_features:来自 ViT 不同层的 token 特征,通常是 4 层
每层 token 大致形状是 (B, N, D)
patch_h, patch_w:token 网格的高宽,满足 N = patch_h * patch_w
x = x.permute(0, 2, 1).reshape((x.shape[0], x.shape[-1], patch_h, patch_w))
把 token 序列 reshape 回 2D 网格
原来 x 是: (B, N, D) 先 permute(0, 2, 1) 变成: (B, D, N), 再 reshape 成: (B, D, patch_h, patch_w)
x = self.projects[i](x)
通道投影, self.projects[i] 是 1x1 conv dpt.py (line 51),作用是: 不改空间大小 只改通道数 因为不同层的 token embedding 维度相同,但 decoder 希望每层先映射到自己设定的通道数。
x = self.resize_layers[i](x)
resize_layers 在 dpt.py (line 61) 定义: 第 1 层:上采样 4 倍; 第 2 层:上采样 2 倍; 第 3 层:不变; 第 4 层:下采样 2 倍; 所以虽然这 4 层 token 原本都来自同一个 patch 网格,但这里故意把它们变成一个多尺度层级: 较浅层 -> 较高分辨率 较深层 -> 较低分辨率
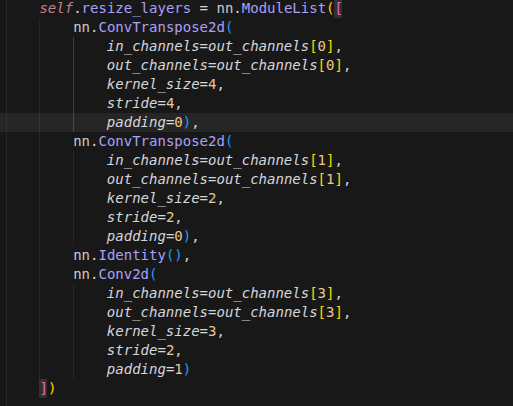
普通卷积(
Conv2d)的步长大于 1 时会使图像缩小,而转置卷积(ConvTranspose2d)的步长之所以能决定放大,是因为它的计算逻辑与普通卷积相反:它是通过在输入像素之间“插入空隙(0)”,然后再进行常规卷积来实现的
layer_1, layer_2, layer_3, layer_4 = out
layer_1:最高分辨率 layer_4:最低分辨率、语义最强
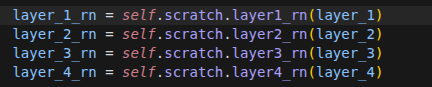
这些 layer*_rn 是 makescratch(...) 生成的 3x3 conv,定义在 util/blocks.py (line 4)。 作用是: 把四层都投影到统一的 features 通道数 为后面的融合做好准备

自顶向下融合
layer_4_rn 提供最强语义
layer_1_rn 提供最好细节
path_4 -> path_1 是逐级把高层语义“灌回”高分辨率图上
out = F.interpolate(out, (int(patch_h 14), int(patch_w 14)), mode="bilinear", align_corners=True)
再插值到更高分辨率
flow_update = self.flow_head(net)
它是一个很小的 CNN head:
3x3 conv 从 iter_dim -> 2*iter_dim 作用是看一下当前位置周围的局部邻域 因为最后的 flow 修正往往还需要一点局部空间上下文
ReLU 加非线性 1x1
conv 从 2*iter_dim -> 6 作用是把特征压成最终参数
DGGT
Aggregator.forward()
patch_tokens = self.patch_embed(images) : 用 patch_embed 把图像切成 patch,并转成 token
如果 patch_size=14,H=W=518,那么: H_patch = 518 // 14 = 37 W_patch = 518 // 14 = 37 patch_num = 37 * 37 = 1369
输出 patch_tokens: [B*S, P, C], P = patch 数量 C = embed_dim,默认 1024
camera_token = slice_expand_and_flatten(self.camera_token, B, S) register_token = slice_expand_and_flatten(self.register_token, B, S)
在 init 里它们是 self.camera_token = nn.Parameter(torch.randn(1, 2, 1, embed_dim)) self.register_token = nn.Parameter(torch.randn(1, 2, num_register_tokens, embed_dim)). (默认 num_register_tokens=4)
中间这个 2 很重要:代码注释说第 0 个用于第一帧,第 1 个用于后续帧。
slice_expand_and_flatten(...) 做的是 camera_token: [1, 2, 1, C] -> 第一帧用 token[:, 0] -> 后 S-1 帧用 token[:, 1] -> 扩展 batch -> [B, S, 1, C] -> flatten -> [B*S, 1, C] register_token: [1, 2, 4, C] -> [B*S, 4, C]
也就是说,每一帧都会多出 1 个 camera token 4 个 register token P 个 patch token
tokens = torch.cat([camera_token, register_token, patch_tokens], dim=1) 拼起来

它从 DINO backbone 取中间层特征,n=24 表示取 24 层 intermediate features。每一层的 patch feature 也会加上同样的 camera_token/register_token,然后 reshape 成: [B, S, 1+4+P, C]

如果启用了 RoPE,就给 patch 网格生成二维位置坐标。形状大概是: pos: [B*S, P, 2] 每个 patch 有一个 (y, x) 或类似的二维位置

这里 self.patch_start_idx = 1 + num_register_tokens = 5
因为 tokens 前面加了 5 个特殊 token ,所以位置编码也必须对齐到同样长度: 原 pos: [B*S, P, 2] 补特殊 token 的 pos: [B*S, 5, 2] 最终 pos: [B*S, 5+P, 2]
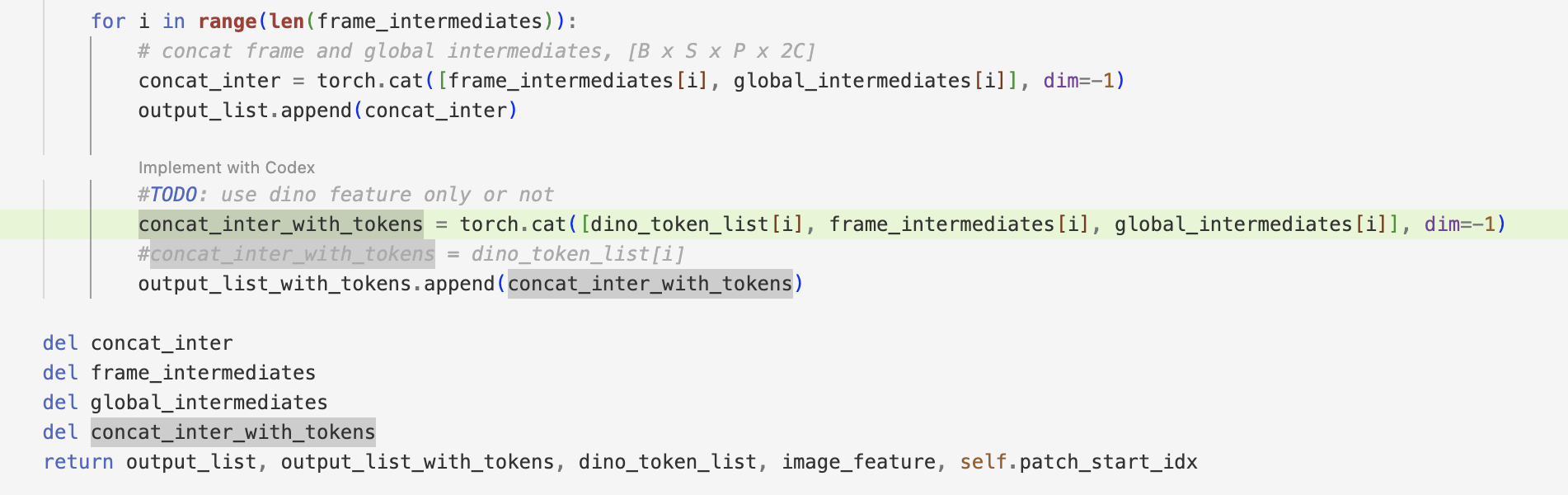
前一轮会得到 : frame_intermediates[i]: [B, S, P, C] global_intermediates[i]: [B, S, P, C] dino_token_list[i]: [B, S, P, C] (P = camera token + register tokens + patch tokens C = embed_dim,默认 1024)

是在通道维拼接 frame/global 两份特征: [B, S, P, C] + [B, S, P, C] -> [B, S, P, 2C] 这个 output_list 后面主要给这些 head 用: camera_head point_head depth_head track_head

这里多拼了原始 DINO 中间层特征
dino_token_list[i]: [B, S, P, C] frame_intermediates[i]: [B, S, P, C] global_intermediates[i]: [B, S, P, C] concat_inter_with_tokens: [B, S, P, 3C]
最后返回:
return output_list, output_list_with_tokens, dino_token_list, image_feature, self.patch_start_idx含义是:
output_list: 每层 [frame, global] 拼接特征 shape: list of [B, S, P, 2C] 给 pose/depth/point/track heads 用
output_list_with_tokens: 每层 [dino, frame, global] 拼接特征 shape: list of [B, S, P, 3C] 给 gs_head 用
dino_token_list: DINO backbone 中间层 token shape: list of [B, S, P, C] 给 dynamic/semantic heads 用
image_feature: 原始 patch feature map shape: [B, S, H_patch, W_patch, C] patch_start_idx: patch token 从第几个位置开始 默认 5,因为前面有 1 个 camera token + 4 个 register token
Motioncrafter
run.py
加载 UNet 接着是加载 geometry-motion VAE
pipe = MotionCrafterDiffPipeline.from_pretrained( ...
这里的意思不是“再加载一个新的 MotionCrafter 模型”,而是: 拿 stable-video-diffusion-img2vid-xt 这套现成视频扩散 pipeline 当壳子,再把里面最关键的 UNet 换成你前面刚加载的 MotionCrafter UNet。
也就是说,这里在复用 SVD 的基础设施,比如: vae , image_encoder , feature_extractor , scheduler pipeline 的各种辅助方法 而把“真正负责预测 MotionCrafter latent”的核心网络替换成你自己的 unet
diff 和 determ 的区别;
如果 model_type == 'diff', 走的是扩散推理流程,对应:diff_ppl.py (line 14) , 它会: 先初始化噪声 latent, 多步 denoise 每一步都调 UNet ,最后得到 latent 结果
如果不是 diff,那就是 determ: python pipe = MotionCrafterDetermPipeline ... 对应: determ_ppl.py (line 10) 它不是多步扩散,而是: 直接把 video latent 喂给 UNet , 做一次前向 , 输出结果 latent

统计 MotionCrafter 的 UNet 参数个数。
sum(p.numel() for p in geometry_motion_vae.decoder.parameters()) 统计 4D VAE 里 geometry / point map decoder 的参数量。 对应图右侧 4D VAE Decoder 里的 geometry 分支。
sum(p.numel() for p in geometry_motion_vae.decoder_2.parameters()) 统计 4D VAE 里 motion / scene flow decoder 的参数量。 对应图右侧 decoder 的 motion 分支。
sum(p.numel() for p in pipe.vae.encoder.parameters()) 统计 SVD 里 RGB video VAE 的 encoder 参数量。 也就是图左下 SVD VAE Encoder -> Video Latent 那部分。
1. 尝试开启 xFormers memory efficient attention 2. 开启 attention slicing 3. 取视频文件名 4. 读视频 5. 获取原始分辨率 6. 如果没指定推理尺寸,就用原视频尺寸 7. 检查分辨率是否合法
此处省略视频处理
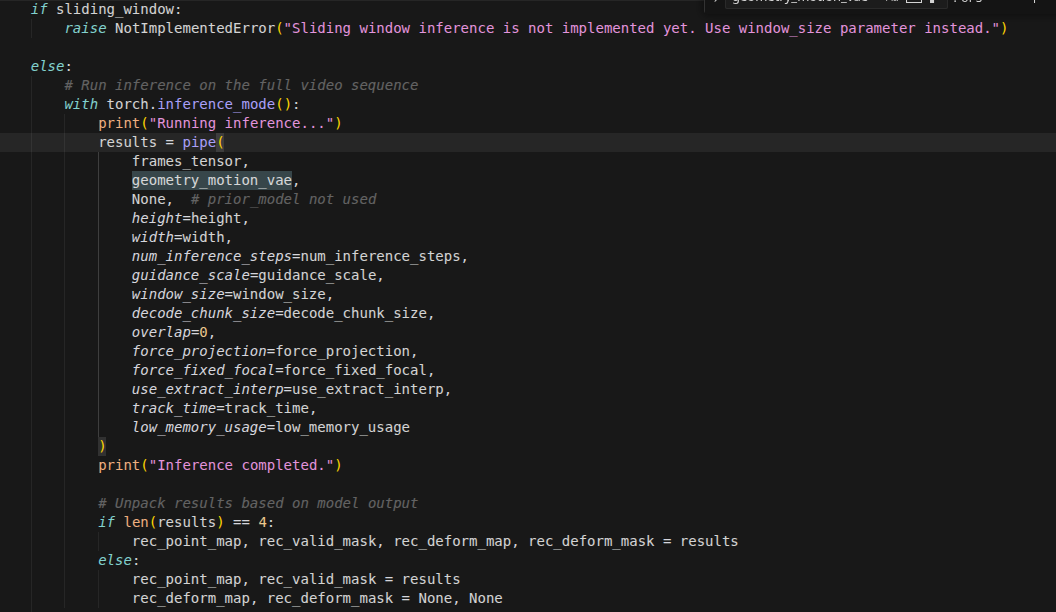
pipe 到底是谁 前面已经根据 model_type 决定了: MotionCrafterDiffPipeline 或 MotionCrafterDetermPipeline , 默认前者
frames_tensor 输入视频张量,形状是: (T, 3, H, W)
geometry_motion_vae 这是 4D VAE,用来做 latent 到输出的解码。 它负责把 pipeline 预测出来的 latent 还原成: point_map scene_flow
height=height, width=width 告诉 pipeline 当前推理分辨率是多少。
num_inference_steps=num_inference_steps 只对 diffusion 版真正有意义。 表示扩散去噪要做多少步。 步数越大,通常越慢 可能效果更稳一些
guidance_scale=guidance_scale 也是 diffusion 版的参数。 控制 classifier-free guidance 的强度。
window_size=window_size告诉 pipeline 一次处理多少帧。 如果视频比较长,pipeline 内部会按时间窗来处理。 真正做窗口切分和累积的是: base_ppl.py (line 381) base_ppl.py (line 394)
decode_chunk_size=decode_chunk_size 表示从 latent 解码成 point_map / scene_flow 时,每次解多少帧。
overlap=0 这里非常值得注意。 虽然函数参数里有 overlap,前面也做过调整,但这里实际调用时直接写死成 0。 所以当前入口实际是: 不做重叠窗口融合 每个窗口直接拼接
MotionCrafterDiffPipeline __call__ (part1)
这句是在把原始输入视频变成后面 UNet 推理真正要用的条件信息。 调用的是: base_ppl.py (line 245) 它会返回很多东西,我们一个个看。
video_embeddings 这是从视频帧提取出来的图像语义 embedding。 来源是 CLIP image encoder。
形状大致是: (1, T, 1024) 它会作为 UNet 的 encoder_hidden_states,也就是 cross-attention 的条件输入。
video_latents 这是输入视频经过 SVD VAE encoder 后得到的 latent。
形状大致是: (1, T, C, h, w) 这个就是图里说的: Monocular Video -> SVD VAE Encoder -> Video Latent 后面 diffusion UNet 会把它作为条件输入的一部分。

它的作用是根据当前序列长度,修正窗口参数。 逻辑很简单: 如果 num_frames <= window_size 那就把 window_size 直接改成 num_frames overlap = 0 然后算: stride = window_size - overlap

这句是在生成 diffusion 推理时要走的时间步序列。 retrieve_timesteps(...) 来自 diffusers 的 SVD pipeline。 它会根据: 当前 scheduler 你指定的 num_inference_steps 生成一组真正用于采样的 timestep。 你可以把它理解成: “这次 diffusion 采样要走哪几个 denoise step” 比如你传 num_inference_steps=5,这里就会准备对应的 5 个采样时间点。
SVD VAE encoder

h = self.encoder(x) 这一步是普通的卷积编码器前向。 作用: 把输入图像/point map x 经过多层下采样卷积 变成一个更小、更抽象的特征图 h
如果 x 形状大概是: (B, C, H, W) 那 h 一般会变成更小的空间分辨率,比如: (B, C_hidden, H/8, W/8)
moments = self.quant_conv(h) 这一步很关键。 quant_conv 通常是一个 1x1 卷积,它不是为了进一步提语义,而是为了把 h 投影成 高斯分布参数。
在 VAE 里,我们不直接输出一个 latent z,而是输出一个分布: q(z|x) = N(mu, sigma^2) 所以 moments 里实际装的是两部分东西: mean,也就是 mu , logvar,也就是 log(sigma^2) 通常会在 channel 维上拼起来: moments = [mu, logvar] 所以如果 latent 通道数是 4,那 moments 的通道数通常就是 8: 前 4 个通道是 mean 后 4 个通道是 logvar
posterior = DiagonalGaussianDistribution(moments) 这一步是把刚才那坨 moments 包装成一个“可操作的高斯分布对象”。
为什么叫 DiagonalGaussianDistribution? 因为它假设协方差矩阵是对角的,也就是各 latent 维度彼此独立: z_i ~ N(mu_i, sigma_i^2) 没有显式建模不同通道之间的协方差。 这
个对象内部一般会做这些事: 把 moments 拆成: mean logvar 对 logvar 做裁剪,避免数值爆炸 计算: std = exp(0.5 * logvar) var = exp(logvar) 提供几个常用接口: posterior.sample():从分布里采样 posterior.mode():取均值 mean posterior.kl():算 KL 散度

MotionCrafterDiffPipeline __call__ (part2)
M~ _inference_step (part1)
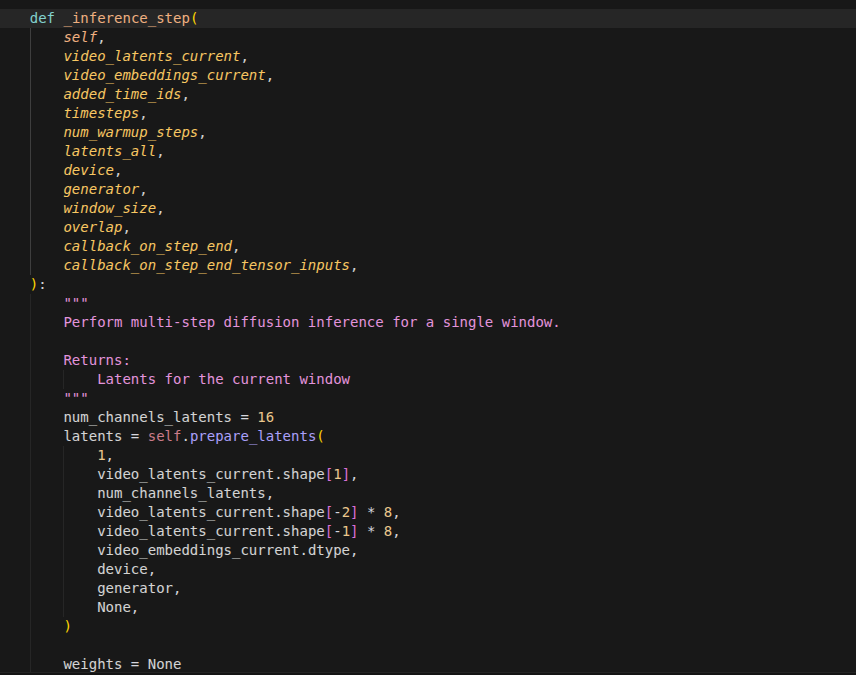
给当前窗口先随机初始化一个 latent,然后沿着 timesteps 一步一步去噪,最后得到这个窗口的 4D latent 结果。
video_latents_current 当前窗口对应的 video latent 条件。 它来自 SVD VAE encoder。 也就是图里的: Monocular Video -> SVD VAE Encoder -> Video Latent 当前窗口版本。
video_embeddings_current 当前窗口每一帧的语义 embedding,来自 CLIP/image encoder。 后面会作为 UNet 的 encoder_hidden_states
timesteps 这次 diffusion 采样真正要走的时间步列表。 比如 5-step、25-step,都会在这里展开成一个序列。
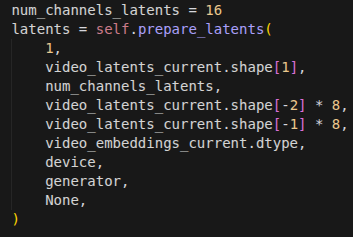
这是从 diffusers / SVD pipeline 继承来的辅助函数。 作用是: 根据 batch size、帧数、空间分辨率 在指定设备上 生成一份初始高斯噪声 latent 也就是 diffusion 采样的起点: z_T ~ N(0, I)
1 , batch size
video_latents_current.shape[1], 这是当前窗口帧数。 因为 video_latents_current 的形状大致是: (1, T_window, C, h, w) 所以 shape[1] 就是当前窗口的时间长度 T_window。 也就是说,这里会为窗口里每一帧准备对应的 latent 噪声。
video_latents_current.shape[-2] * 8, video_latents_current.shape[-1] * 8, 这两个是在把 latent 空间尺寸反推回像素空间尺寸。 因为 video_latents_current 是 VAE latent,空间分辨率通常比原图小 8 倍。 所以这里乘回 8,告诉 prepare_latents(...): 原图高大概是多少 原图宽大概是多少 然后函数内部会再根据 VAE scale 去生成正确分辨率的噪声 latent。
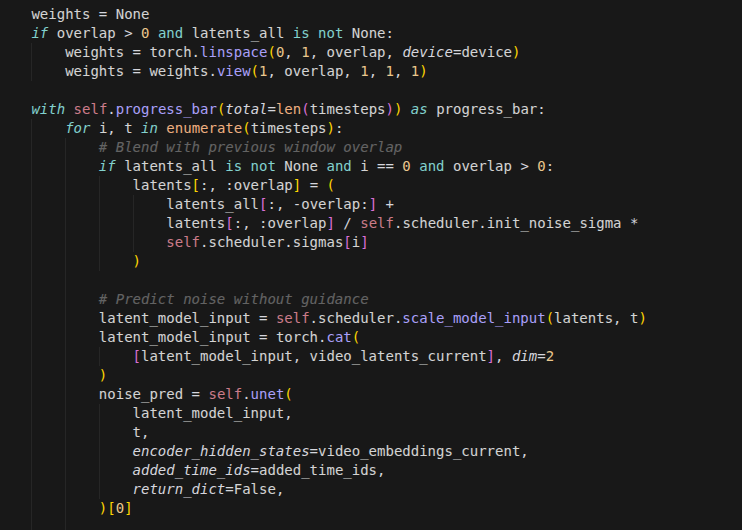
它在做三件事: 如果有窗口重叠,先把当前窗口开头和前一个窗口末尾接起来 把当前 latent 整理成 UNet 能吃的输入 调 UNet 预测噪声

意思是: 一共跑 len(timesteps) 个 diffusion step
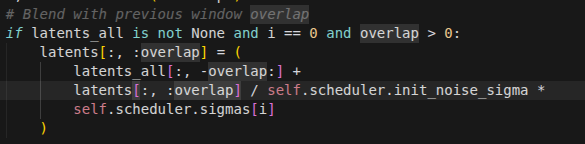
把当前窗口开头那几帧的初始噪声 latent,和前一个窗口末尾那几帧的结果接上。
latents[:, :overlap] / self.scheduler.init_noise_sigma * self.scheduler.sigmas[i] 是在把当前初始噪声按 scheduler 当前 step 的噪声尺度重新调整。 因为 diffusion 里的噪声不是随便加的,而是必须符合当前 timestep 对应的噪声强度。

说明送进 UNet 的输入不是只有“当前待去噪 latent”,而是把它和输入视频的 latent 条件拼在一起。 这里按 dim=2 拼,说明张量形状大致是: (B, T, C, H, W) 所以 dim=2 是通道维。
这正对应论文图里的思路: 一边是当前要去噪的 4D latent 一边是从输入视频提取出来的 video latent 两者 channel-wise concat 后送进 Diffusion UNet
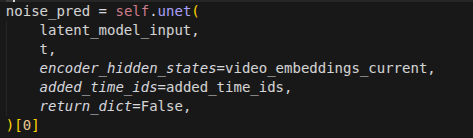
这就是当前 diffusion step 的核心前向
UNet 输入包括四部分:
latent_model_input 也就是刚才拼好的: noisy latent video latent condition
t 当前 diffusion timestep
encoder_hidden_states=video_embeddings_current 当前窗口每帧的语义 embedding,来自 CLIP/image encoder。 这是 cross-attention 条件。
added_time_ids=added_time_ids 额外时间条件,比如: fps motion bucket id noise augmentation strength
unet.py
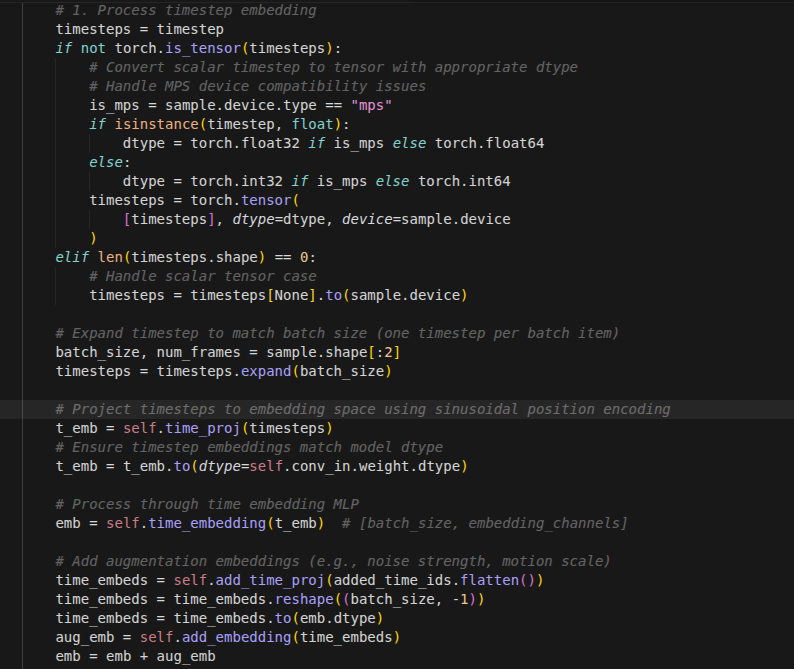
timesteps = timesteps.expand(batch_size) 把 timestep 扩成每个 batch item 一份, 意思是: 同一个 batch 里的所有视频样本,都使用相同的 diffusion timestep。
t_emb = self.time_proj(timesteps) 这是把整数/浮点 timestep 投影成一个高维时间 embedding。 通常它内部做的是类似 sinusoidal timestep embedding 的操作。 也就是把一个标量时间步 t 变成一个向量表示。
emb = self.time_embedding(t_emb) # [batch_size, embedding_channels] 再过一个 MLP,把 timestep 特征进一步映射成网络真正用的 conditioning 向量 ; 输出 emb 的形状大致是: (batch_size, embedding_channels)
处理 added_time_ids
两条条件分支相加 emb = emb + aug_emb
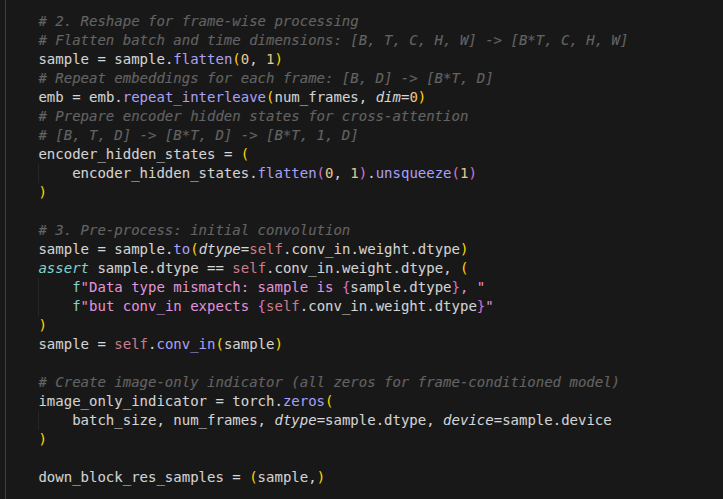
把视频 UNet 的输入从“按视频组织”改成“按帧组织”,然后送进卷积主干的第一层。
sample = sample.flatten(0, 1) 原始 sample 形状是: [B, T, C, H, W] 这句把前两维 B 和 T 合并,变成: [B*T, C, H, W] (先把每一帧当成一个独立图像样本送进卷积层。 这在视频 UNet 里很常见,因为底层卷积通常还是按 2D 图像来做,时间交互是在更高层模块里处理。)
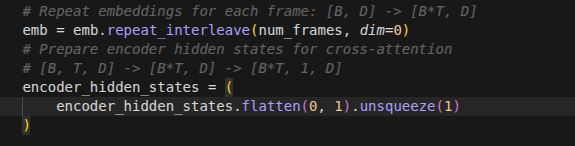
emb = emb.repeat_interleave(num_frames, dim=0) 前面 emb 的形状是: [B, D] 它表示每个视频样本一个全局时间条件向量。 但现在 sample 已经展平成了 B*T 帧,所以 emb 也得跟着扩展成每一帧一份: [B*T, D] ; 然后 .unsqueeze(1),变成: [B*T, 1, D] (因为 cross-attention 层通常期望输入形状像: [batch, seq_len, hidden_dim])

这句是在把输入图像张量的 dtype 和第一层卷积 conv_in 的权重 dtype 对齐。 比如如果 conv_in.weight.dtype 是 torch.float16,那这里也把 sample 转成 float16。

self.conv_in 是一个 nn.Conv2d(3x3 的卷积核)。输入形状在这之前已经被整理成: [B*T, C_in, H, W] 输出通常会变成: [B*T, C_hidden, H, W] 在这类 UNet 里,C_hidden 常常是 320 这种内部宽度。

这是为后面的 UNet skip connection 准备的缓存容器。 UNet 在 downsampling 阶段会保存很多中间特征,后面 upsampling 阶段要拿回来做 skip connection。 这里先把当前 conv_in 输出作为第一个残差样本存进去。 后面每过一个 down block,都会继续往这个 tuple 里追加。
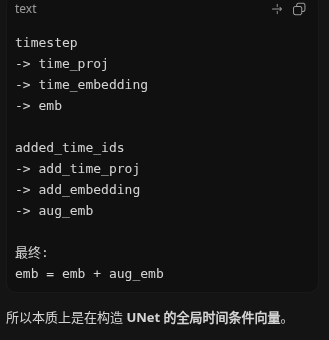
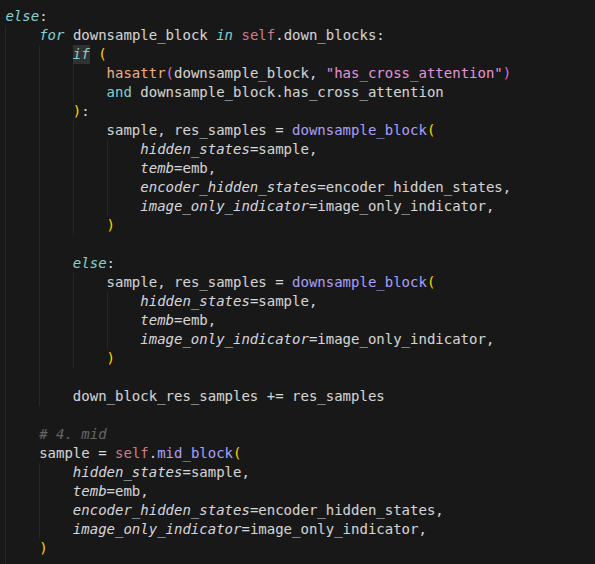
对于 MotionCrafter 推理来说,通常走的就是这个分支

UNet 的 encoder 路径由多个 down_blocks 组成。 每个 block 会逐渐提取更高层特征,通常也会伴随空间分辨率下降。
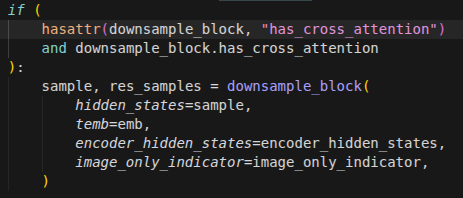
判断这个 block 是否带 cross-attention , 对于 带 cross-attention 的 downsample_block .
hidden_states=sample 当前主干特征图。 形状大致是: [B*T, C, H, W] 这是上一个 block 的输出,也是当前 block 的输入。
temb=emb 时间条件 embedding。 它前面已经由: diffusion timestep added_time_ids 融合得到。
encoder_hidden_states=encoder_hidden_states cross-attention 的条件输入。 这里通常是每帧对应的语义/图像 embedding,形状大致是: [B*T, 1, D] ; 如果 block 内含 cross-attention,它就能用这个外部条件来调制当前特征
返回值:sample, res_samples 这个 block 返回两样东西: sample 继续往下传的主特征图 res_samples 这一层产生的 skip features / residual features,后面 upsampling 路径会拿来做 skip connection
不带 cross-attention 的 downsample_block 略
down_block_res_samples += res_samples 这句是在把当前 block 生成的 skip features 累积起来。
它通常处理的是最深层、最抽象的特征图。因为此时空间分辨率已经比较小,但通道数高、语义浓
mid_block 的输入
hidden_states=sample 来自最后一个 down block 的输出
temb=emb 时间条件
encoder_hidden_states=encoder_hidden_states 外部条件,用于 cross-attention
image_only_indicator=image_only_indicator 视频/图像模式辅助标记
mid_block 的输出 这里没有像 down block 一样返回 res_samples,因为它是中间层,不负责给 decoder 留 skip connection。 它只返回一个新的 sample,然后后面就会进入 up_blocks。
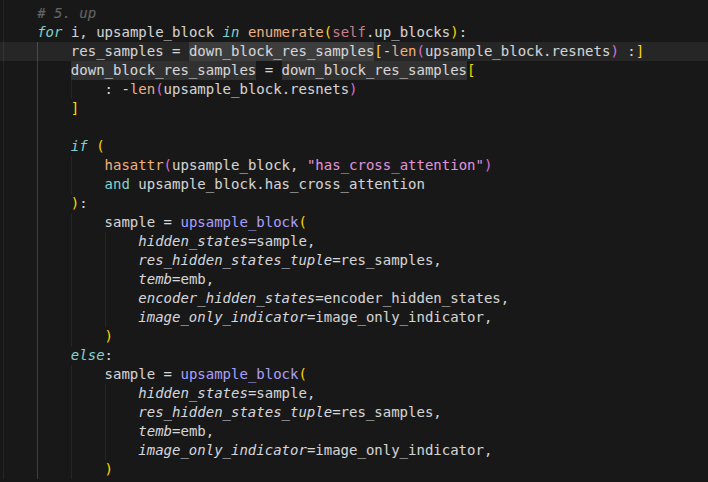
一边把当前深层特征逐步上采样恢复分辨率,一边把 encoder 侧存下来的 skip features 接回来

UNet decoder 由多个 up_blocks 组成。它们会按顺序把最深层特征逐步恢复到更高分辨率。

现在 decoder 要往回走,就得把和当前 up block 对应的那几份特征取出来 . 为什么是: -len(upsample_block.resnets) ? 因为一个 up block 里通常包含若干个 resnet 子层,它会需要同样数量的 skip 特征来配对。
刚才已经把当前 block 需要的 skip features 取出来了,这里就把它们从总缓存里移除。 这样下一个 up block 再来时,就会继续取更早一层的 skip features。
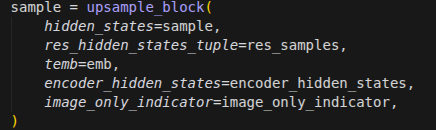
这是当前 decoder block 的主调用。
hidden_states=sample 这是当前 decoder 主干特征,也就是从更深层传上来的特征图。
这是当前 up block 要接的 skip features。 它们来自 encoder 侧对应层。 这是 U-Net 的核心机制之一: 把高层语义特征和早期局部细节结合起来。 如果没有 skip connection,decoder 只能依赖最深层特征,很容易丢空间细节。
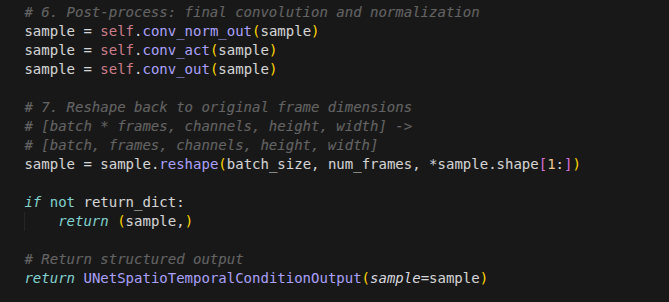

这是输出头的第一步:归一化。
内部 conv_norm_out 本质上就是一个: torch.nn.GroupNorm
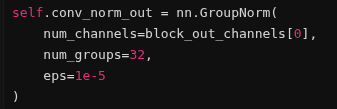
如果输入 sample 形状是: [B*T, C, H, W] 那么 GroupNorm(32, C) 会: 把 C 个通道分成 32 组 对每一组里的特征做归一化 再乘可学习参数 weight 再加可学习参数 bias

这是输出头的激活函数(SiLU 激活函数)。

这一步才是真正的最终预测层。 它会把 UNet 内部的 hidden channels 映射到目标输出通道数。 比如在 MotionCrafter 里,前面训练器里会把 conv_out 改成输出 8 通道: 前 4 通道:geometry / point-map latent 后 4 通道:motion / scene-flow latent
现在它的形状还是: [batch * frames, channels, height, width]

恢复成: [B, T, C, H, W]
CrossAttnDownBlockSpatioTemporal
hidden_states 当前主干特征图,来自上一个 block; temb 时间条件 embedding 也就是 timestep + added_time_ids 融合出来的向量; encoder_hidden_states cross-attention 的条件输入 通常来自图像/视频 ; embedding image_only_indicator 辅助视频模式标志
output_states = () 这里初始化一个 tuple,用来保存当前 block 内部每个阶段的输出。 后面这些输出会作为 skip connection 特征返回给 UNet 外层。
把 resnet 和 attention 成对遍历
self.resnets
1. 先过空间残差块 输入此时大致形状是: [B*T, C, H, W] 这里还没有显式展开时间结构,而是把每帧当成独立图像处理。
2. 把扁平化视频恢复成带时间维的 5D 张量 , 把: [B*T, C, H, W] 变成: [B, C, T, H, W] ; 过时间残差块 , 这个模块可以看到时间维,学习相邻帧之间的变化,而不是只看每帧内部
3. 用 time_mixer 混合空间版和时间版特征 现在有两套特征: x_spatial 只经过空间残差块的特征 更保留每帧局部空间结构 x_temporal 再经过时间残差块后的特征 更包含时序变化信息 time_mixer 会按 alpha(本质上就是一个可学习/固定的混合系数模块) 把它们混起来: x = alpha x_spatial + (1 - alpha) x_temporal
attn
空间 block + 时间 block
保存每一层输出到 output_states
如果有 downsampler,再做一次空间下采样
M~ _inference_step (part2)
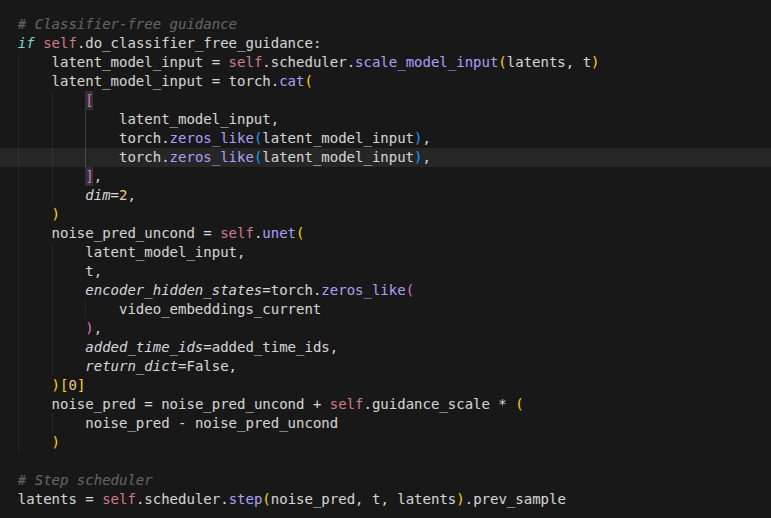
再额外跑一次“无条件”UNet预测,然后把“有条件预测”和“无条件预测”线性组合,增强条件引导效果。
前面正常条件分支里,输入大概是: [当前 noisy latent, video_latents_current] 而这里无条件分支直接构造成: [latent_model_input, 0, 0] 也就是把条件部分清零。
又 , encoder_hidden_states=torch.zeros_like(video_embeddings_current) , 也就是说,cross-attention 的外部条件 embedding 也被去掉了。 所以这次前向就是一个真正的“无条件”预测: 没有视频 latent 条件 没有视频 embedding 条件 只有当前 latent 和 timestep 自身

等价于 noise_pred = (1 - s) noise_pred_uncond + s noise_pred_cond

然后交给 scheduler 更新 这句是 diffusion 的标准更新。 输入: noise_pred 现在已经是 CFG 增强后的最终预测, t 当前 timestep, latents 当前状态 输出: prev_sample 更干净一步的 latent,也就是下一个 timestep 要继续用的 latent
1