
Chapter2 :Operating -System Structures
2.1 操作系统服务 (Operating-System Services)
操作系统为程序的执行提供了一个环境,并向程序和用户提供了一系列服务。这些服务可以大致分为以下几类
用户界面
程序执行 (Program Execution): 操作系统必须能够将程序加载到内存中并运行它,以及正常或异常地终止程序。
I/O 操作 (I/O Operations)
文件系统操作 (File-System Manipulation)
通信 (Communications)
可以在同一台计算机上的进程之间进行,也可以在网络上不同计算机的进程之间进行。主要方式有share memory和message bypassing。
错误检测
资源分配
日志 (Logging)
保护与安全 (Protection and Security)
确保对系统资源的访问是受控的(保护),并保护系统免受外部或内部的恶意攻击(安全)
2.2 用户与操作系统接口 (User and Operating-System Interface)
用户主要通过以下几种接口与操作系统进行交互
CLI, GUI, Touch-Screen Interface
2.3 系统调用 (System Calls)
定义: 系统调用为操作系统提供的服务提供了编程接口
当一个程序需要操作系统的服务时(例如,读取文件),它会执行一个系统调用,将控制权和请求传递给操作系统。操作系统完成任务后,再将控制权交还给程序
应用程序编程接口 (API):
在实际编程中,程序员通常不直接编写系统调用代码。
他们使用更高级的 API(例如 POSIX API, Windows API)。
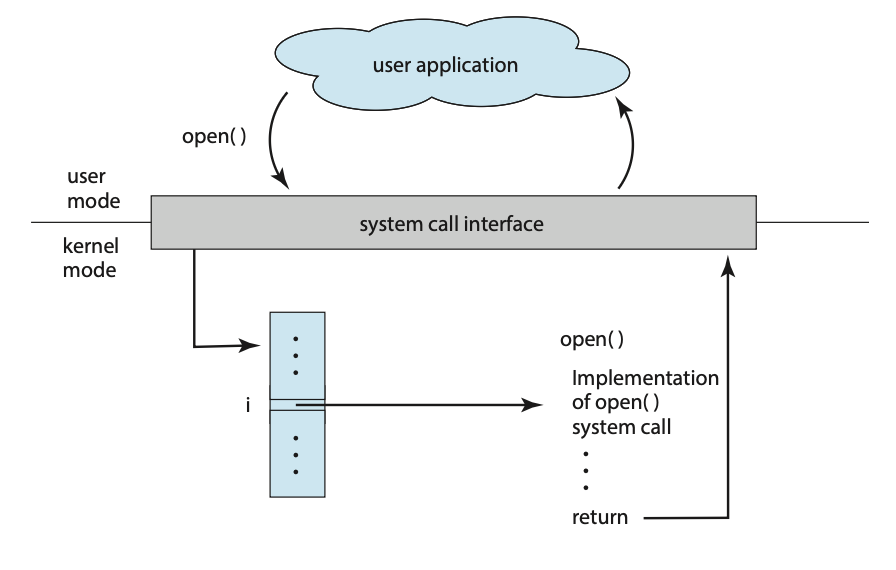
图中展示了一个用户应用程序从用户模式(user mode)通过系统调用接口调用open()函数。进入内核模式(kernel mode)后,接口通过一个索引 i 在系统调用表中查找并执行open()系统调用的具体实现,然后返回结果。
如何将参数传递给操作系统
pass the parameters in registers.
block method , 将参数存储在内存的一个块或表中,然后将该块的地址作为一个参数在寄存器中传递
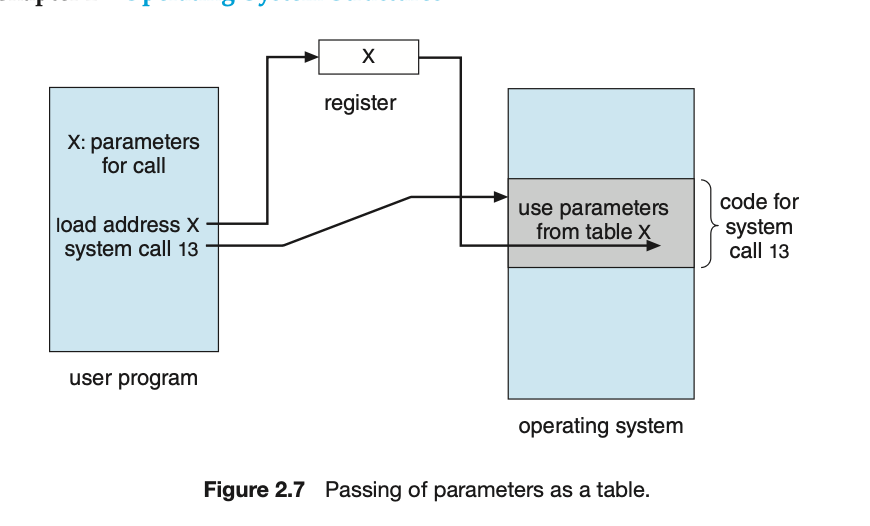
stack method
系统调用的类型 (Types of System Calls)
进程控制 (process control)、文件管理 (file management)、设备管理 (device management)、信息维护 (information maintenance)、通信 (communications) 和 保护 (protection)
2.7 Operating-System Design and Implementation
机制与策略 (Mechanisms and Policies)
策略和机制的分离对于灵活性非常重要。策略可能会随着地点的变化或时间的推移而改变。在最坏的情况下,对策略的每次更改都需要重新修改底层机制。一个通用的机制应该足够灵活,以适应各种策略。如果策略改变,人们只需要重新定义某些参数即可
基于微内核的操作系统(在2.8.3节讨论)将机制和策略的分离推向了极致,它通过实现一组非常基础的构建块来实现。这些块几乎没有策略,允许更高级的机制和策略通过用户创建的内核模块被添加进来。
相比之下,商业操作系统Windows,在三十多年的发展中,将机制和策略紧密地结合在一起。微软一直将策略强制应用于整个系统,并跨所有使用Windows操作系统的设备。所有应用程序都有相似的界面,因为界面本身是内置在内核和系统库中的。苹果公司为其macOS和iOS操作系统采取了类似的策略。
2.8 Operating-System Structure
2.8.1 单体结构 (Monolithic Structure)
组织操作系统的最简单结构就是根本没有结构。也就是说,内核的所有功能都被放置在一个地址空间中的单个静态二进制文件中
这种有限结构的一个例子是最初的UNIX操作系统,它由两部分组成:内核和系统程序。内核被进一步分离为一系列与硬件交互的接口和设备驱动程序。
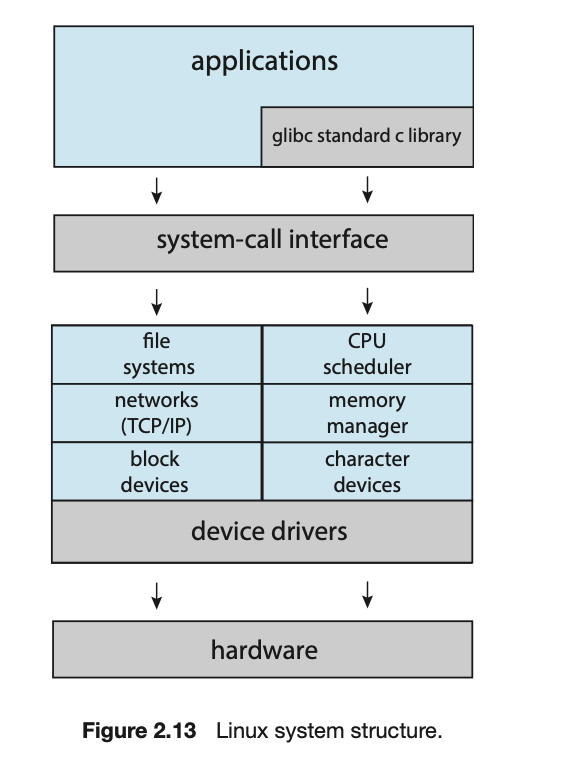
尽管实现了单体内核的简单性,但它们很难实现和扩展。尽管如此,单体内核确实有一个明显的性能优势:系统调用接口和内核内的通信开销很小,因此单体内核的速度和效率解释了为什么它们仍然在UNIX、Linux和Windows操作系统中
2.8.2 分层方法 (Layered Approach)
单体方法通常被称为一个**紧密耦合(tightly coupled)的系统,因为一个组件的改变可能会对系统的其他部分产生广泛的影响。我们可以设计一个松散耦合(loosely coupled)**的系统。这样一个系统被划分为独立的、更小的组件,这些组件具有特定的、有限的功能。所有这些组件一起构成了内核。
一种方法是将操作系统分解成多个层次(层级)。底层(第0层)是硬件;最高层(第N层)是用户界面。
一个典型的操作系统层——比如说第M层——由数据结构和一系列例程组成,这些例程可以被更高层的层级(第M+1层)调用。第M层,相应地,可以调用更低层层级(第M-1层)的操作。
分层系统已经成功地应用于计算机网络(例如TCP/IP)和Web应用程序。然而,很少有操作系统使用纯粹的分层方法。一个原因在于定义每一层的适当功能所面临的挑战。此外,这种方法的整体性能很差,因为通过多层来请求一个操作系统服务会产生开销。一些操作系统在结构上比其他操作系统更分层。
2.8.3 微内核 (Microkernels)
这种方法通过从内核中移除所有非必需的组件,并将它们实现为用户级程序来构建操作系统
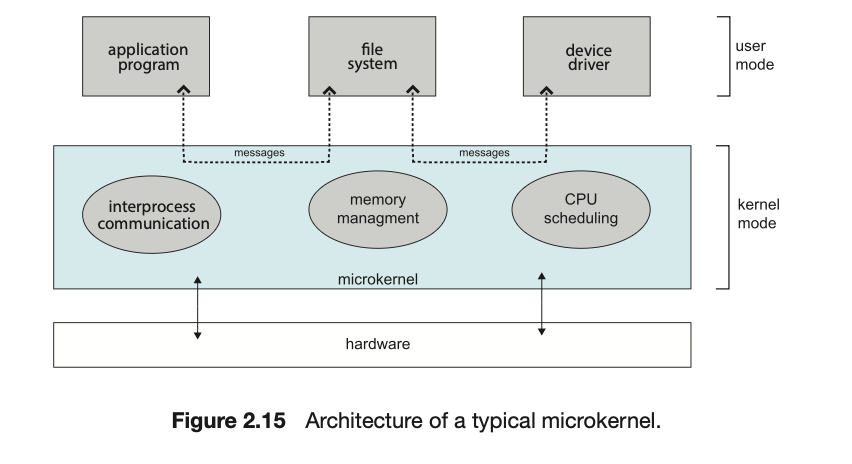
微内核的主要功能是提供客户端程序和在用户空间中运行的各种服务之间的通信。客户端程序和各种服务之间的通信是通过在2.3.3.5节中描述的消息传递进行的。例如,如果客户端程序希望访问一个文件,它必须与文件服务器进行交互。客户端程序和服务从不直接交互。它们通过与微内核交换消息来进行间接通信。
微内核方法的一个好处是它扩展了操作系统。所有新服务都是在用户空间添加的,因此不需要修改内核。当内核需要修改时,由于微内核是一个更小的内核,因此所需的更改往往较少。由此产生的操作系统也更容易从一种硬件架构移植到另一种。微内核还提供了更高的可靠性和安全性,因为大多数服务作为用户(而不是内核)进程运行。如果一个服务失败,操作系统的其余部分保持不受影响。
不幸的是,微内核的性能可能会因系统功能开销而受到影响。由于消息必须在用户空间中的服务和内核之间复制,因此通信开(销)会增加
2.8.4 模块 (Modules)
也许目前用于操作系统设计的最佳方法是使用可加载内核模块(loadable kernel modules, LKMs);让内核提供核心服务,而其他服务则在内核运行时动态实现
LKMs允许Linux拥有动态和模块化的特性,同时保持了单体系统的性能(通信等效率)。
2.8.5 混合系统 (Hybrid Systems)
在实践中,很少有操作系统采用单一、严格定义的结构。相反,它们结合了不同的结构,形成了解决性能、安全和可用性问题的混合系统。例如,Linux是单体的,因为将所有内容放在一个地址空间中提供了非常高效的性能。然而,它也是模块化的,所以可以动态地将新功能添加到内核中。
2.9 Building and Booting an Operating System
2.9.2 系统引导 (System Boot)
当一个操作系统生成后,它必须可供使用。它必须被安装在硬盘上,或者可以从硬盘上加载。但硬件如何知道内核在哪里,或者如何加载内核呢?加载内核的过程由存储在硬件固件中的一个小程序来处理,这个程序被称为自举程序(bootstrap program)或引导加载程序(boot loader)。在大多数系统上,引导过程如下:
自举程序或引导加载程序定位内核。
内核被加载到内存中并启动。
内核初始化硬件。
根文件系统被挂载。
一些计算机系统使用一个多阶段的引导过程。当计算机首次通电或重启时,一个位于固件(称为BIOS)中的小型引导加载程序boot loader会运行。这个初始引导加载程序通常只做一件事,即将第二个引导加载程序加载进来,而第二个引导加载程序位于磁盘上的固定位置,这个位置被称为引导块(boot block)。存储在引导块中的程序足以将整个操作系统加载到内存中并开始执行。通常,它是一个简单的代码(例如,它可能只是一个磁盘块的长度),它知道磁盘的地址和剩余引导程序的长度。
许多最近的计算机系统已经用**统一可扩展固件接口(Unified Extensible Firmware Interface, UEFI)**取代了基于BIOS的引导过程。UEFI有几个优势,包括比BIOS更好地支持64位系统和更大的磁盘。也许UEFI最大的优势是它是一个单一的、完整的引导管理器,因此比传统的BIOS引导过程更快。
无论从BIOS还是UEFI引导,引导程序都可以执行各种任务。除了加载程序到内存中,它还运行诊断程序来确定机器的状态——例如,检查内存和CPU。如果诊断通过,程序可以继续引导过程。引导程序还可以初始化系统的所有方面,从CPU寄存器到设备控制器和内存内容。只有到这时,它才会启动操作系统。对于操作系统来说,这个点就是挂载根文件系统(mount the root file system)。
2.10 Q&A
系统调用为操作系统提供的服务提供了接口。应用程序编程接口(API)用于访问系统调用
标准C库为UNIX和Linux系统提供了系统调用接口。
链接器将可重定位的目标模块组合成一个单一的二进制可执行文件。加载器将可执行文件加载到内存中,使其有资格在可用的CPU上运行。
Chapter3 : Processes
3.1 Concept
3.1.1 The process
一个进程是一个正在执行的程序。一个进程的状态由 程序计数器(program counter)的值和处理器寄存器的内容来表示。进程的内存布局通常分为多个部分,如图3.1所示。这些部分包括:
文本段 (Text section) — 可执行代码
数据段 (Data section) — 全局变量
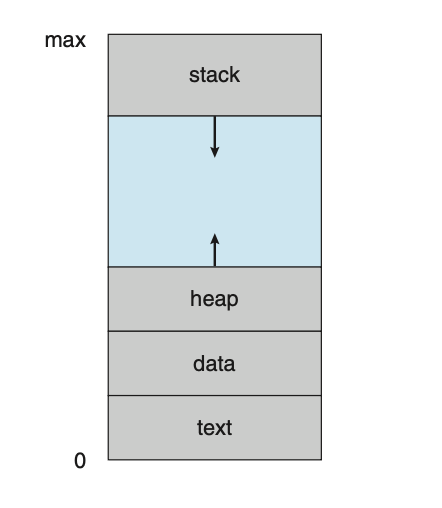
进程在内存地址空间中的布局。从低地址(0)到高地址(max)依次是:文本段(text),数据段(data),堆(heap)(向上增长),栈(stack)(向下增长)。
需要注意的是,文本和数据段的大小是固定的,而堆和栈段在程序执行期间可以动态地增长和收缩。每次调用函数时,一个 活动记录(activation record) 会被推送到栈中,其中包含函数的参数、局部变量和返回地址;当从函数返回时,这个活动记录会从栈中弹出。类似地,当通过
malloc()动态分配内存时,堆会增长;当通过free()释放内存时,堆会收缩。尽管栈和堆段是分开的,但它们朝对方增长。如果它们重叠,系统必须确保它们不会相互覆盖。
3.1.2 Process State
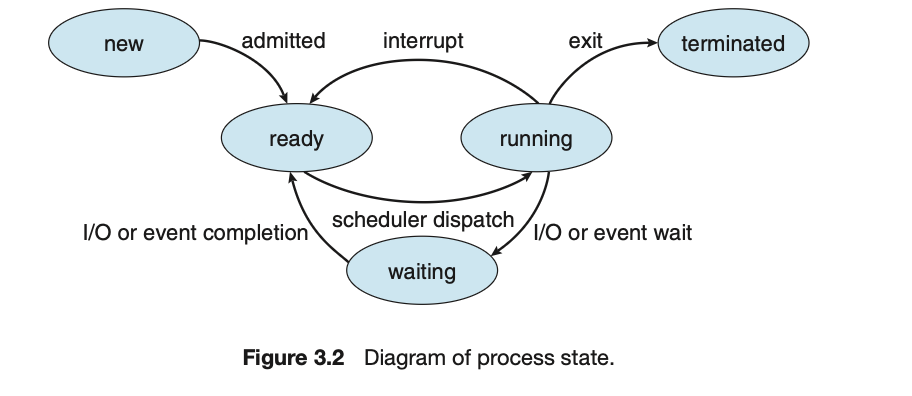
新建 (New): 进程正在被创建。
运行 (Running): 指令正在被执行。
等待 (Waiting): 进程正在等待某个事件的发生(例如I/O完成或收到一个信号)。
就绪 (Ready): 进程正在等待被分配给一个处理器。
3.1.3 进程控制块 (Process Control Block)
包含信息: 进程状态 (Process state) , 程序计数器 (Program counter) , CPU寄存器 (CPU registers) , CPU调度信息 (CPU-scheduling information) , 内存管理信息 (Memory-management information) , 记账信息 (Accounting information) , I/O状态信息 (I/O status information)
3.1.4 线程 (Threads)
允许一个进程拥有多个执行线程,从而可以一次执行多个任务。这一特性在多核系统上尤其有益,多个线程可以并行运行。在一个多线程的文字处理器上,例如,一个线程可以管理用户输入,而另一个线程可以运行拼写检查。在支持线程的系统上,PCB被扩展以包含每个线程的信息。其他变化也是必要的。
3.2 进程调度 (Process Scheduling)
多道程序设计(multi-processing, Time-sharing 本身就是种 multi-processing )的目标是在任何时候都有某个进程在运行,以最大化CPU的利用率。分时共享(Time Sharing)的目标是如此频繁地切换CPU核心,以便用户在程序运行时可以与之交互。为了实现这些目标,进程调度程序(process scheduler)从一组可用进程中为程序在一个CPU核心上的执行选择一个可用的进程。每个CPU核心一次可以运行一个进程。
对于一个单CPU核心的系统,任何时候都不会有超过一个进程在运行。然而,在一个多核系统上,可以同时运行多个进程。如果进程比核心多,多余的进程将不得不等待,直到一个核心空闲出来并可以被重新调度。
大多数进程可以被描述为I/O密集型或CPU密集型。一个I/O密集型进程(I/O-bound process)**是那种花在I/O上的时间比花在计算上的时间多的进程。
3.2.1 调度队列 (Scheduling Queues)
当进程进入系统时,它们被放入一个 就绪队列(ready queue) 中。它们在这个队列中等待,直到被选中在一个CPU核心上执行。这个队列通常存储为一个链表。就绪队列的头部包含指向链表中第一个PCB的指针,每个PCB都包含一个指向就绪队列中下一个PCB的指针。
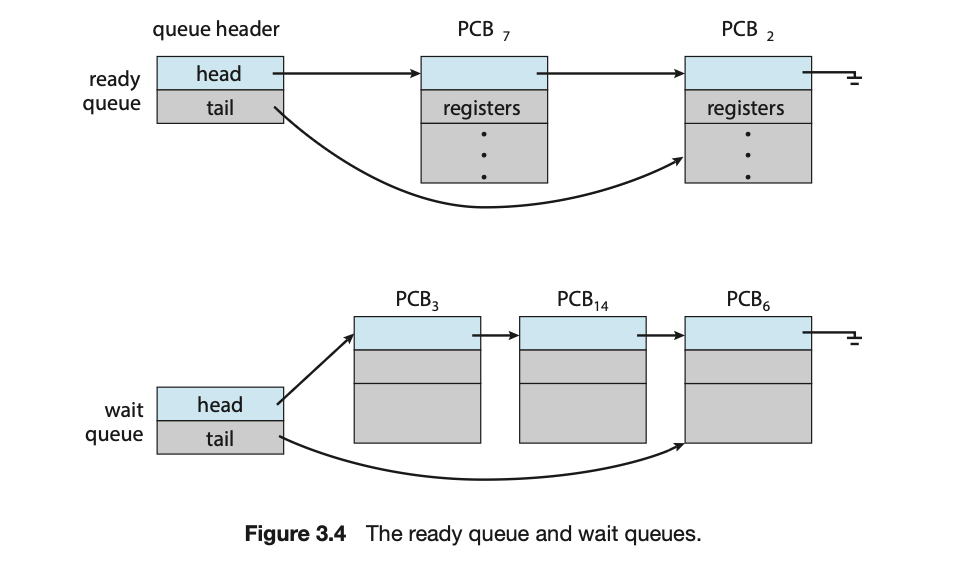
系统中还存在其他队列。当一个进程被分配给一个CPU核心并正在执行时,它可能会发出一个I/O请求,然后被放入一个I/O等待队列中。当一个进程因为特定事件(例如I/O请求完成)而等待时,它会被中断。假设一个系统有一个专用的磁盘驱动器,那么它会有一个等待该磁盘驱动器的进程队列。因此,每个设备都有自己的设备队列。
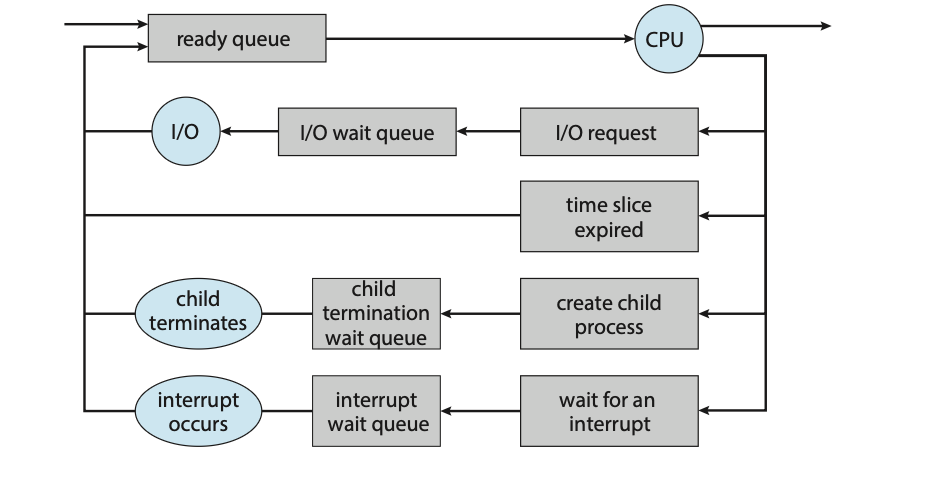
进程调度的常见表示是排队图(queuing diagram),如图3.5所示。每个矩形框代表一个队列。两种类型的队列是就绪队列和一组等待队列。圆圈代表为队列提供服务的资源,箭头表示系统中的进程流。
一个新进程最初被放入就绪队列中。它在那里等待,直到被选中执行或被分派(dispatched)。一旦进程被分配给一个CPU核心并正在执行,可能会发生以下几种事件之一:
进程可能发出一个I/O请求,然后被放入一个I/O等待队列。
进程可能创建一个新的子进程,然后被放入一个等待队列,直到其子进程终止。
进程可能因为中断或时间片到期而被强制从核心中移除,并被放回就绪队列。
3.2.2 CPU调度 (CPU Scheduling)
调度程序的工作方式如下。I/O密集型进程在等待I/O之前,可能只会执行几毫秒。一个CPU密集型进程可能需要更长的持续时间才能在核心上运行。然而,调度程序可能不会给予一个核心给一个长时间运行的进程。相反,它可能会从核心中移除该进程,并安排另一个进程运行。因此,CPU调度程序至少每100毫秒执行一次,尽管通常更频繁。
例如 , 如果没有抢占,一个CPU密集型进程(比如一个有bug的死循环程序)可以永久霸占CPU,导致你无法进行任何其他操作,连鼠标都动不了。
3.2.3 上下文切换 (Context Switch)
当中断发生时,系统需要保存当前正在CPU上运行的进程的上下文,以便在处理完中断后能够恢复该上下文。上下文在进程的PCB中表示。它包括CPU寄存器的值、进程状态(见图3.2)和内存管理信息。总的来说,我们需要保存当前CPU核心的状态,无论它是在内核模式还是用户模式,然后恢复一个状态以继续操作。
将CPU核心切换到另一个进程需要对当前进程的状态进行保存,并为另一个进程恢复状态。这个任务被称为上下文切换(context switch)。如图3.6所示,当发生上下文切换时,内核会将旧进程的上下文保存在其PCB中,并加载新进程已保存的上下文。上下文切换的时间是纯粹的开销(overhead),因为系统在切换期间没有做任何有用的工作。它的速度因机器而异,取决于内存速度、必须复制的寄存器数量以及是否存在用于加载或存储所有寄存器的特殊指令。
3.3 对进程的操作 (Operations on Processes)
3.3.1 进程创建 (Process Creation)
在执行过程中,一个进程可能会创建几个新进程。创建进程被称为父进程(parent process),而新进程则被称为该进程的子进程(children of that process)。这些新进程中的每一个都可能再创建其他进程,从而形成一个进程树(tree of processes)
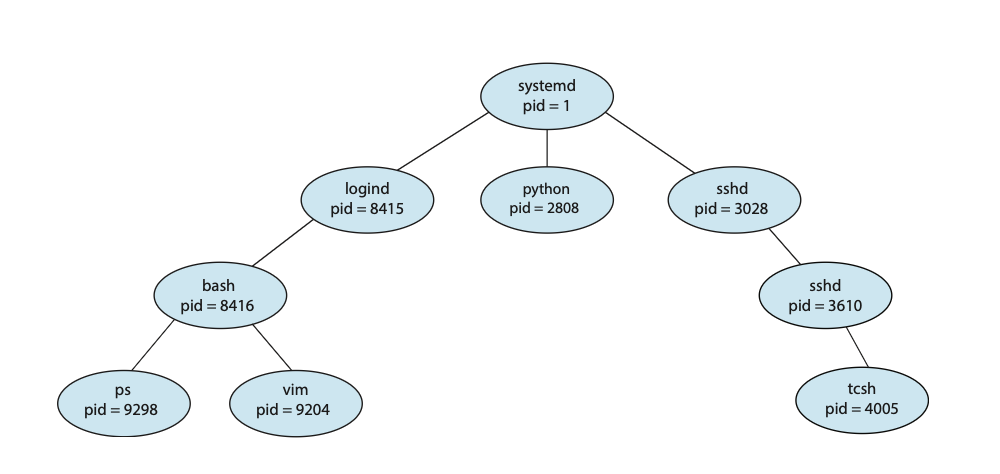
大多数操作系统(包括UNIX、Linux和Windows)都通过一个唯一的**进程标识符(process identifier, PID)**来识别进程,这个标识符通常是一个整数。PID为系统中的每个进程提供了一个唯一的数值,并且可以用来访问系统内进程的各种属性
通常,当一个进程创建一个子进程时,该子进程将需要某些资源(CPU时间、内存、文件、I/O设备)来完成其任务。子进程可以直接从操作系统获取其资源,或者它可能被限制为父进程资源的一个子集。父进程可能需要将资源在其子进程之间进行划分,或者它可能能够在其子进程之间共享一些资源(例如内存)。将子进程限制为父进程资源的一个子集可以防止任何进程因创建过多子进程而使系统过载。
除了各种物理和逻辑资源外,父进程还可能将初始化数据(输入)传递给子进程。例如,考虑一个进程,其功能是显示文件的内容——比如说
a.out——在屏幕上。当它被创建时,它会从其父进程那里获得文件名a.out作为输入。它将使用这个文件名打开文件并将其内容写到屏幕上。或者,父进程可能会传递一个指向打开文件的句柄。新进程会从其父进程的地址空间中获取文件名当一个新进程被创建时,对于执行有两种可能性:
父进程与其子进程并发执行。
父进程等待,直到其部分或所有子进程已经终止。
对于新进程的地址空间,也有两种可能性
子进程是父进程的一个副本(它拥有与父进程相同的程序和数据)
子进程加载了一个新的程序
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
pid_t pid;
/* fork a child process */
pid = fork();
if (pid < 0) { /* error occurred */
fprintf(stderr, "Fork Failed");
return 1;
}
else if (pid == 0) { /* child process */
execlp("/bin/ls", "ls", NULL);
}
else { /* parent process */
/* parent will wait for the child to complete */
wait(NULL);
printf("Child Complete");
}
return 0;
}新进程由原始进程地址空间的一个副本组成。这种机制允许父进程轻松地与其子进程通信。
fork()进程和子进程都从exec()系统调用之后继续执行(fork 后 ready 准备被调度),但有一个区别:fork()对新(子)进程的返回码为零,而父进程的返回码是(非零的)子进程的pid在
fork()系统调用之后,其中一个进程通常使用exec()系统调用来用一个新程序替换该进程的内存空间。父进程可以创建更多的子进程;或者,如果它在子进程的执行期间没有什么可做的,它可以发出一个
wait()系统调用,将自己移出就绪队列,等待子进程的终止
3.3.2 进程终止 (Process Termination)
一个进程在执行完它的最后一条语句并请求操作系统通过
exit()系统调用来删除它时终止。此时,进程可能会向其父进程返回一个状态值(通常是一个整数)(通过wait()系统调用)。然后,该进程的所有资源——包括物理和虚拟内存、打开的文件和I/O缓冲区——都会被操作系统释放。父进程可能会因为多种原因终止其一个子进程的执行,例如:
子进程超出了其已分配资源的使用范围。(为了确定是否发生了这种情况,父进程必须有一个机制来检查其子进程的状态。)
分配给子进程的任务不再需要。
父进程正在退出,而操作系统不允许子进程在其父进程终止后继续运行。
当一个进程终止时,它的资源会被操作系统释放。然而,它在进程表中的条目必须保留,直到父进程调用
wait(),因为进程表包含了进程的退出状态。一个已经终止但其父进程尚未调用wait()的进程被称为僵尸进程(zombie process)。所有进程在终止时都会变成这种状态,但通常只存在很短的时间。一旦父进程调用wait(),僵尸进程的进程标识符和它在进程表中的条目就会被释放。现在,考虑如果一个父进程没有调用
wait()就终止了会发生什么。它的子进程就成了孤儿进程(orphan process)。UNIX系统通过将systemd进程(回忆一下3.1节,它在UNIX系统中始终存在)指定为孤儿进程的新父进程来解决这个问题。systemd进程会周期性地调用wait(),从而收集任何已终止孤儿进程的退出状态并释放这些进程的标识符和进程表条目。