
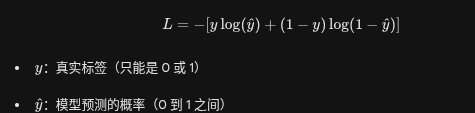
Overview

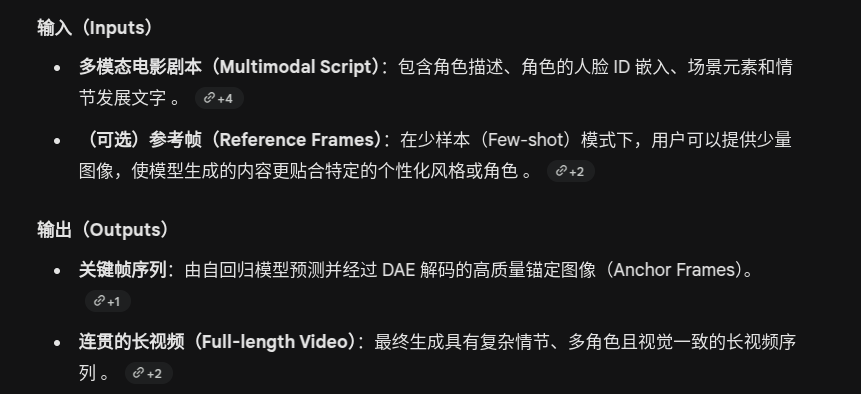






Omni-R1: Reinforcement Learning for Omnimodal Reasoning via Two-System Collaboration
https://arxiv.org/abs/2505.20256
这里 训练系统1 的时候,为什么最先想到的是 sft, 虽然最后被否决了?
SFT的逻辑为 “给模型看大量‘输入→正确输出’的例子,让它学会模仿”,对于 System 1,输入是 “长视频 + 全局指令”,输出是 “关键段选择 + 局部指令”,这看起来就是一个典型的序列到序列(seq2seq)生成任务,完全符合 SFT 的应用范式
从 ChatGPT 到 LLaMA、Qwen 等开源模型,几乎所有主流大模型的对齐流程都是:
预训练 → SFT(指令微调) → 强化学习(RLHF/GRPO 等)
SFT 是必经之路,它能快速让模型学会 “遵循指令”
System 1 的分层奖励设计 没有 将 最终任务目标(如分割 mIoU)作为唯一奖励;那么什么时候可以用端到端训练
端到端训练的核心前提是:从输入到最终输出的整个链路是可微分的,并且存在明确的监督信号。满足这两个条件,就可以用一个统一的损失函数(如交叉熵、IoU、MSE)直接训练所有参数
并且 有明确的 “输入 - 输出” 监督对;如 分类任务有 “图像 - 类别标签” 对;这些标注提供了直接的监督信号,模型可以通过梯度下降,自动学习到 “如何从输入得到正确输出” 的中间表示,不需要显式设计中间步骤的奖励
主要框架
痛点
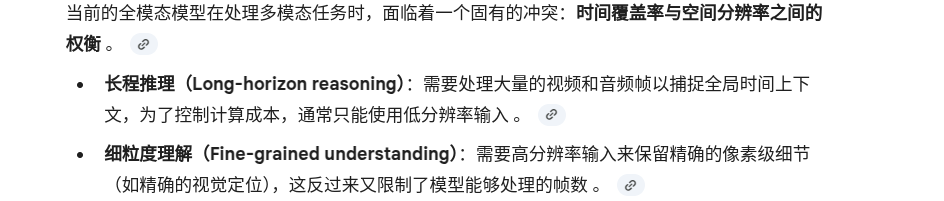
解决方案:双系统协作架构 (Two-System Architecture)

Omni-R1 强化学习训练框架
由于很难人工定义或监督什么是“最优”的关键帧选择和任务重写,研究团队将系统 1 的优化过程转化为一个强化学习问题
sys1
任务输入与系统 1 推理 (Global Reasoning System)

系统 2 细节理解 (Detail Understanding System)

层次化奖励机制 (Hierarchical Rewards Feedback)

GRPO 策略更新

如何理解“系统一和系统二是强耦合的”这句话?

NitroGen: An Open Foundation Model for Generalist Gaming Agents
MOVIEDREAMER: HIERARCHICAL GENERATION FOR COHERENT LONG VISUAL SEQUENCES
Sora 相对于传统视频生成模型
采用时空Transformer,同时对空间维度(捕捉单帧图像内部的视觉特征)和时间维度(捕捉帧与帧之间的时序关联)进行建模;
Scaling Law
Diffusion Autoencoder 和 传统扩散模型 的区别(2022版本,还没用transformer)
核心架构

能做到什么?

论文中diffusion autoencoder核心架构

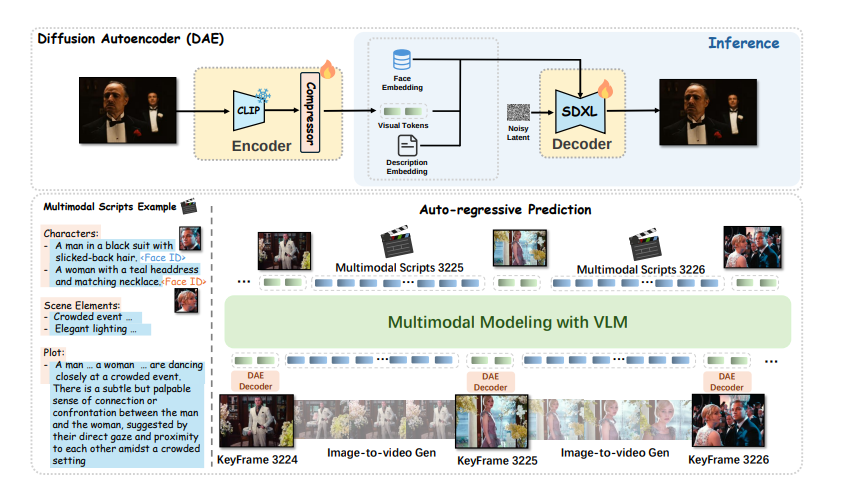

MovieDreamer存在有图模式和无图模式,如果没有图片输入的话, 那 clip 和 compressor不就没活可干了?另外,连基础样品都没,还怎么做后续的自回归预测 图像token?
在纯剧本生成视频的场景下,它们的作用体现在“定义的空间”和“训练阶段”:
它们定义了“语言”:Compressor 的存在,是为了给 LLM(如 LLaMA)定义一套“视觉单词表”。即使推理时没给图片,LLM 预测出的那 2 个数字(Token)也必须落在 Compressor 训练好的那个特征空间里。
训练时的“老师”:在训练阶段,模型看了数百万个视频。CLIP 和 Compressor 负责把视频变成 Token 教给 LLM。到了推理时,LLM 实际上是在“背诵”或“模仿”它见过的图像 Token 序列。
CLIP
训练方式:对比学习

训练细节




内部结构

意义

卷积神经网络
组成

强大之处

输入

输出(常见的)


卷积核是如何在矩阵中提取特征的?
具体动作

为什么乘加运算 就能提取特征?

more

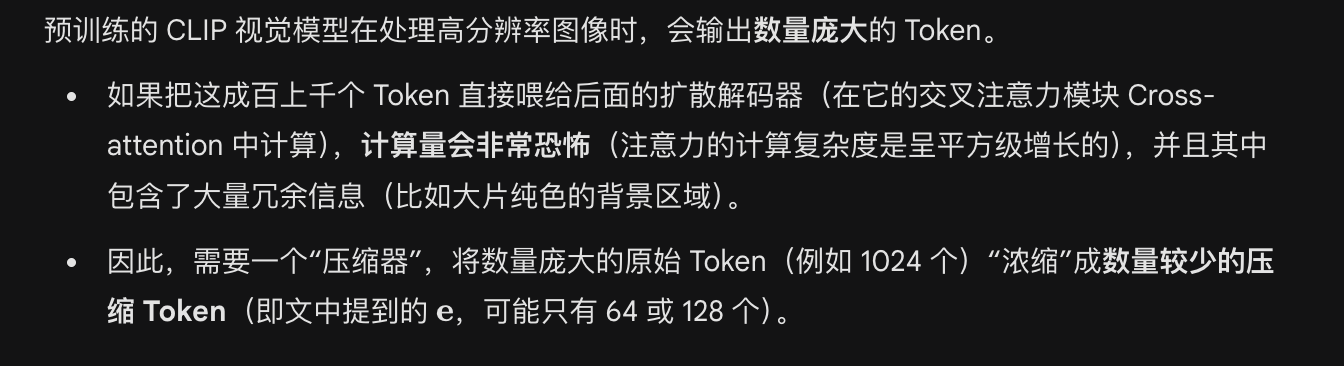
transformer based token compressor 是什么
什么是token?

为什么需要压缩(compressor)?
为什么是基于 Transformer?

在本论文中 Q K V 是什么?

本文的 diffusion autoencoder 和原始版本有相差,原始版本的 zsem, 而SDXL的输入特殊,他接受一系列token;因此在这里 CLIP和 transformer压缩器将原始图像 压缩成一组序列token e;
为什么要冻结 CLIP?是因为CLIP的输出到 compressor之间 无法用链式法则来更新CLIP的参数吗?
防止灾难性遗忘;节省算力
SDXL(Stable Diffusion XL)其输入输出
输入端


内部程序

输出

SDXL在训练过程中其输入输出
原始数据

核心网络 (U-Net) 的输入端 (Inputs)


核心网络 (U-Net) 的输出端 (Outputs)

Loss 闭环学习

在 SDXL 训练的过程中,是以 预测的噪声 和 实际的噪声 的 差异 来计算loss的;但我在看那些普通的 MLP的分类器中,都是拿最终实际得出的分类结果进行softmax 再和 预期结果做比较算loss的;也就是说,MLP分类器的 训练 和 实际使用 的 结果 都是 分类结果;而这里 SDXL 训练中的 LOSS却是噪声,而实际使用中却要还原出图像;为何要用噪声当loss训练呢?

SDXL 在 使用过程中,往往要输入 一个完全 随机 的 噪声图和 一段文本描述转换而成的 token;既然是完全随机的,那为什么要加这个噪声图呢?这和训练 过程中 输入为 原本的图像加一个噪声,然后去预测这个噪声是什么,这个过程有什么关系?


选择用masking;是不是在舍弃一小部分 训练收敛速度 和 最终模型生成图形质量 的情况下,换取 对脸部细节的 更精密生成?

“This involves parameterizing the GMM with kd means, kd variances, and k mixing coefficients.” kd 个均值(Means)、kd 个方差(Variances)以及 k 个混合系数 具体是什么?
变量含义

具体含义

交叉熵的离散输出不再适用生成图像的训练
交叉熵损失函数如是计算分数 (ytrue是真实答案的概率, ypred是模型预测的概率,真实答案的概率为独热码分布,只有一项是0;因此在LLM输出结果中, 香蕉 和 汽车 相对于 苹果的正确度是一样的,尽管有水果这个共同特征;但是在模型内部,还是能意识到两者关系的)
Loss = -Σ(ytrue * log(ypred))
自回归
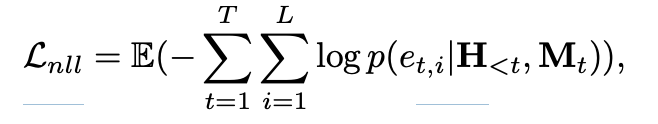
H<t即过去的经验, 根据过去的经验,外加剧本提示Mt, 在此条件下 计算p,即正确答案在 生成的概率分布 中的概率;
前面的 CLIP,compressor, decoder 训练 根据token生成图像,这里训练生成token

既然 人脸嵌入主要由 FARL 模型提取,并且FARL在训练中是冻结的,并且 FARL的输入只包含面部区域,那么案例来说输出的嵌入结果只和这个人有关啊,为什么还要防止和 场景信息有耦合呢?

MLP的内部神经网络架构长什么样
宏观层级结构 (Layer Structure)

神经元之间的连接 (Connections)

微观:单个神经元内部的数学魔法

数据的流动 (Data Flow)

Stamo
https://arxiv.org/html/2510.05057v1
Summary

框架
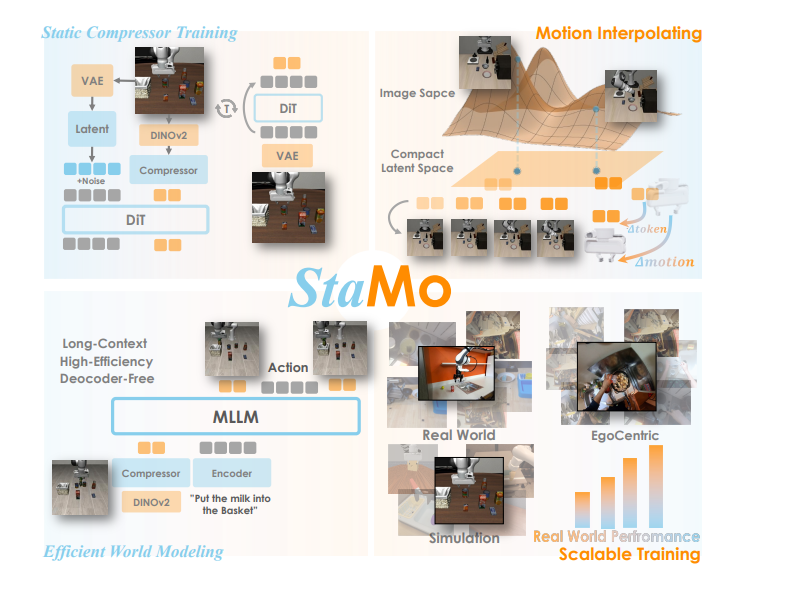

动作的方向距离不是连续的吗?为什么要使用交叉熵?


DiT
之前 SDXL 去噪用的是 U-Net,他内部用CNN,擅长处理局部细节,难以看清全局信息 (两者都在 VAE 进行编码解码,网络在编码后进行处理)
DiT训练时的输入输出
概括



adaLN-Zero


Variational Autoencoder(VAE, 变分自编码器)
普通的 AutoEncoder是一个两头大、中间小的沙漏型神经网络;但他的隐空间是离散的、不连续的,如果你强行在隐空间里随机生成一个点丢给解码器,它大概率会输出一团乱码。
编码器 不会将一个图片处理成 若干个确定的数字,而是输出一组均值 和 方差
然后,系统会在概率云中随机抽取一个点
解码器拿到这个点,并把它还原成原图
两个损失函数

VAE 在 Sora 和 Stable Diffusion 中的作用
直接在 几十万像素的图片上加噪声和去噪 计算量过大

“基于 Transformer 的压缩器”,他的架构是怎样的,是如何做注意力的
压缩器总体架构

注意力机制的工作方式

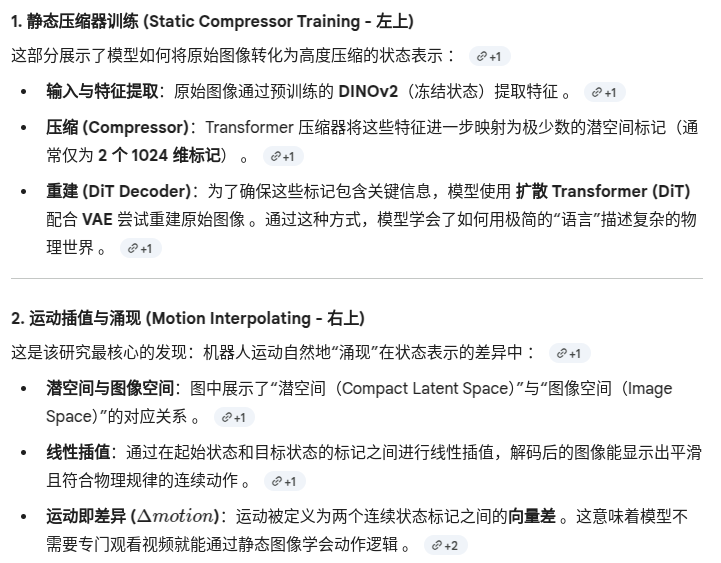
论文提出问题,对于大方差动作的学习,如果采用MSE 训练的话容易陷入均值回归,那么为何不采用dp策略?
dp输出连续,不适合与LLM相接;而前者输出两个token,适合LLM;前者算力需求低
VAE不将图片压缩成一个点,而是一个概率云
Where is Stamo?(figure)
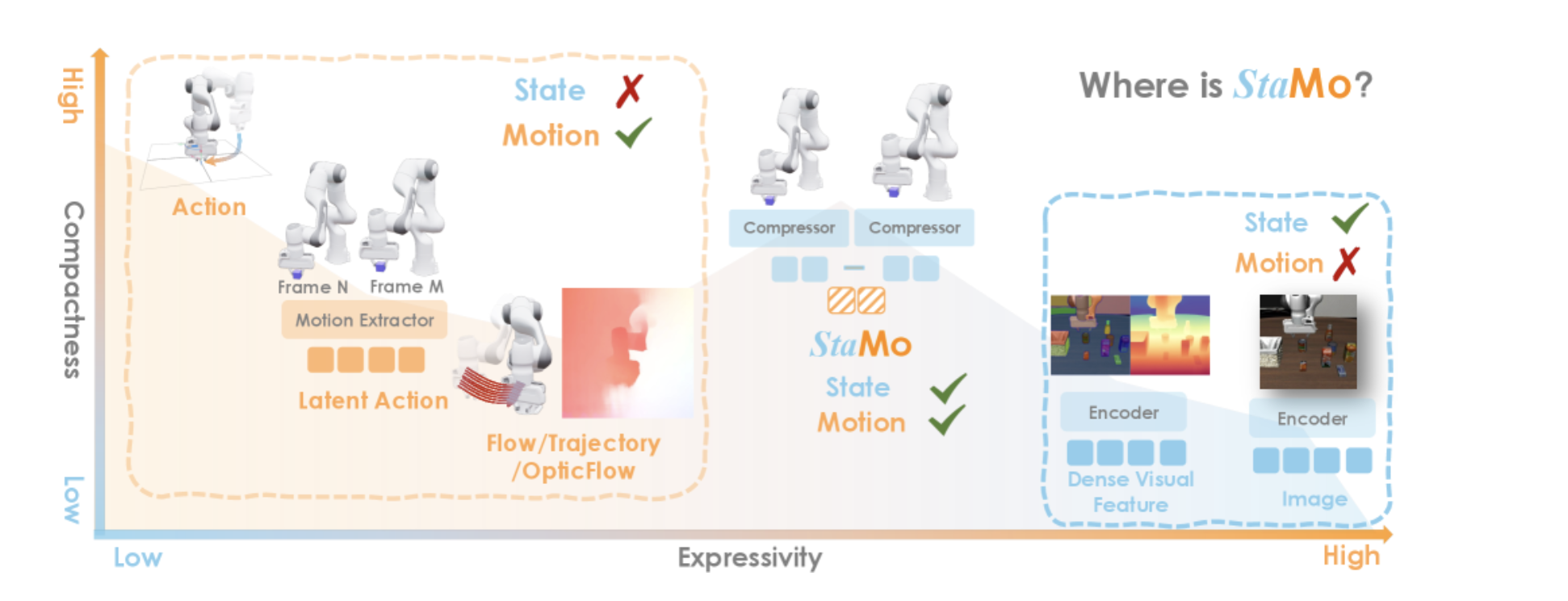
X轴的“表现力”,表示数据有多丰富;Y轴的 “紧凑型”,表示数据的紧凑性,高紧凑型往往表示 数据维度低。
Flow Matching
传统扩散模型使用 随机微分方程,并且是根据不同时间步向里面加入随机噪声的;而flow matching在数学上定义了“向量场”,用较少的步骤就能生成清晰图片;

是如何用 mlp 将 大模型输出 转化为 连续数值的?
大模型输出原本是离散的
例如Llama 有32000 个词汇token,大模型最后一层输出的就是 一个 32000 长度的数组(打分),然后通过softmax将其和变为100%;VLA 的动作也如同词汇token,被离散化
如何化为连续数值
我们将大模型最后一步 查词汇表给删除,这是其输出是一个隐藏向量,例如有4096维;然后将其送入MLP,进行线性加权求和(wx+b)
如果我们要预测的未来状态 是 2048维的话,那么我们就设计一个MLP,将4096维压缩至2048维
论文中解决有标注的数据量太少的问题
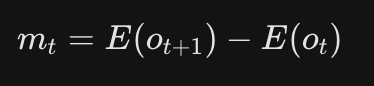
E 即 Stamo压缩器,o为图像,相减得出 潜在运动m;
将 带真实物理动作标签的机器人数据,和带有 StaMo 生成的伪动作标签的视频数据 同时给policy训练
为什么需要 Action Linear Probing Experiment来证明 z_t 包含了有效的动作信息? 混合数据能训练出更好的 模型这一点 还不够有说服力吗?
如果把 Stamo压缩差值,Pooled Delta Image,Delta DINOv2 Features分别拿出去做 端到端训练的话,下游模型可能弥补特征的缺陷,使得模型能力相差没有那么明显
而使用轻量级MLP来进行线性探测,如果结果相差较大,则可以说明 Stamo 压缩差值 对应的 动作特征比较明显。
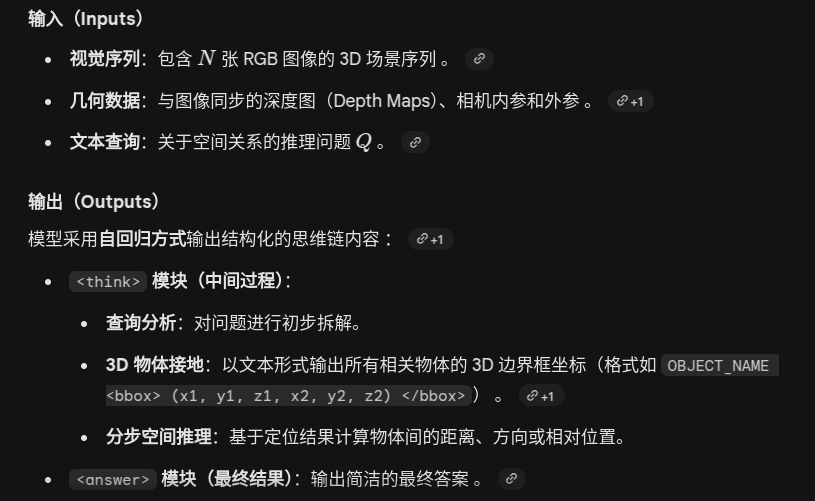
REASONING IN SPACE VIA GROUNDING IN THE WORLD
https://arxiv.org/pdf/2510.13800

看到这里,我不禁疑惑,为什么不把 external decoders 融入到 llm形成一个新的 能grounding 的 llm呢?是因为 这样会破坏原有结构,使得普通 对话性能下降吗?
是的,一点是灾难性遗忘,另一点是 物理坐标 是连续的,llm预测是离散的
framework
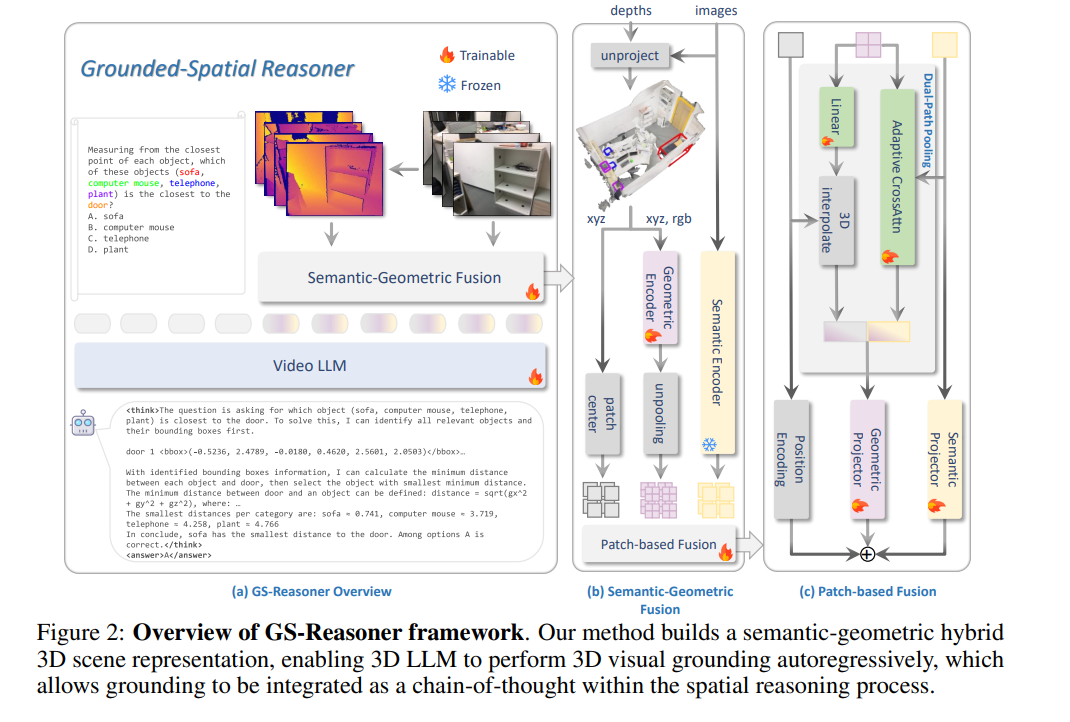


Grounding 一词的含义
3D Visual Grounding,3D 视觉定位/视觉基准化
在这篇论文的语境下,Grounding 具体指的是:当用户用自然语言提到某个物体时,AI 能够准确地在 3D 空间中找出那个物体,并用一个“3D 边界框(3D bounding box)”把它框出来。
为何点云 不具有绝对物理坐标信息?
打乱顺序的点云 输入 普通神经网络 会造成大相径庭的结果

最大池化引出

最大池化


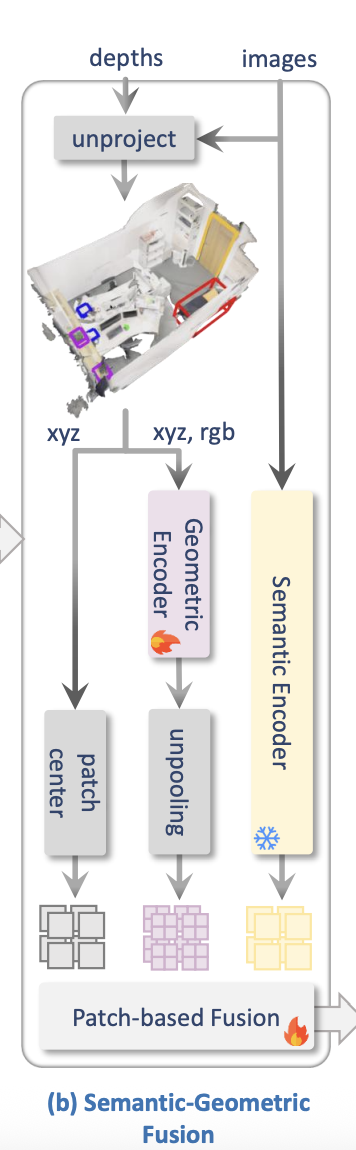
左边的 patch center 输出的是不是位置信息?这里 geometric encoder 已经通过 unpooling 获取 位置信息了,为什么还需要patch center?
并非;Geometric Encoder从 xyz rgb 提取局部信息之后,已经忘记了精确坐标;而unpooling 并非将所有点云的精确坐标还原,而是 为了与右边的 semantic encoder 的 patches对齐;把提炼出来的 3D 形状特征,重新映射、分配回对应的 2D 图像块格子里去。
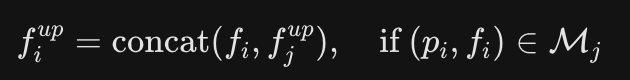
对应这个

p'i 和 f'i 是一对一关系还是一对多关系?
是一对一关系,看起来fi 经过池化之后是多维的,但这多维的特征向量会映射到同一维度上进行比较,只剩下一个。

如何理解 Collecting pooled points from n' subsets yields the point set M' = ... for the next stage of encoding?

PointNet++
那么 上一层的pi,fi 和 下一层的 pi,fi是不是 多对一关系?然后这个多的倍数是|Mi|?
Yes
图片中 unpooling 这个地方没有 加上 “traniable“的图案,难道这个 unpooling 模块是个网上扒下来的现有的模型吗?它不用被训练吗?它天生就和隔壁的 Semantic Encoder对齐吗?
unpooling不是神经网络,无法被训练;


也就是说,在进行 pooling 的时候,其实丢失掉了一部分信息:无法通过高维输出恢复到 原始点云;但有一个信息没有丢失:即 高维特征对应的 点云坐标;这样子的说法对吗
Yes
前提提示:《Point Transformer V3: Simpler, Faster, Stronger》https://arxiv.org/pdf/2312.10035
空间填充曲线 (space-filling curves)

切分为子集 (partitions into subsets)

序列化注意力 (serialized attention)

Dual-Path Pooling:
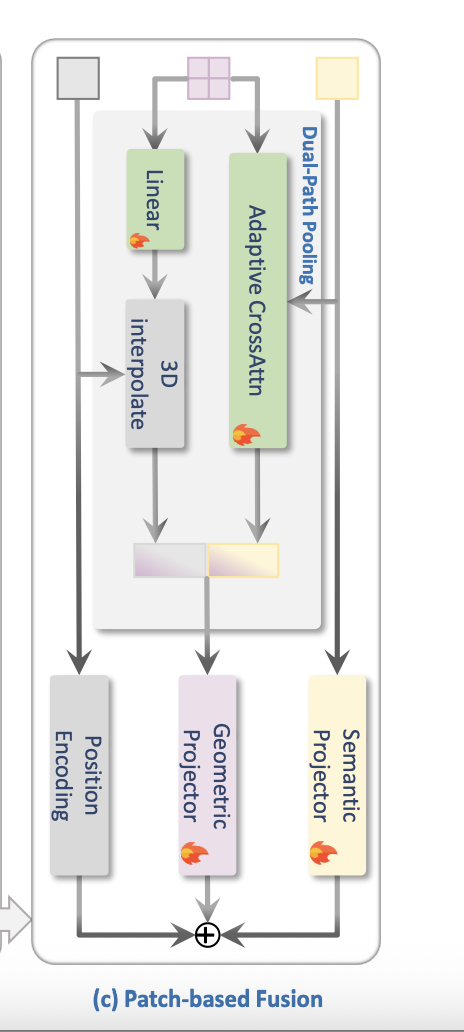
position 信息 和 geometric 信息到底是怎么结合起来的?我们知道 geometric encoder 加上 unpooling 会得到不同layer的每个范围区域点云的局部和全局特征;patch center 输出的位置信息,是不是每个patch只对应一个position? 而根据这个patch的大小,我们选定 之前unpooling的某一层,其局部和全局特征就可以和position 信息对齐了 。这样的理解对吗?


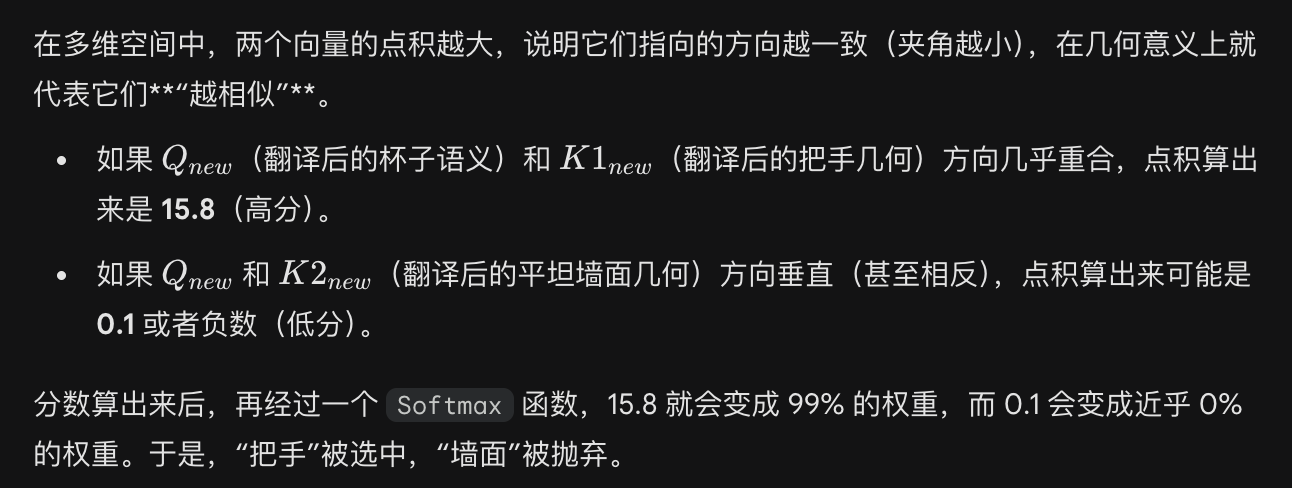
2d 语义 Q 是怎么发现 自己和3D 几何 “把手”相近,而和 “墙面”特征相远的
投影

点积
训练过程


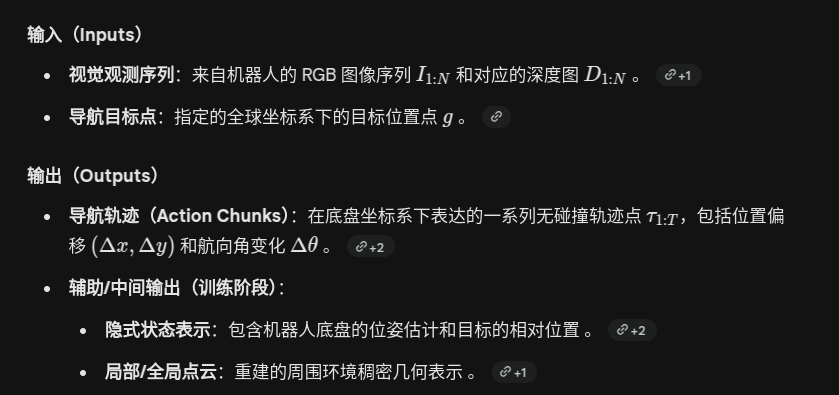
LoGoPlanner: Localization Grounded Navigation Policy with Metric-aware Visual Geometry
https://arxiv.org/pdf/2512.19629
framework
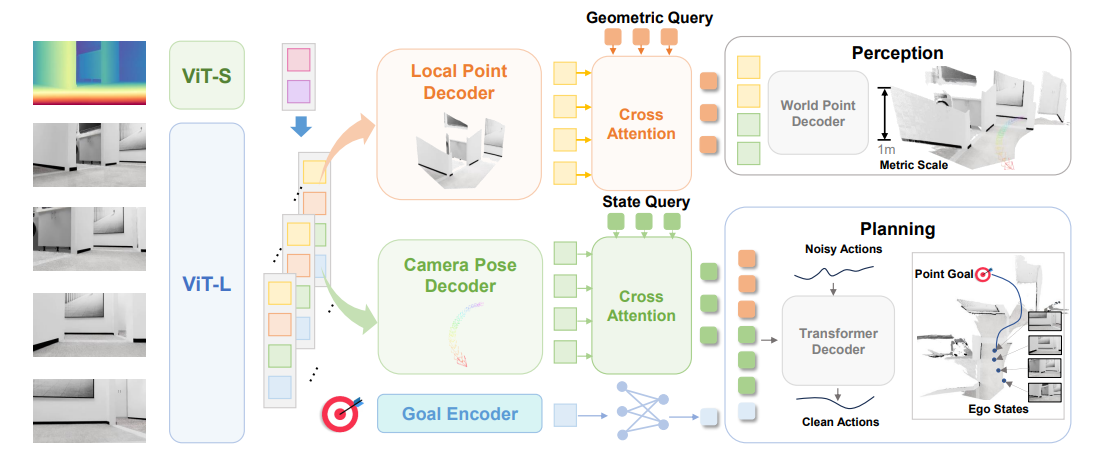


端到端的优势和劣势
优势

劣势

前提提示:正交旋转矩阵
简单来说,如果你想在不改变物体形状和大小的情况下,让它绕着原点转动,你所使用的数学工具就是正交旋转矩阵
数学定义

几何特性

旋转矩阵举例

RoPE(Rotary Position Embedding,旋转位置编码)
痛点
Transformer 架构本身是个“路痴”。它的自注意力机制(Self-Attention)在计算时,是把所有词当成一个无序的集合。如果你不告诉它词的顺序,“狗咬人”和“人咬狗”对它来说没有任何区别
因此,我们需要一种方法把“位置信息”注入到模型中。RoPE 就是为了极其优雅地解决这个问题而诞生的。
传统位置编码的困境

method

RoPE的输入输出
输入

输出

内部

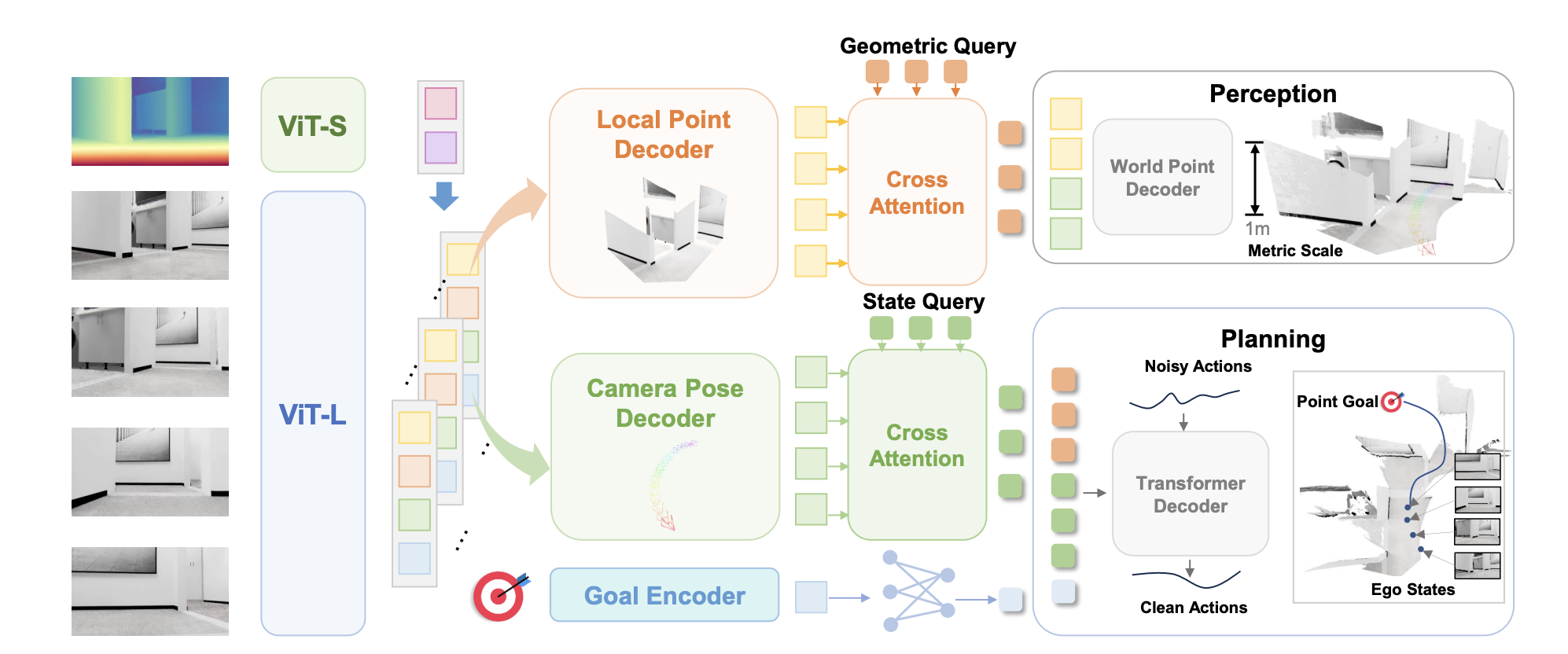
为什么不直接把橙色和绿色的结果扔给规划器?


前提提示:自注意力机制在训练时的输入输出
输入输出

QKV的产生

输出(特定语境下的苹果)

反向传播




使用过程中 W 冻结,输出预测头中最大概率的
Cross-Attention(交叉注意力)



QS QG这几个 没有什么关联的向量 为什么可以在最后直接拼接?这样做有什么数学原理吗?

训练过程中的 cross attention 及其输入输出
输入

生成跨界的 K Q V

输出

反向传播

这里产生 h^c. h^p 的ϕ_c ϕ_p 也可以被最终的crossattn反向传播更新吗?由最终的结果,一路更新到之前的 ϕ_c ϕ_p , 这就是端到端训练吗?为什么不进行分模块训练?是因为中间的模块 没有明确的监督数据吗?
是端到端
不是因为没有监督数据,在真实世界的机器人训练中,我们有大量的“中间监督数据”(比如极其精准的 3D 激光雷达点云图、高精度的相机定位坐标 Ground Truth)。传统的“分模块训练”正是利用这些数据,先把感知模块训练到 100 分,再把定位模块训练到 100 分。
既然各个模块都能考 100 分,为什么还要搞端到端?因为分模块训练存在两大无法逾越的死穴
LoGoPlanner的训练方法并非完全端到端



为什么 这里要用 intermediate 数据来预测 reconstucted world,而不是前面 intermediate 数据转化得到的 显式 点云 和 pose

一方面是为了 紧凑
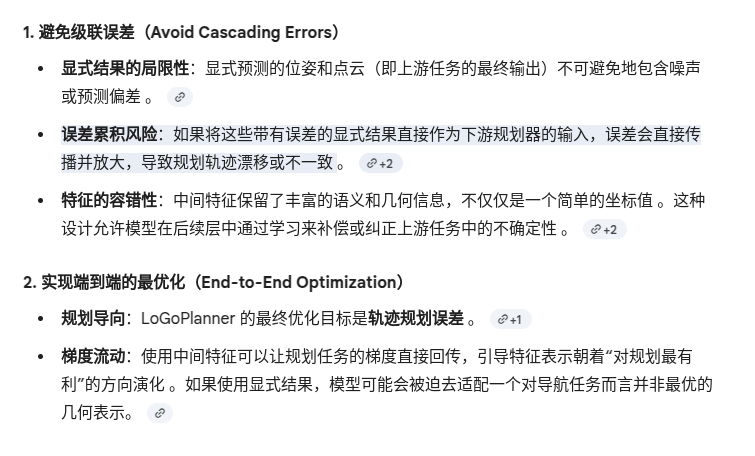
为什么 CrossAttn 的结果 是 Q_S 而不叫 V_S?
1. 在CrossAttn中,Q的长度往往和V的长度不一样,但输出中长度和 Q一样
2. CrossAttn有残差相加,提取出来的结果加到了原始Q身上

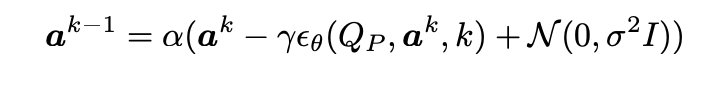
如何解释此公式
扩散模型

公式拆解

如何理解 “交替注意力机制在帧内注意力和帧间注意力之间交替,同时提高了局部保真度和长时段一致性”?



Fast-FoundationStereo: Real-Time Zero-Shot Stereo Matching
https://arxiv.org/pdf/2512.11130
framework
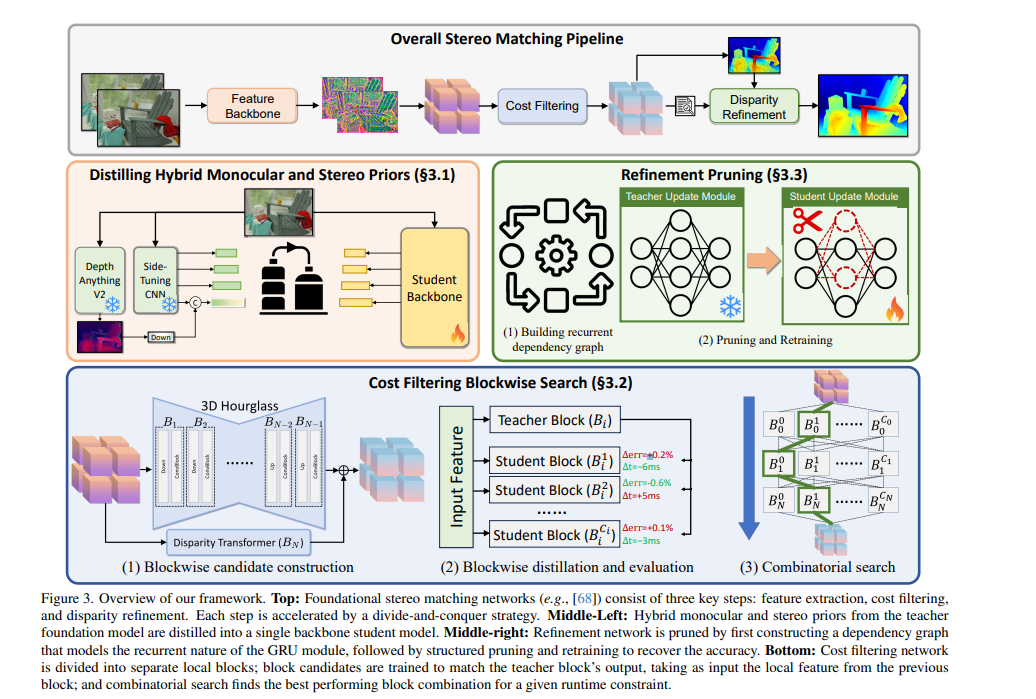
总体立体匹配流水线

混合单目与立体先验蒸馏

代价过滤的块化搜索
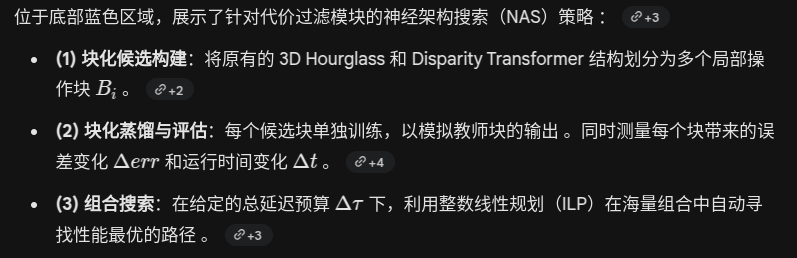
细化模块剪枝
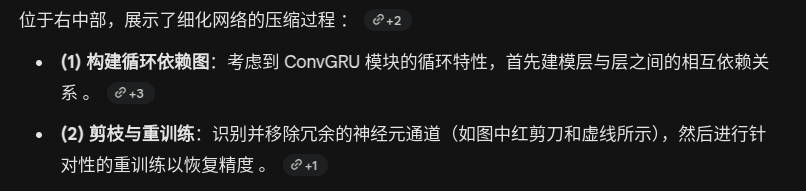
伪标签的产生

伪标签用于蒸馏过程的监督
对大模型的剪枝是如何进行的?
策略1,非结构化剪枝

结构化剪枝

Post Training Pruning

前提提示: Side-Tuning(旁路微调)https://arxiv.org/pdf/1912.13503
痛点

Side-Tuning 工作原理

优势

既然 S(x) 是为了 预测残差的,那么最终特征应该是 B(x) + S(x) 啊, 为什么是加权之后的呢
初始化时,我们不需要额外设计一个S(x)

让模型学会自适应

在第一刀(特征提取)拿到左右眼的特征后,系统要把它们放在一起“比对”,生成一个极其庞大的数学矩阵——代价体积(Cost volumn)
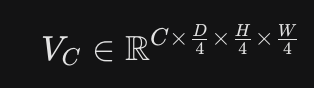
记录的是左眼和右眼在不同视差下的“匹配得分”
“DepthAnything V2 和 侧调CNN “的输出

也就是说,左眼图片 在经过整个 “DepthAnything V2 和 侧调CNN “(或者是后面的学生模型),进行特征提取的时候,是不包含右眼图片的信息的; 那最后 f(i) 属于 Ci H/i W/i 是怎么转化为 Vc 的?
是的, 无论是教师模型还是学生模型,它们执行的都是一元特征提取(Unary Feature Extraction)。这意味着在提取左图特征 fl 时,网络完全不知道右图的存在,反之亦然
将这些独立的特征转化为 代价体积(Cost Volume, VC) 的过程,本质上是一个“滑动窗口匹配”的过程。



ResNet
痛点
残差连接
优势
权重矩阵
适应非线性激活函数




文中提到的5个layers
(1) 3D conv layer with varying channel dimensions
类比2D conv layer,这里是 varying channel是因为:如果系统发现算力预算吃紧了,它可以自动挑一个“把通道数压缩一半”的 3D 卷积层,牺牲一丢丢精度来换取极大的速度提升。
(2) 3D deconv layer that doubles the spatial dimensions of the cost volume
为什么要放大?
如何将维度翻倍?


(3) APC layer that performs separate spatial and disparity convolution with different respective kernel sizes
痛点

APC卷积方法

可变的卷积核大小

(4) residually connected 3D conv layers, similar to ResNet
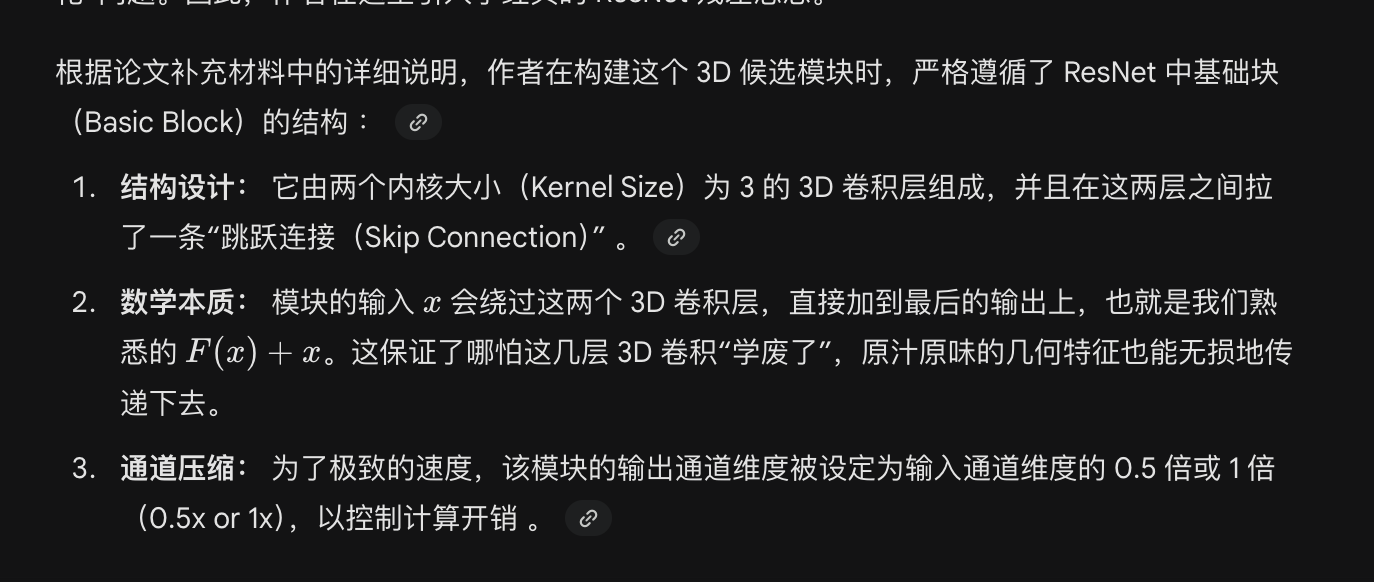
ConvGRU 输入输出

多尺度金字塔特征是 怎么 变成 初始视差图的?
构建代价体积

代价滤波与聚合 (Cost Filtering & Aggregation)

初始视差预测 (Initial Disparity Prediction)
ffs输出的 视差图作用?
V-Thinker: Interactive Thinking with Images
https://arxiv.org/pdf/2511.04460
V-Thinker 的整个训练框架
第一阶段:感知对齐 (Perception Alignment)
第二阶段:交互推理对齐 (Interactive Reasoning Alignment)

Cold-Start SFT 和 Reinforcement Learning对比


GRPO相对于PPO的优势
对比PPO

GRPO的工作原理

GRPO数学直觉

PPO 的四个模型的分别作用


在公式 (DK, Tˆ) = G(Combos(K)). 之中,是不是可以理解为 G 生产的 Dk 包含代码,然后先通过运行代码获得图片,然后根据图片中的信息进行 工具的挑选,生成;还是通过 code 直接生成 T
直接生成,而不是“先运行再挑选”的闭环
生成器 G 的工作逻辑

只有在这个时候才会运行代码并观察:

如何在这样一次次迭代中,防止最终得出的T或K和一开始输入的T和K大相径庭,从而产生问题?
扩张函数 phi :利用 BGE(一种文本嵌入模型)进行层次聚类,对新生成的元素进行过滤、合并和归一化 ; 如果生成的“新工具”只是对现有工具的重复描述或微小改动,聚类机制会将其合并;如果生成的“新知识”逻辑混乱,过滤器会将其剔除 。
协同校准中,生成的 Python 代码会在沙盒中真实运行 。如果模型构思出的“新工具”在几何逻辑上画不出来,或者渲染出的图像与问题答案对不上,检查器会直接判定该样本无效 。
论文认为这种从零开始的生成(From Scratch)并非漂移,而是一种正向的演化;通过限定工具来构思知识(或反之),模型能发现许多人类在标注数据时难以覆盖的正交 (Orthogonal) 知识组合 。例如,模型可能会发现一种结合了“偏微分方程”和“动态阻尼标注”的新型交互题型,这是单纯靠数据蒸馏(Distillation)无法得到的 。
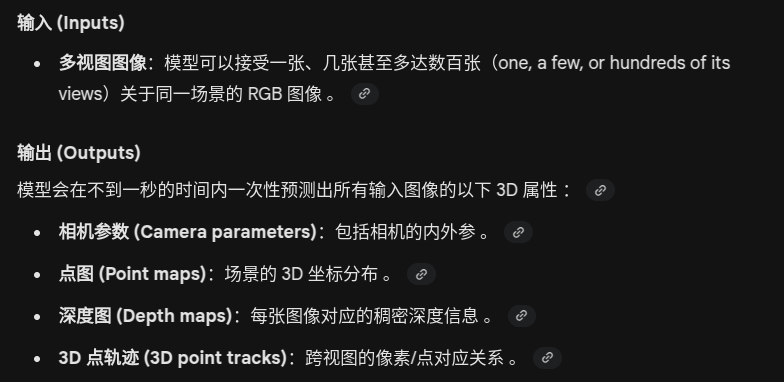
VGGT
https://arxiv.org/pdf/2503.11651
framework
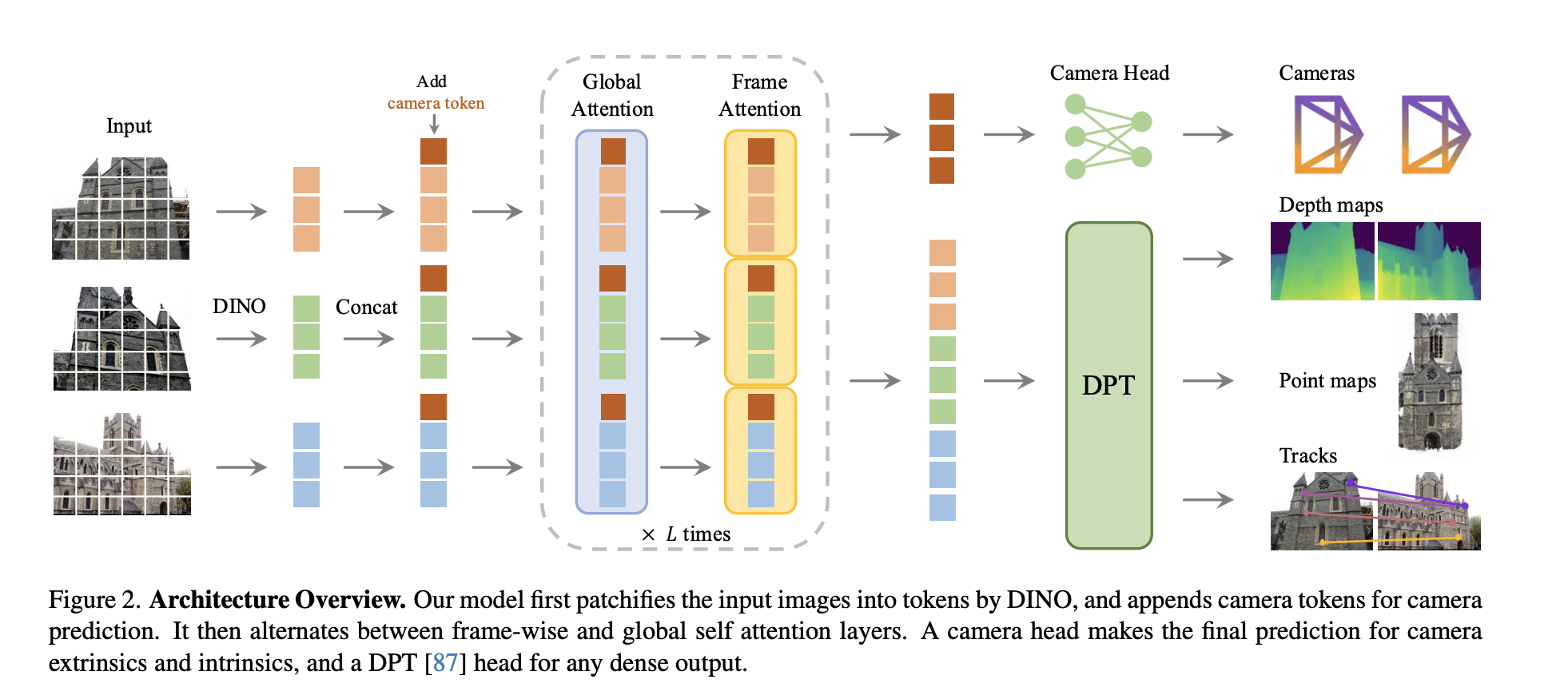
What is the way VGGSfM [125] combines machine learning and visual geometry end-to-end via differentiable BA?


为什么 传统的 重建 不将 不同视角的点云 放在同一个空间体系下?

1. 传统重建是一个典型的“迭代优化”过程
2. 计算复杂性与累积误差


点云表示P
维度为 3*H*W, image上每个点对应的 xyz坐标值,而不是深度
Prediction Head


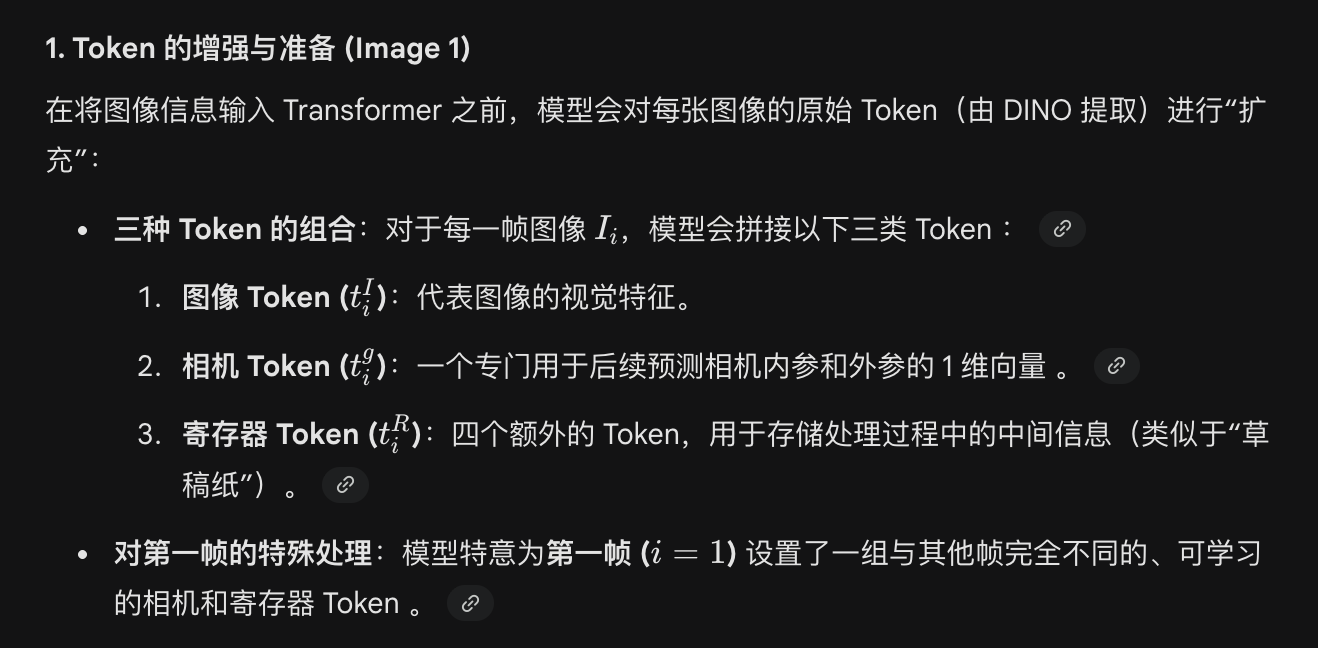

camera_token 和 register_token 实现细节(源码)
# Note: We have two camera tokens, one for the first frame and one for the rest
# The same applies for register tokens
self.camera_token = nn.Parameter(torch.randn(1, 2, 1, embed_dim))
self.register_token = nn.Parameter(torch.randn(1, 2, num_register_tokens, embed_dim))
# The patch tokens start after the camera and register tokens
self.patch_start_idx = 1 + num_register_tokensself.camera_token: 形状(1, 2, 1, embed_dim)—— 两套路由:第 0 槽给首帧,第 1 槽给其余帧。self.register_token: 形状(1, 2, 4, embed_dim)—— 同样 首帧 / 非首帧 各一套 4 个 register。patch_start_idx = 1 + num_register_tokens(默认 5),表示 patch 从第 5 个位置开始(前 1 个相机 + 4 个 register)。patch 指的是:把整张图切成网格后,每个小格(patch)对应的一个视觉特征向量
对 RoPE,
patch_start_idx之前的 token 位置被置为 0(与「相机/register 不参与 patch 网格位置编码」一致)
前向过程中
每个
forward里用当前的self.camera_token/self.register_token展开,与patch_tokens拼成完整序列
# Expand camera and register tokens to match batch size and sequence length
camera_token = slice_expand_and_flatten(self.camera_token, B, S)
register_token = slice_expand_and_flatten(self.register_token, B, S)
# Concatenate special tokens with patch tokens
tokens = torch.cat([camera_token, register_token, patch_tokens], dim=1)拼好的
tokens依次经过 frame / global 的Block,和 patch 一起做 self-attention、FFN。此时 第 0 位是相机 token 的隐藏状态,第 1–4 位是 register 的隐藏状态,它们每层都会被更新。
下游如何使用?
相机:
CameraHead取最后一层输出的[:, :, 0](相机槽),和register_token参数无直接索引关系,但相机槽在 Transformer 里一直和 register、patch 交互。深度 / 点云 / DPT 特征:从
patch_start_idx(默认 5) 往后只取 patch,不读 register 槽;但 patch 表示仍受前面与 register 的 attention 影响。
AA Transformer:frame(帧内)与 global(跨帧)交替
初始化:
aa_order=["frame", "global"],depth个 block 分成frame_blocks与global_blocks两套参数。帧内自注意力:
_process_frame_attention保持 (B*S, P, C),即每个 frame 的 P 个 token 内部做 attention(对应图里的 intra-frame)。全局自注意力:
_process_global_attentionreshape 成 (B, S*P, C),所有帧所有 token 一起 attention。
for _ in range(self.aa_block_num):
for attn_type in self.aa_order:
if attn_type == "frame":
tokens, frame_idx, frame_intermediates = self._process_frame_attention(
tokens, B, S, P, C, frame_idx, pos=pos
)
elif attn_type == "global":
tokens, global_idx, global_intermediates = self._process_global_attention(
tokens, B, S, P, C, global_idx, pos=pos
)
...
concat_inter = torch.cat([frame_intermediates[i], global_intermediates[i]], dim=-1)
output_list.append(concat_inter)BRIDGE THINKING AND ACTING: UNLEASHING PHYSICAL POTENTIAL OF VLM WITH GENERALIZABLE ACTION EXPERT
https://arxiv.org/abs/2510.03896
framework
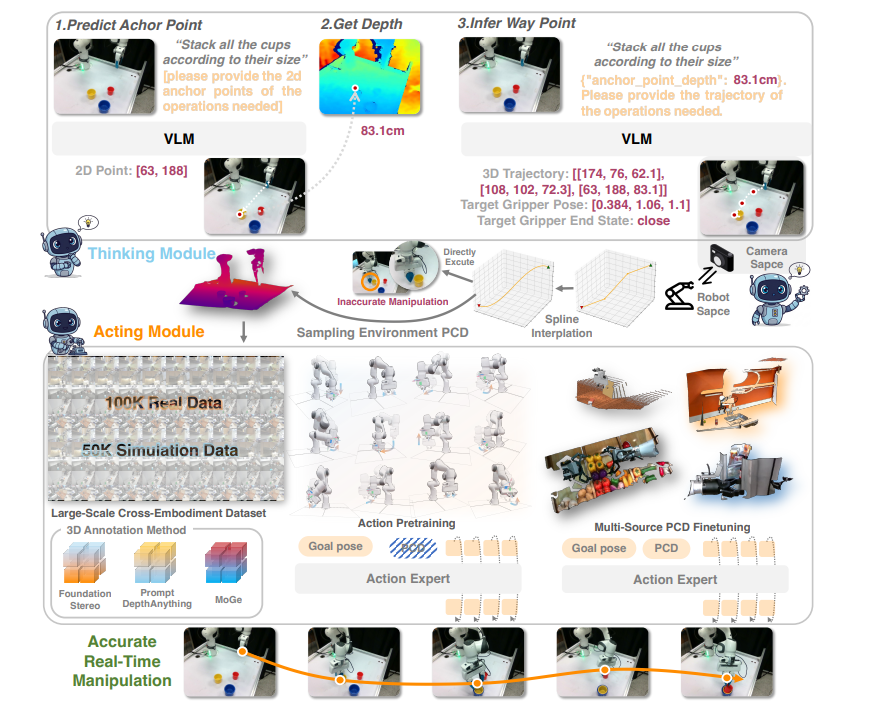
思考模块:VLM 路径规划
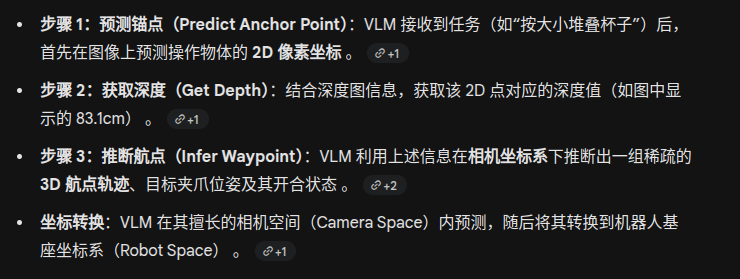
中间步骤


动作训练

重点:为何要先屏蔽PCD,旨在 避免计算瓶颈
将推理与动作集成到单体架构中的局限是什么?
结构:端到端
问题
灾难性遗忘
推理与执行的混淆 单体模型将高层语义推理与底层几何动作混在一起 。因为动作模块必须同时处理复杂的语义信息,这使得它很难在不同任务之间进行大规模的交叉训练,导致模型在面对新环境或新任务时泛化能力极差
为什么混在一起会导致很难交叉训练和泛化?
1. 动作模块必须处理复杂的语义信息
由于没有明确的中间接口,负责驱动电机或关节的执行部分无法只专注于“几何位移”,它必须先从这些复杂的语义信号中“解读”出任务意图,才能决定下一步怎么走 。
这让动作模块陷入了两难:它既需要足够轻量级以保证实时执行,又被要求具备解析高层语义的能力
2. 为什么这会导致大规模训练困难且泛化极差
因为动作模块要学习的是“语义到动作”的映射,而非纯粹的“几何到动作”映射,这使得不同来源、不同任务的数据很难在同一个模型下进行有效的大规模交叉训练 。
为了让机器人学会特定的物理控制,通常需要在规模较小、领域狭窄(Narrow-domain)的机器人数据上进行微调;从而导致VLM灾难性遗忘
伪解耦:之前的解耦只是形式上的拆分,并没有实现功能上的减负。动作模块依然要分出大量的计算资源去“理解任务”,而不是专心“搞物理动作”
为什么 传统的视觉-语言-动作(VLA)模型通常直接预测机器人基座坐标系(Robot's base frame)下的坐标 ?而不是 先 预测相机坐标,再进行转换?
因为是端到端...
有监督微调(SFT)数据集的标注流程
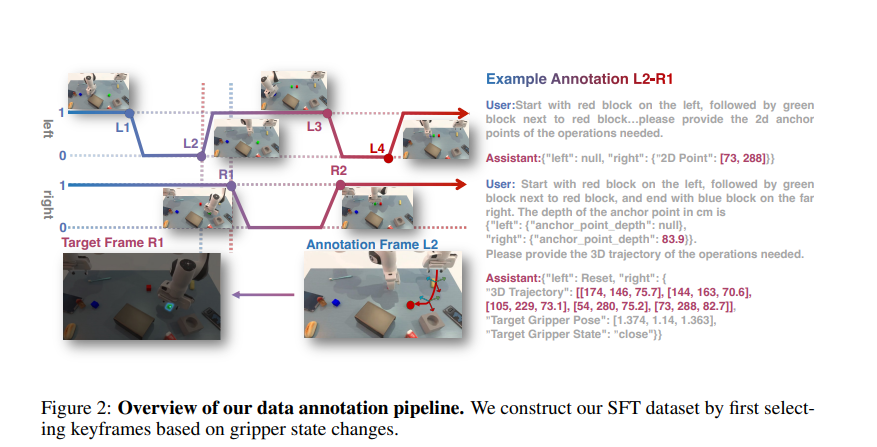
关键帧选择
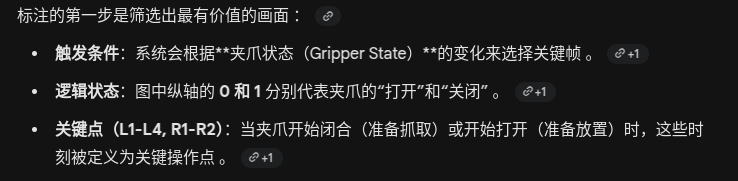
标注对话示例
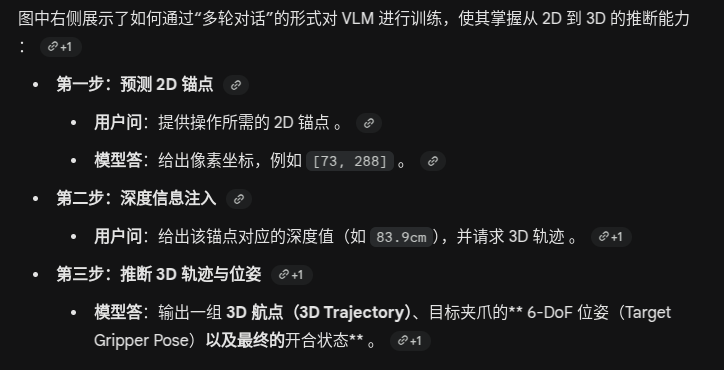
这种训练方式让 VLM 学会了如何根据 2D 图像和深度先验,在脑海中构建出物理世界的 3D 运动路径 。
由于采用的是对话式的 SFT(有监督微调),VLM 在学会给机器人指路的同时,能最大程度地保留其原有的语言和推理能力
这里好像就给给了 一个关键点的深度信息,这足够吗?为了获得轨迹是不是应该给出更多的深度信息?

VLM 本身是在海量互联网数据上预训练的,拥有强大的视觉空间推理能力 。
论文的核心理念是不要让 VLM 去干“体力活”; 保持接口简洁
什么是 point cloud downsampling
从原始的 3D 点云数据中提取出一个规模更小、更具代表性的点集的过程
为什么需要下采样

论文中的下采样方法

其他

动作模型

全连接层的作用
使得 S,P 经过全连接层可以对齐,方便拼接
我一直很好奇,为什么 现有掩码 再 不加以掩码这样的方式不会破坏预训练的结果,请从数学上证明为什么是可行的?

目标函数分解
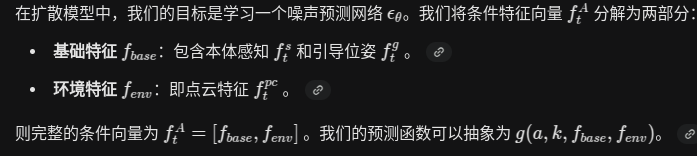
预训练

学习残差修正

LocoFormer: Generalist Locomotion via Long-context Adaptation
https://arxiv.org/pdf/2509.23745
什么是 a few hundred milliseconds of environment interaction in context.?为什么这样就已经sufficient when training specialist controllers on single embodiments

什么是上下文中的数百毫秒环境交互?
在控制机器人运动时,AI 模型不仅看当前的传感器数据,还会参考一段过去的交互历史,这被称为“上下文” (Context) 。
时间尺度: 这里的“数百毫秒”意味着 AI 只保留极短的记忆(通常在 100ms 到 500ms 之间)。
内容: 这些信息包括机器人过去几步的关节位置、传感器读数和采取过的动作 。模型利用这段极短的历史来预测下一步该如何保持平衡。
为什么这对“单一体态的专家控制器”是足够的?
专家控制器 (Specialist controllers) 是专门为某一种特定机器人(单一体态,Single embodiment)量身定制的 。在以下情况下,短记忆是足够的:
物理特性已知且固定: 因为机器人是特定的,它的腿长、重量分布和电机性能在训练时就已经确定了,模型不需要通过长期的记忆来“摸索”自己身体的构造 。
仅需应对瞬时干扰: 对于特定机器人来说,控制的关键在于应对突发的小扰动(如踩到小石子或被轻推一下)。这些物理反应通常发生在毫秒量级,因此几百毫秒的历史足以让模型识别这些瞬时变化并做出反应 。
任务空间窄: 在任务非常单一的情况下,模型只需要保持在已知的物理分布内运行,不需要复杂的在线推理或长期策略调整
奖励函数

整体目标:最大化期望折扣回报

公式变量拆解
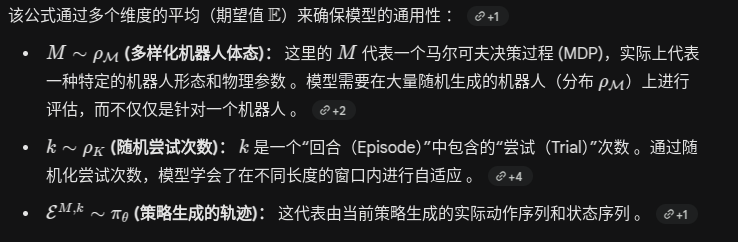
累计奖励计算
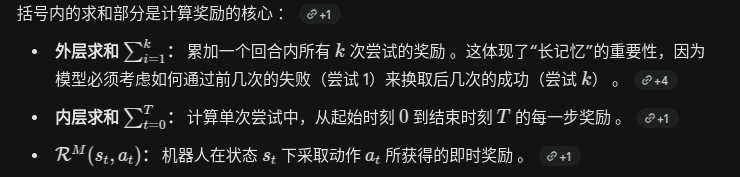
跨尝试的折扣因子
为什么说 通过前几次的失败(尝试 1)来换取后几次的成功(尝试 k);奖励不是要 完成 所有k此尝试 才会算出来的吗?第一次和第k次的 policy没变化 吧
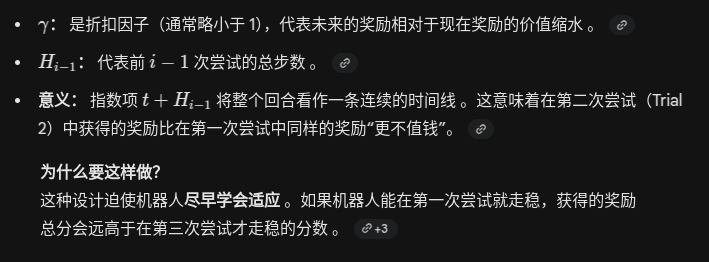
“参数”没变,但“行为”变了

用失败换成功
奖励确实是完成所有 k 次尝试后累加算出来的 ,但也正因如此,模型在训练阶段学会了博弈策略:
识别未知的身体: 当模型被部署到一个从未见过的机器人身上时,它最初并不清楚这个身体的运动学参数 。
牺牲局部,换取全局: 如果模型为了追求第 1 次尝试不摔倒而采取极度保守的动作,它可能永远无法收集到足够的动力学反馈 。
训练出的涌现行为: 由于训练的目标是最大化整个 Episode 的总分 ,模型在海量数据训练中“意识到”,利用第 1 次尝试去大胆探索(即使可能导致跌倒或低分),可以获取关键的物理反馈数据 。有了这些数据,它在接下来的第 2 到第 k 次尝试中就能走得非常稳健,从而让总分(1 到 k 的总和)达到最高
TXL policy
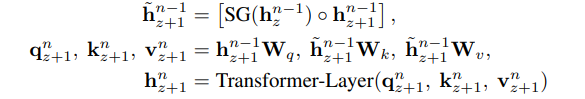
记忆拼接与梯度截断

生成查询、键和值

状态更新

. Let hnz ∈ RL×d denote the hidden states of the n-th Transformer layer for segment σz.
framework
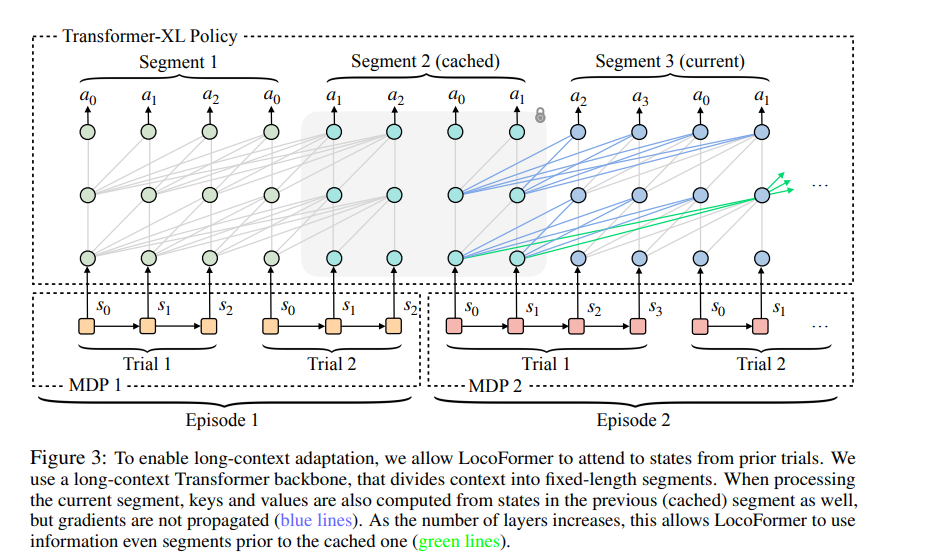


为什么 一次 segment可以跨 trial ,甚至跨 episode? 不应该 一次segment 必然有且只有一个trial的一个时间刻的 observation吗?
Segment :是由 L 个 Token 组成的固定长度序列(例如 L=128) 。所以,一个 Segment 并不是一个点,而是一段“数据块”
为什么segment会跨越trials?
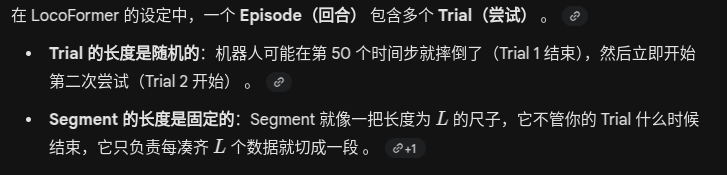
如果 Trial 1 只有 50 步,而 Segment 长度 L=128,那么这一个 Segment 必然会包含 Trial 1 的全部数据 以及 Trial 2 前 78 步的数据。这种“连续性”是 LocoFormer 学习跨尝试自适应的核心——模型必须在同一个上下文窗口里看到“我是怎么摔的”和“我现在该怎么走”,才能学会改进
也就是说,对于这个公式,网络的层数取决于 划分的 segment个数,数据在网络中一层层传递,最终输出时包含了这 好几个 观察 tokens 的信息;而 SG(hn−1z)◦ hz+1n−1 则表示,在当前 第 n-1 层这个网络层,我们去观察他上一次传递时的信息,然后进行拼接;拼接后的向量放在k和v,这样的拼接看似会增大向量长度,但根据交叉注意力的规则,交叉注意力的输出长度只和q有关,所以实际上不会增大向量长度. 我这样的理解对吗?
yes
网络层数是固定的: 网络层数 N 是在模型设计时就定死的一个超参数(例如论文中提到的 6 层)。它不取决于划分了多少个 Segment
极小 3D 归纳偏差 是什么意思
什么是 3D 归纳偏差?
在传统的 3D 视觉算法中,开发者通常会将大量的几何物理规则直接编码进模型中。这些“预设假设”包括:
对极几何(Epipolar Geometry):假设不同视角间的像素对应关系必须落在特定的几何线上。
相机投影模型:预设光线如何通过针孔或镜头投射成 3D 坐标。
三角测量(Triangulation):强制要求模型通过几何交点来计算深度。 这些规则虽然在数学上是完美的,但在面对现实世界中的遮挡、光照变化或低分辨率时,往往显得过于死板
“极小”意味着什么?
VGGT 论文指出,其模型是一个极简的、大型前馈 Transformer 架构。
架构通用化:它不使用针对 3D 任务设计的特殊层(如代价体积 Cost Volumes),而是使用最通用的 Transformer 块。这种架构对数据结构几乎没有假设,除了最基础的序列关系。
数据驱动而非规则驱动:模型不依靠人为定义的几何公式,而是通过在海量的 3D 标注数据上进行训练,让模型自己从数以千万计的样本中“领悟” 3D 空间的物理规律。
灵活性:正因为“偏见”极小,模型不会被错误的几何假设束缚。它可以处理传统优化方法难以应对的极端情况(如极宽基线、稀疏视角)。
DVGT: Driving Visual Geometry Transformer
https://arxiv.org/pdf/2512.16919
framework
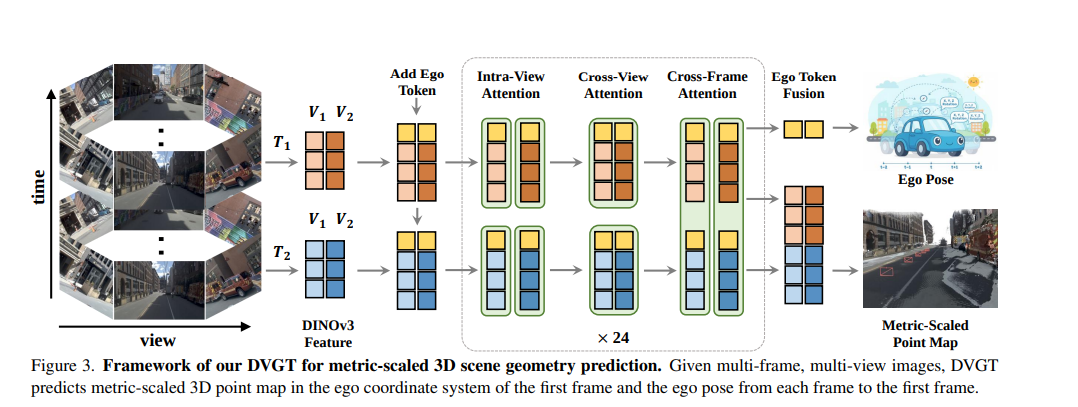
输入与特征提取
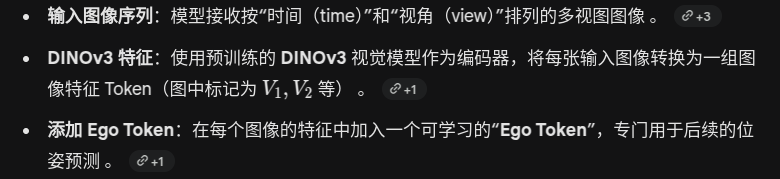
空间-时间几何 Transformer
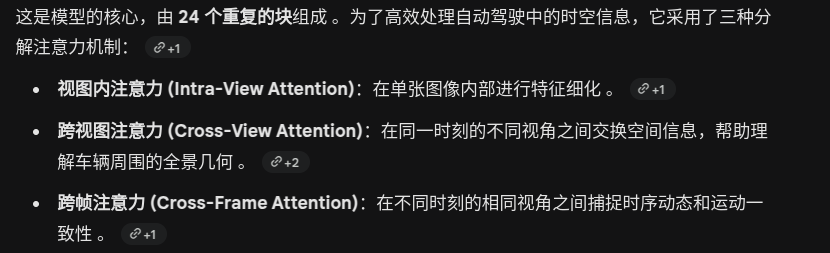
输出头 (Prediction Heads)
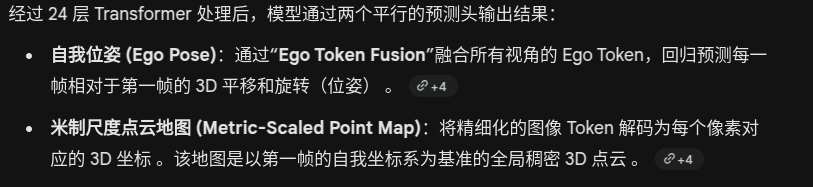
DVGT与VGGT对比
每一个查询 Token(Query Token,红色方块)都会与序列中所有帧、所有视角的全部 Token(蓝色方块)进行交互
虽然信息融合全面,但会产生巨大的计算开销,对于需要高实时性的自动驾驶场景来说是不可行的
文中提到,可以 通过将单目深度预测与投影的稀疏 LiDAR 深度进行对齐来生成“伪标签,这是怎么做到的?
两个核心组件
单目深度预测 (Monocular Depth Prediction):
使用深度学习模型(如文中提到的 MoGe-2 或一般的单目深度模型)从单张 RGB 图像预测深度图 。
特点:它能预测出稠密的(每个像素都有)深度,但通常是相对尺度。模型知道 A 比 B 远,但不知道 A 距离相机到底是 10 米还是 15 米 。
投影的稀疏 LiDAR 深度 (Projected Sparse LiDAR Depth):
LiDAR 传感器可以直接测量物理距离(米制尺度),但它的点云投影到图像上时是非常稀疏的(只有少数像素有点,大部分像素是空的) 。
对齐的目的就是利用 LiDAR 提供的少量准确锚点,去校准单目模型预测出的整张稠密深度图,从而获得一张既稠密又具有真实物理尺度的深度图
对齐的过程

虽然这种方法可以生成伪标签 (Pseudo-labels) 来训练模型,但存在问题
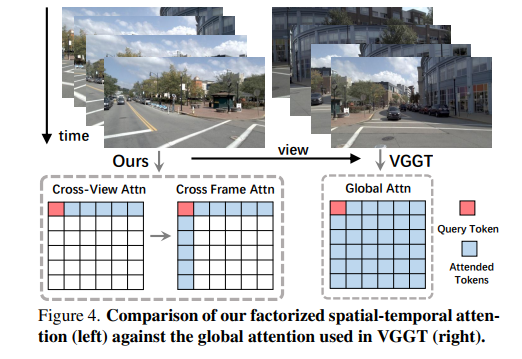
自注意力数据流及其相关代码
对每一轮外层循环 i(aa_block_size=1 时,一轮对应深度上的一层索引):
用当前的
tokens(上一轮 cross-frame 的输出;i=0时是 patch + special token)进入 intra_view → 得到中间结果 ①① 再进入 cross_view(输入已是①,不是初始 token)→ 得到 ②
② 再进入 cross_frame → 得到 ③
下一轮 i+1 的 intra 用的是 ③ 作为输入,以此类推
for i in range(self.aa_block_num):
for attn_type in self.aa_order:
if attn_type == "intra_view":
tokens, intra_view_idx, intra_view_intermediates = self._process_intra_view_attention(
tokens, B, T, V, P, C, intra_view_idx, pos=pos
)
elif attn_type == "cross_view":
tokens, cross_view_idx, cross_view_intermediates = self._process_cross_view_attention(
tokens, B, T, V, P, C, cross_view_idx, pos=pos
)
elif attn_type == "cross_frame":
tokens, cross_frame_idx, cross_frame_intermediates = self._process_cross_frame_attention(
tokens, B, T, V, P, C, cross_frame_idx, pos=pos
)在这一次 _process_intra_view_attention 里,每跑完一个 intra block 就把当时的 tokens reshape 成 (B, T, V, P, C) 并 append 进去
每一轮里,三种注意力各跑 aa_block_size 个 block(默认 1 个),并各自把该步输出存进 intermediates(维度仍是 C)。然后在这一轮末尾做拼接
for j in range(len(intra_view_intermediates)):
# concat intermediates, [B*T*V, P, 3C]
concat_inter = [cross_frame_intermediates[j], cross_view_intermediates[j], intra_view_intermediates[j]]
output_list.append(torch.cat(concat_inter, dim=-1))这样的 「混合得还少」走向「混合得更充分」 ,每一层输出一点到 最终结果,是 自注意力架构的普遍特χ_{0}: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies征吗
这不是自注意力架构的普遍默认。很多任务(例如分类)只取最后一层的一个 token 或池化结果。
多层特征再融合(例如 DVGT 里 DPT 用
intermediate_layer_idx取多层)是针对密集预测 / 多尺度的常见工程选择,和 FPN、U-Net 跳连、DPT 论文一脉相承:浅层偏细节、深层偏语义,拼在一起往往对深度/几何更好。换成分类头,可能就只用最后一层。
χ_{0}: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
https://arxiv.org/abs/2602.09021
核心观点: 资源规模并非唯一决定因素
作者认为,虽然架构演进和资源扩展(如更多的数据、更强的算力)很重要,但机器人执行策略是否鲁棒,其决定性因素在于分布的不一致性。 这种不一致性被作者称为阻碍鲁棒性的“隐藏恶魔”
为了量化分析这一问题,作者将机器人学习管道划分为三个截然不同的分布
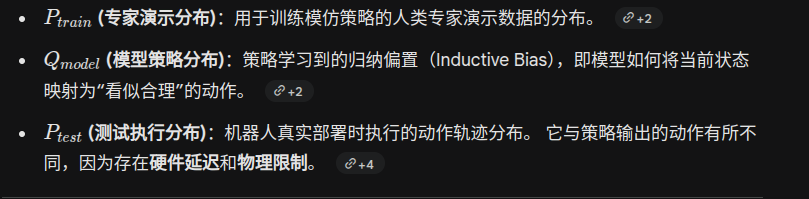
framework
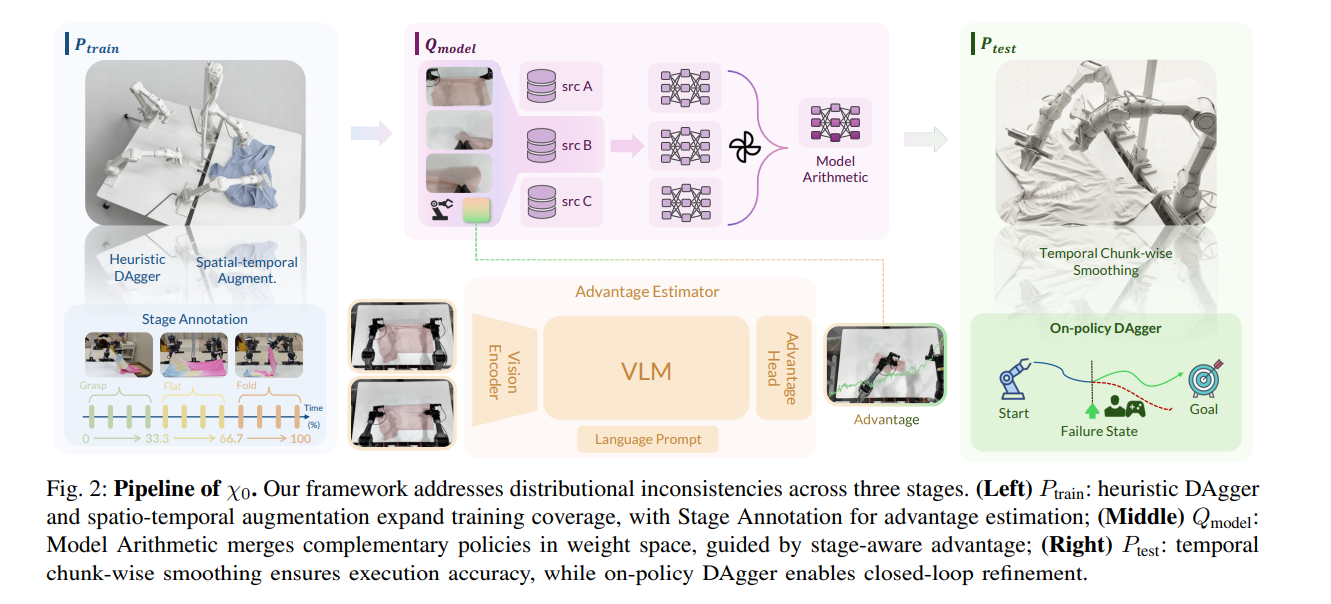
左侧:训练分布 (Ptrain) —— 扩展数据覆盖
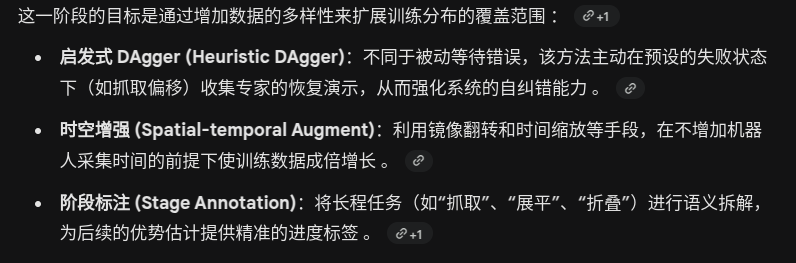
中间:模型分布 (Qmodel) —— 权重空间集成

直接从成对的图像输入中预测动作的“优势”值 , 这个 优势值然后会被输入到哪?
转化为“最优性指示器” (Binary Indicator)
输入到“优势加权回归” (Advantage-Weighted Regression)
指引“模型算术” (Model Arithmetic) 的权重优化
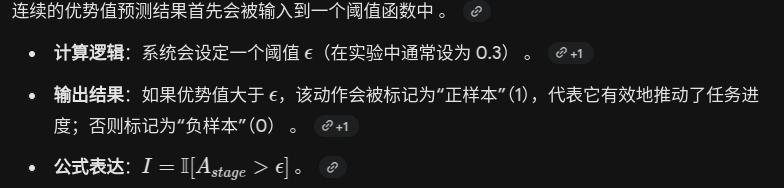
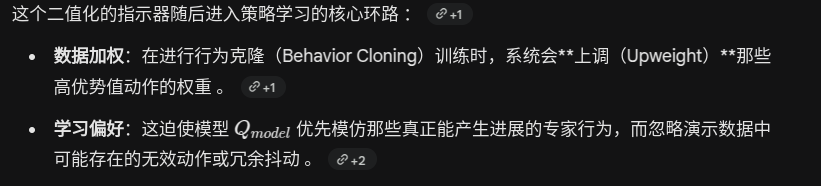
右侧:部署分布 (Ptest) —— 确保执行精度

轨迹分布的数学定义


如何理解 Ptest ?


为何会 缺乏对当前“阶段”的精准把握 ? 在马尔科夫链中,s不包含当前的步骤信息吗?

stage_advantage 文档写明:stage_progress_gt 要 Step 0 人工标注 子任务边界,再按段内线性插值写入 parquet,和 observation.state、action 并列——说明 「精准阶段/进度」在管线里是监督信号,不是原始观测自带的字段
标准 LeRobot 样本里是
observation.state、action等;「当前是第几个子任务 / 进度多少」并不是传感器天然就有的通道。kai0 里甚至需要人工标注stage_progress_gt才能训练 advantage(见下),这从工程上说明:原始数据里并没有自动、精准的「阶段」标量给策略用。
混合专家模型 MoE
组成部分
专家 (Experts):
这是一组独立的子网络(通常是前馈神经网络) 。
在训练过程中,不同的专家会逐渐变得“偏科”,专门处理特定类型的数据分布或任务 。
门控网络/路由 (Gating Network / Router):
这是模型的“调度中心” 。
它负责查看输入数据,并计算一个概率分布,决定将该输入发送给哪一个(或哪几个)专家进行处理 。
优势
条件计算 (Conditional Computing):这是 MoE 最显著的特点。虽然模型总参数量可能极大(达到万亿级别),但对于每个输入,只有一小部分专家被激活 。
扩展性:它允许在不显著增加推理计算量的前提下,大幅增加模型的知识容量
为什么 通过线性加权相加各个子模型的参数,可以获得新的模型?有什么数学依据吗?
线性模态连通性 (Linear Mode Connectivity)
同一低损失区域:研究发现,当多个模型从同一个预训练初始化点(如论文中使用的 pi0 或 pi0.5)开始进行微调时,尽管它们在不同的数据子集上训练,但它们最终往往会收敛到损失函数曲面(Loss Landscape)上的同一个“低损失盆地”中 。
凸组合的有效性:在这个共同的“盆地”内,损失曲面在很大程度上是凸的。这意味着,如果你在两个表现良好的模型参数点 theta_1 和 theta_2 之间画一条直线,这条线上的点(即它们的线性组合 theta_{merged} = \alpha\theta_1 + (1-\alpha)\theta_2)通常也会落在低损失区域内,甚至可能比原始点更接近盆地的中心 。
权重空间中的“模型汤” (Model Soups) 理论
chi0 采用的 MA (Model Arithmetic) 策略很大程度上借鉴了“模型汤”的概念 。
减少过拟合:每个子模型由于只在部分数据子集($\mathcal{D}_i$)上训练,可能会对该子集产生特定的过拟合偏差 。
噪声抵消:由于不同子集的采样是随机的,它们的过拟合方向往往是不同的。通过加权平均,这些随机噪声和偏差在参数空间中会相互抵消,而真正有助于完成任务的“共性特征”则会得到保留和增强 。
参数冗余 (Parameter Redundancy):论文提到,大型模型(如视觉语言动作模型 VLA)存在极高的参数冗余 。这使得模型能够像大型语言模型一样,通过简单的算术运算吸收不同子模型的互补能力,而不会产生严重的参数冲突
那为什么 有些 模型 还要用moe架构?
MA 是将所有知识强行“熔炼”到一组参数中。对于机器人操纵(如折叠衣服)这种相对聚焦的任务,参数冗余足以支撑这种融合 。但如果要合并一个顶尖的“代码专家”和一个“创意写作专家”,强行加权平均可能会导致两个领域的精细能力相互干扰,即参数干扰 (Parameter Interference),导致“样样通,样样松”
什么是自回归 (Auto-regression, AR)?
在通用机器学习中,自回归模型是指一个变量的值取决于其自身过去值的模型。在机器人和大型视觉-语言-动作模型 (VLA) 的背景下,它通常指:
序列依赖性:模型在生成输出(如动作序列)时,当前的输出会作为后续输出的参考基础 。
逐步生成:例如,模型预测第 t 步的动作时,会考虑到 t-1 步、 t-2 步的状态或动作轨迹 。
在 VLA 中的应用:像文中提到的 pi_0 或 pi_{0.5} 等基础模型,往往具有这种处理序列数据的能力,从而能理解动作之间的时序关系 。
自回归是一种统计学或机器学习的属性, 可以用 RNN(把 RNN 在 t-1 时刻生成的动作 a_{t-1} 作为输入喂回给 t 时刻),也可以用Transformer
什么是优势加权回归 (Advantage-Weighted Regression, AWR)?
这是一种将强化学习 (RL) 任务转化为监督学习 (SL) 问题的算法。它的核心目标是:在模仿学习的基础上,给那些表现更好的动作更高的关注。
核心原理
不平等对待采样:传统的模仿学习(如行为克隆)平等对待所有专家数据。但 AWR 会根据“优势信号 (Advantage Signal)”对训练样本进行加权 。
优势 (Advantage):表示在当前状态下,执行某个动作比平均水平(价值函数 V(s))好多少 。
学习权重:具有更高“优势”的动作在损失函数中拥有更大的权重。这意味着模型会更强烈地倾向于模仿那些能够显著推动任务进度(高回报)的动作 。
AGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
https://arxiv.org/pdf/2602.04672
“neural rendering often yields fragmented, non-simulation-ready geometries” , 什么是神经渲染?
当前最先进的重建方法通常依赖于 NeRF(神经辐射场) 或 3D Gaussian Splatting(3D 高斯泼溅) 等技术 。
多视图依赖:这些方法的基础是“多视图一致性”,即从多个角度观察同一个点来确定其 3D 位置 。
遮挡困境:在手部抓握物体的场景中,手会严重遮挡物体 。由于神经渲染无法“看到”被手遮挡的部分,它很难推断出物体完整的 3D 形状 。
什么是“脆性的运动恢复结构(Brittle Structure-from-Motion, SfM)”?
什么是 sfm 初始化 ?
Structure-from-Motion (SfM) 是一种经典的计算机视觉技术,其核心任务是通过分析 2D 图像序列中特征点的移动,来同时推算出摄像机的运动轨迹(姿态)和物体的 3D 几何结构 。
在手-物交互(HOI)重建中,SfM 通常被用作初始化步骤,为后续的神经网络渲染提供最基础的 3D 参考坐标 。如果这个第一步算错了,后面的模型就像盖在流沙上的大楼,会直接“崩塌” 。
为什么说它是“脆性”的
剧烈运动与模糊(Rapid Motions)
原理:SfM 假设两帧图像之间有足够的重叠和清晰的对应关系。
失效点:在真实的抓取动作中,物体往往移动得很快 。快速运动会导致视频产生运动模糊,使得原本清晰的特征点变得无法识别,导致跟踪链条中断 。
严重遮挡, 纹理匮乏
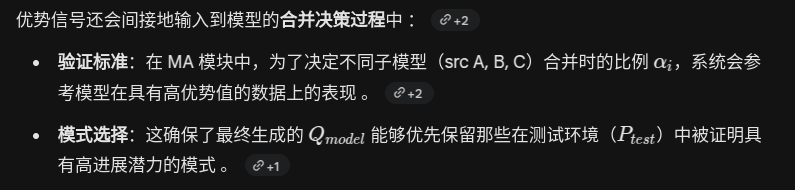
StereoVGGT: A Training-Free Visual Geometry Transformer for Stereo Vision (partial reading)
https://arxiv.org/abs/2603.29368
这里为什么 dino v2 经过 reweight 之后,应该 既有 dino 也有 vggt 的能力了,那为什么 dino v2后还要接 vggt fa?
DINOv2 输出的特征图(Feature Map)虽然还是原始的 Token 序列(空间一致性:DINOv2 输出的特征图通常保留了原始图像的空间结 构),但这些特征里已经包含了对遮挡、边缘和几何深度的特殊关注
DINOv2 输出的是通用的高维视觉特征。VGGT FA 的作用是将这些特征投影(Project)到专门用于几何对齐的空间中
原本 vggt 架构中就包含了 一个 dino, VGGT FA 将这一层拆掉了
vggt 的输出不就是可以包含 深度图的吗?为什么 还要跟 IGEV 这种 disparity decoder 以输出 disparity map?
论文指出,虽然 VGGT 在预训练中学习了丰富的 3D 几何先验(包括相机位姿和深度),但它在特征提取过程中存在严重的空间结构退化和模糊(Structural Degradation) 。
平滑效应:VGGT 倾向于抑制特征细节以减少 3D 重建中的误差积累,这导致物体的边缘轮廓变得模糊 。
不兼容性:这种“平滑”特性与双目立体匹配所需的像素级精确对齐是架构冲突的 。如果直接使用 VGGT 的深度输出,其精度无法达到 SOTA 立体匹配的要求。
StereoVGGT 的做法是将 VGGT 改造为一个强大的 Backbone,为解码器提供既有“相机几何常识”又保留了“空间细节”的特征
论文目前的做法是利用 VGGT 的权重来“重塑” DINO 的特征(通过 EMWM 和双分支颈部) 。VGGT 在这里扮演的是“老师”或“导向”的角色; 优化建议 将 Stereo 的结果或特征 concat 到 DINO 输出上作为 VGGT 的输入,甚至把初步估计的 Pose 也扔进去,把 VGGT 当作一个前向优化模块
原论文做法:把 VGGT 当作产生特征的 Backbone,但 VGGT 提取的特征存在“结构化退化”和模糊问题 。
建议做法:
先让专门的 Stereo 模块(如 IGEV)产生高质量的立体匹配结果 。
将这个结果与 DINO 特征拼接,输入给 VGGT。
此时 VGGT 扮演 Refiner(优化器) 的角色,它利用其对相机位姿(Pose)的隐式理解,去修正 Stereo 结果中不符合几何规律的部分
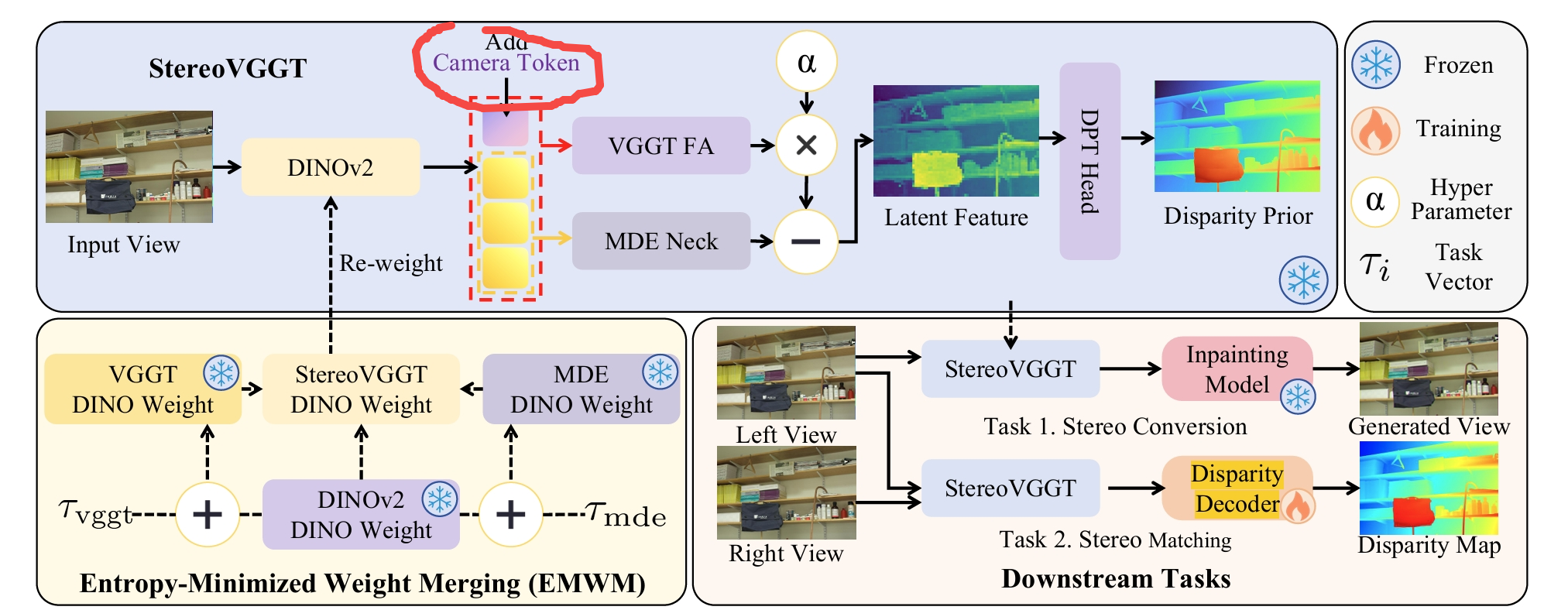
Scal3R: Scalable Test-Time Training for Large-Scale 3D Reconstruction
https://arxiv.org/pdf/2604.08542
VGGT-Long,如何理解 its alignment is highly sensitive to local accuracy
论文中提到的 VGGT-Long 采用了“分而治之”的策略 。因为它无法一次性处理极长的视频,所以会将视频切分成许多有重叠部分的图像块(Chunks) 。
模型会先独立地重建每一个图像块的 3D 几何结构 。
最后,利用这些块之间重叠的区域,像“拼图”一样把它们旋转、平移、缩放,对齐到一个统一的坐标系中,形成完整的场景 。这个拼接的过程就叫 Alignment
为什么说它对“局部精度”高度敏感?
因为在 VGGT-Long 这种架构中,每个图像块是独立处理的,彼此之间没有信息交流(缺乏全局上下文) 。
误差累积: 如果“图像块 A”预测的相机姿态或深度稍微偏了 1 度,那么在对齐“图像块 B”时,这个微小的偏差就会被放大。
Test-Time Training, TTT
conventional method
传统的 RNN(循环神经网络)将成千上万帧的信息压缩进一个固定大小的向量(Hidden State)里,这就像试图把整本书的内容记在一张小纸条上,必然会导致信息丢失

TTT:它将“纸条”换成了一个小型神经网络的权重 。
由于参数的表达能力远大于单个向量,它能存储的上下文信息量级大大提升,从而能更精准地处理超长视频或公里级的大规模场景重建
内循环与外循环的训练顺序与关系
训练阶段:端到端同步
内循环更新(前向传播的一部分)模型获取输入图像块。使用当前外循环定义的投影层生成 k 和 v 。执行内循环:通过自监督损失函数 W <-- W计算梯度,并更新快速权重 W 。
self.qkv 是训练阶段就学好的慢参数。
注意:这个更新过程是在“前向传播”中完成的,其结果是产生了一组临时进化的 W
前向传播应用
使用这组更新后的 W 来处理查询向量 q,得到增强后的特征输出 o = fW(q) 。模型的主预测头根据 o 预测出相机位姿、深度图和点云
外循环优化(反向传播)
计算最终预测结果与真实标签(GT)之间的 3D 重建总损失 L 。
关键点:梯度会穿过 W 的更新公式,一直回传到投影层和主干网络的初始参数上
GCM 如何接入 VGGT ?

推理(测试)阶段:只有内循环在动
在实际场景中使用 Scal3R 时:
外循环参数固定:q, k, v 投影矩阵已经练好了,不再改变 。
内循环动态适应:模型边处理视频,边利用公式 (3) 的自监督逻辑实时更新W 。这让模型能针对当前从未见过的公里级场景进行“现场学习”
公式


framework
数据的并行分块处理 (Chunking)

特征提取与自适应记忆 (AMU & GCM)
局部 3D 重建 (Decoding)

全局对齐与缝合 (Alignment)

核心公式
基础交替注意力操作

增强后的全局上下文操作
残差门控机制

全局上下文

为了提高计算并行度和 GPU 利用率,Scal3R 不再逐帧更新,而是将整个图像块(Chunk)内的所有 Token 作为一个单一的更新单元 。

为什么说 “While the GCM module effectively captures intra-chunk context, it remains confined within individual chunks and lacks the ability to exploit sequence-wide global context.”?好像和framework图片不怎么相符
物理上的隔离:多 GPU 并行
GCS 是那座“桥梁”

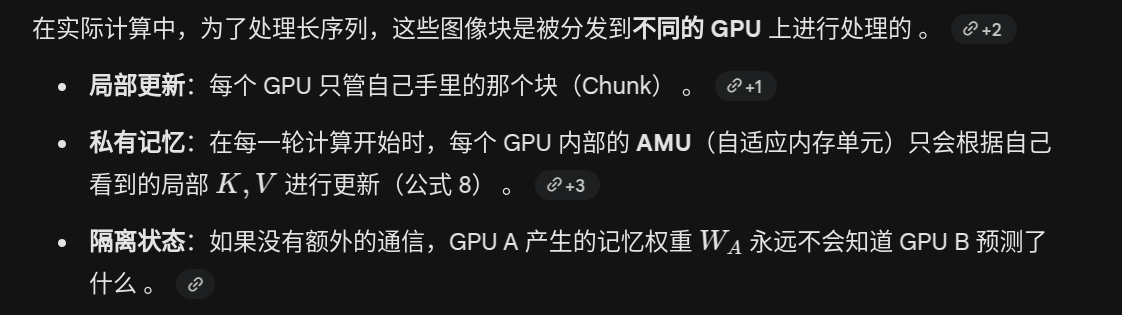
WildDet3D Scaling Promptable 3D Detection in the Wild
https://arxiv.org/pdf/2604.08626
framework
WildDet3D 是一个支持多种提示模态(文本、2D 点、2D 框)并能灵活利用可选深度信息的开放世界单目 3D 目标检测框架
双视觉编码器 (Dual-vision encoders)
位于图的左侧,模型采用了分离的双编码器设计来分别处理视觉和深度信息 :
图像编码器 (Image Encoder): 接收输入的 RGB 图像,负责提取高分辨率、多尺度的视觉语义特征 。
RGBD 编码器 (RGBD Encoder): 作为一个即插即用的几何后端,它接收 RGB 图像以及可选的(Optional)局部或完整深度图(例如来自 LiDAR) 。即使没有深度雷达输入,它也能依靠纯图像生成深度潜在特征(Depth Latents) 。
深度融合模块 (Depth Fusion Module)
对应图中黄色的区域。它的作用是将 RGBD 编码器提取出的几何深度特征,完美地融入到图像语义特征中 :
深度特征(Depth Latents)首先经过层归一化(Layer Norm)、双线性上采样(Bilinear Upsampling)对齐分辨率 。
然后通过一个可学习门控(Learnable Gates,即零初始化的 1x1 卷积)与图像特征进行逐元素相加 。
这种设计能在不破坏预训练视觉特征的前提下,生成富含深度信息的特征图(Depth-Aware Features),为后续的 3D 定位提供精确的度量支持 。
可提示检测器 (Promptable Detector)
位于图的中上方。它接收用户输入的提示(可以是文本、2D 框或 2D 点),并将这些提示与前面融合好的深度感知视觉特征结合起来,生成用于目标检测的统一查询向量(2D Queries) 。
3D 检测头 (3D Head)
对应图中红色的区域,这是生成 3D 边界框的核心部件。它负责将平面的 2D 查询“提升”为立体的 3D 预测 :
2D Queries 进入 Transformer 架构后,通过交叉注意力机制(Cross Attention),先后融合了相机射线嵌入(Camera Ray Embeddings)提供的空间方向信息,以及深度特征(Depth Latents)提供的距离信息 。
经过多层特征交互后,通过多层感知机(MLP)预测出物体在三维空间中的中心点、尺寸和旋转角度 。
同时,该模块还会并行预测出一个 3D 置信度得分(Confidence),用于评估 3D 几何估计的准确性 。
辅助检测头 (Auxiliary Heads)
除了主角 3D 检测头,架构的最右侧还展示了 2D 检测头 (2D Head) 和 深度估计头 (Depth Head) 。虽然该系统的首要任务是预测 3D 框,但这两个辅助头能提供互补的监督信号(补充 2D 空间先验知识和全局几何结构),从而大幅提升最终 3D 目标检测的整体性能

LiDAR-based method的描述介绍
优势:“提供直接的几何测量”
(LiDAR-based methods provide direct geometric measurements)
含义:激光雷达通过发射激光束并测量回波时间,能够直接且极其精准地获取物体到传感器的物理距离(深度)
劣势:“生成稀疏的点云,缺乏可靠的高度信息和完整的 6自由度(6-DoF)旋转线索”
(but produce sparse point clouds that lack reliable height information and full 6-DoF rotation cues)
稀疏的点云:LiDAR 扫描出来的世界是由一个个离散的“点”组成的。与相机几百万像素的密集图像相比,点云非常稀疏(尤其是在远处的物体上,可能只落了零星几个点)
缺乏可靠的高度信息:因为点太稀疏,激光束经常会漏扫物体的最顶部或最底部,导致系统很难精准判断物体的确切高度 。
缺乏完整的 6自由度旋转线索:6自由度(6-DoF)指的是物体在三维空间中的位置(X, Y, Z)和姿态(Pitch俯仰、Yaw偏航、Roll翻滚)。因为点云只有形状轮廓,缺乏表面的丰富纹理(比如你看不清车灯朝向、文字正反),所以仅靠几个稀疏的测距点,很难判断一个物体是不是发生了倾斜、侧翻等复杂的旋转姿态 。
3. 局限性:“限制了它们只能应用于具有明确‘直立先验’的类别”
(limiting their applicability to categories with well-defined upright priors)
直立先验 (Upright Priors):指的是一种默认的物理常识——某些物体总是直立在地面上的,不会随意翻滚。比如汽车、行人和自行车。在自动驾驶中,系统可以直接假设这些物体的俯仰角(Pitch)和翻滚角(Roll)都是 0,只需要计算水平偏转角(Yaw)即可。
什么是“multi-level convolutional neck”(多层级卷积颈部网络)?

什么是 Multi-level(多层级)?
在现实世界中,物体的大小远近各不相同(比如镜头前的一个大苹果和远处的汽车)。如果模型只在单一的尺度上观察特征,很容易漏掉极大或极小的物体。
多尺度特征金字塔: “多层级”意味着这个颈部网络会输出不同分辨率大小的特征图(Feature Maps)。
各司其职: 高分辨率(大尺寸)的层级保留了更多边缘和几何细节,适合捕捉小物体;低分辨率(小尺寸)的层级则包含了更广的全局上下文信息,适合理解大物体。
这个“multi-level convolutional neck”的具体工作流程是这样的:
预训练的 RGBD 主干网络首先“吃”进图像和深度图,提取出原始的几何特征。
这些原始特征随后被送入这个多层级卷积颈部网络(在论文的具体实现中,它是一个名为 ConvStack 的结构,能生成 5 个层级的特征金字塔)。
该“颈部”将不同尺度的特征进行加工提炼,最终输出高质量的多尺度 “深度潜在特征(Depth Latents)”。
这些提炼好的深度特征,随后就可以被顺畅地送入下一个模块(Depth fusion module),与另一条流水线上的图像语义特征进行无缝融合。

虽然这里没有将 VAE和 DiT一起用,但ViT 确实经常和 VAE(或其变体)结合使用,有以下情形
图像生成领域
痛点:直接让 Transformer 处理高分辨率图像的所有像素,计算量会呈指数级爆炸。
VAE 的作用:在这些模型(如 Latent Diffusion Models 潜扩散模型)中,首先会训练一个强大的 VAE(通常是 AutoencoderKL)。VAE 的编码器负责将高清图像“压缩”成尺寸很小、但包含丰富语义的“隐特征图(Latent space)”。
Layer Normalization and Batch Normalization

深入解析 BN (Batch Normalization)
计算维度:在 Batch(批次)维度上进行计算。
优势:在卷积神经网络(CNN,如 ResNet)中效果极好,能极大加速训练,并自带一点正则化效果(防止过拟合)。
致命弱点:
极度依赖 Batch Size(批次大小)。如果硬件显存不够,每次只能送入 1~2 张图片(Batch Size 极小),算出来的均值和方差就会偏差巨大,导致模型崩溃。
不适合处理变长序列。在自然语言处理(RNN)中,每句话长度不一样,用 BN 很难对齐计算。
深入解析 LN (Layer Normalization)
计算维度:在 Feature/Channel(特征通道)维度上进行计算。
优势:
完全独立于 Batch Size。即便每次只送入 1 张图片(Batch Size = 1),LN 依然能完美计算并发挥作用。
天然契合序列模型和 Transformer。在处理不定长的文本或图像 Patch 时表现极其稳定。
应用场景:目前几乎所有的 Transformer 架构(包括 ViT、GPT、BERT) 的标配都是 LN。
特征融合的核心数学公式 V′ = V + Conv1×1(LN(Zd↑ ))

假设 深度图是 49 49 的 网格,而视觉图 V 是 64 64 的 ;为了相加,会将深度图进行双线性插值,计算周围像素的加权平均值,把 49 49 的深度特征图平滑地“撑大”到 64 * 64
深度特征里那 256 个数字可能特别大(比如 500),而视觉特征里的数字可能很小(比如 0.5)。直接相加会把视觉特征“淹没”掉。
处理:层归一化(LayerNorm)会单独盯住“猫”这个位置的 256 个深度数字,算出它们的平均值和方差,然后强行把它们“压”到一个标准范围内(比如均值为 0,大部分数值在 -3 到 +3 之间)。
1*1Conv : 对于一个像素,可能有256个通道,1*1Conv相当于对其做了一个加权平均,得到一个值,完成 256--> 1 ; 如果想要输出通道有更多,那么再加一些卷积核就行
Pi3
https://arxiv.org/pdf/2507.13347
排列等变性(Permutation-Equivariant Property)

公式 (3) 说明,如果我们把输入序列 S 按照 pi 的规则打乱成了 (Ipi(1), ... , Ipi(N)),那么输出的相机位姿序列、点图序列和置信度序列,也会严格按照这套 pi 的规则进行一一对应的重排 。比如,无论图像 A 被放在第几个输入,网络为它计算出的位姿 TA 永远是同一个值。
pi3 故意去除了网络中所有与顺序相关的组件(比如用来区分帧先后的位置编码),从而在数学上严格实现了“排列等变性”
解决 尺度模糊(Scale Ambiguity)

这个公式的目的,就是在训练模型时,寻找一个最优的全局缩放比例(尺度因子 s*),把模型预测出来的 3D 点云统一放大或缩小,使其与真实的 3D 点云尽可能对齐,从而计算误差。
argmins:数学运算,意思是“寻找一个 s的值,使得右边这整串误差表达式的结果最小”
1/zi,j: 这是一个深度权重。zi,j 是真实点坐标的深度值(即 Z 轴坐标,距离相机的远近)。
为什么要除以深度? 在 3D 视觉中,物体离得越远,预测的绝对误差通常就越大。
各个loss是怎么一起协调训练的?
未标注的置信度 的 BCE loss 监督
在真实的训练数据集中,通常只有真实的 3D 坐标,并没有人工标注好的“置信度”。因此,作者利用了预测误差来动态生成这个答案。
根据刚刚的 深度加权的 L1 重建误差 公式
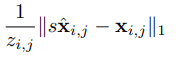
经过上面那一步的转换,预测置信度的问题就变成了一个标准的二分类问题(标准答案非 0 即 1)。
因此,论文使用了机器学习中处理二分类最常用的损失函数——二元交叉熵损失(Binary Cross-Entropy loss, 简称 BCE)来进行监督训练。
交叉熵 数学公式
二元交叉熵损失
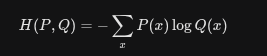
VGGT 可以直接拿网络输出的绝对坐标去和 Ground Truth(真实标签)的绝对坐标对比。那 pi3 也可以在 前向结束的时候(即一个 batch算完之后,准备算loss 的 时候),随便选一个帧然后 将 groundtruth 的对应帧 坐标变换到这一帧,groundtruth的其他帧 相应进行坐标变换,不就也可以坐标对比了吗
如果你随便选一帧作为基准,你实际上是在监督其他 N1 个相机相对于这个基准的位姿。如果基准帧预测得不好,会直接干扰所有其他帧的梯度 。Loss也要对称, 如果在训练的每一轮中,选中的那一帧预测质量波动很大,那么产生的梯度流也会不稳定。 因此 采用如下:
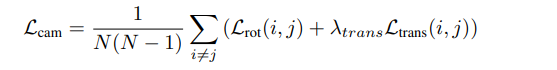
假设一个 Batch 里有 N 张图,N(N-1) 正是从中任选两张(且区分方向,比如 A-->B 和 B-->A 算两次)的总对数。公式把网络预测的所有可能图像对之间的误差加起来,求了一个平均值。第一步预测的 s 参与了这里的Ltrans 预测
VGGT 里

那batch 与 batch 之间 的 相机pose 相对转换 是如何被计算的 ?
训练的时候根本不在乎, 训练的是局部几何先验能力

在融合 深度和rgb的时候,为什么不用 一维卷积 融合特征而是 concat?
如果你使用
Concat + Conv,相当于引入了一个全新的、随机初始化的网络层。这个卷积层会对原本优秀的 DINOv2 特征进行一次强制的线性变换,这会引发灾难性遗忘
Geometric Latent Diffusion
https://arxiv.org/pdf/2603.22275
framework
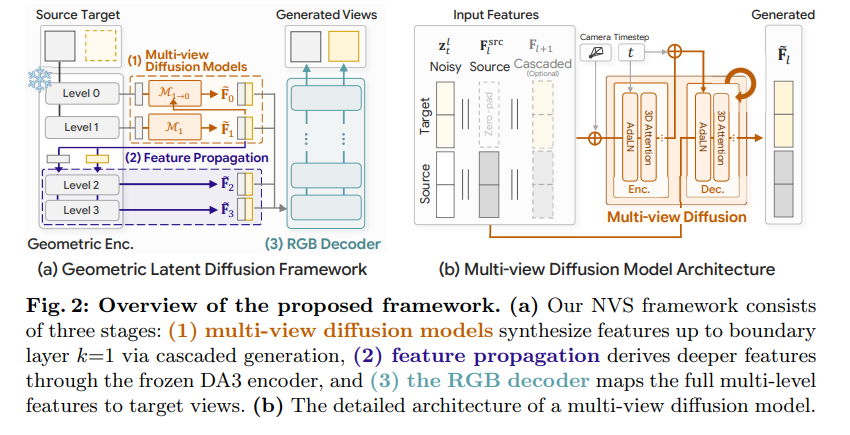
(a) 几何潜在扩散框架流程

(b) 多视角扩散模型架构
AdaLn
它在生成模型(如 StyleGAN、Diffusion Models)中大放异彩,是目前最先进的生成架构(如 DiT - Diffusion Transformer)的核心组件。
标准 LayerNorm (LN)

AdaLN 的演进
AdaLN 的核心思想是:不再让 gamma 和 beta 保持固定,而是让它们根据“外部信息”动态生成。
这个“外部信息”可以是:
类别信息(例如:生成一只“猫”还是“狗”)。
时间步信息(例如:扩散模型中当前的去噪步骤 $t$)。
文本嵌入(例如:一段描述文字)。

VGGT-Ω
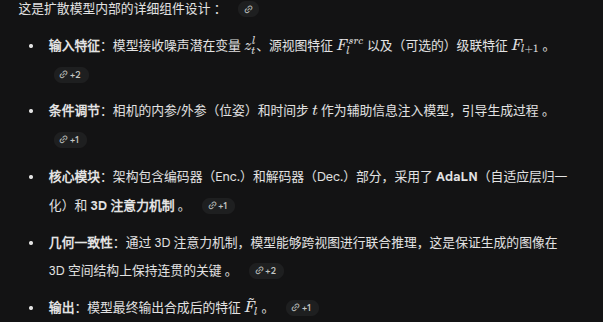
https://arxiv.org/pdf/2605.15195
framework
特征提取与 Token 化(图左侧)

交替注意力机制块(图中央,x L 次循环)

解码器与最终预测(图右上侧)

仅训练使用的监督损失(图右下侧虚线框)

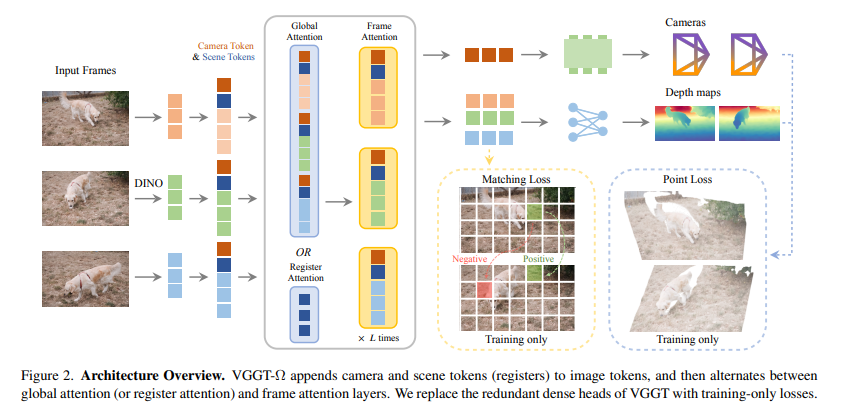
在传统的前馈重建模型中,跨帧的全局注意力矩阵是非常稀疏的
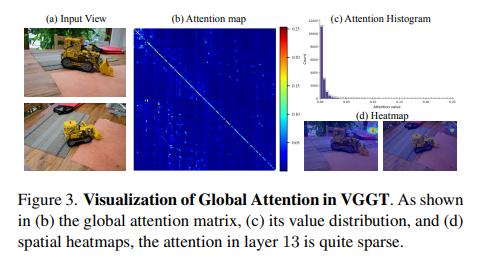
(b) Attention map(注意力矩阵图)
纵轴和横轴代表所有帧的图像 Token 。颜色越趋近于红色代表注意力权重越大,越趋近于深蓝色代表权重越接近于零 。
可以看到,除了对角线(代表图像块自身的自注意力)以及零星分布的亮圈外,绝大多数区域都是深蓝色(接近于 0) 。这直观地证明了不同帧的 Token 之间,实际上绝大部分是不需要进行信息交换的 。
(c) Attention Histogram(注意力权重直方图)
统计了整个注意力矩阵中权重的数值分布 。
横轴是注意力权重的数值,纵轴是频数 。图里出现了一个极其极端的长尾分布——绝绝大多数的权重都在 0.00 附近 。这用数据定量地证明了全局注意力中存在着巨大的计算冗余
核心架构:师生双网络机制 (Teacher-Student Strategy)
在 3D 重建领域,获取带有精确深度和相机轨迹的真实标注数据成本极高 。这节介绍的“师生蒸馏机制”,正是为了让模型能够直接从普通互联网视频中疯狂汲取通用物理世界先验的核心技术 。
论文借鉴了 2D 视觉领域(如 DINO 和 MoCo)的经典做法,在自监督阶段维持两个网络并行处理 :
学生网络(Student Network):通过正常的梯度下降(Gradient Descent)进行实时训练和反向传播更新 。
教师网络(Teacher Network):不参与梯度下降 。它的参数完全来自于学生网络参数的指数移动平均(EMA) 。
把同一个视频序列同时喂给两个网络,但对两边应用完全独立的、随机的增强手段 。这些干扰包括:颜色抖动、模糊、随机 90° 旋转、随机掩码(直接盖住部分图像块),以及随机打乱帧的顺序 。
在对齐后,强迫学生网络在两个层面上向教师网络对齐 :
特征级匹配:利用 l2 损失函数,让学生网络多个注意力层输出的 Token 特征分布去匹配教师网络的特征分布 。
几何级回归:让学生网络预测的相机位姿和深度去对齐教师网络的预测 。
在自监督学习中,网络极易产生“模型崩溃(Collapse)”——即两边网络为了走捷径,无论输入什么都输出一模一样的毫无意义的恒定值,从而让损失函数直接归零。为了防止这种“摆烂”,论文设计了两个关键机制
冻结输出头(Frozen Heads):在自监督训练期间,负责预测相机和深度的两个输出头是被完全冻结(不更新)的 。这迫使所有的梯度更新压力都狠狠地砸在底层的骨干特征网络(Backbone)上,不让输出头投机取巧 。

Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
https://arxiv.org/pdf/2412.09621
Data generation
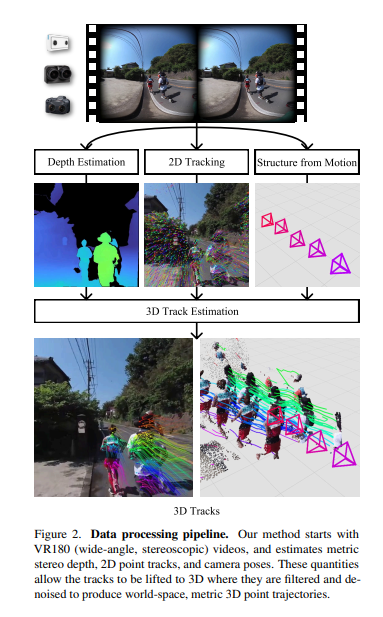
1. 视频输入 (Input)
位于最上方的是输入源:VR180(广角立体)视频 。这类视频包含左右眼两个视角,系统将其作为原始输入来进行后续的三维和运动信息提取 。
2. 并行的三大基础估计任务
视频输入后,系统会并行提取三种不同维度的信息:
深度估计 (Depth Estimation):利用立体匹配算法提取每一帧的度量立体深度图 。图中的蓝绿色热力图表示了场景中物体(如行人)距离相机的远近。
2D 跟踪 (2D Tracking):在 2D 视频画面上,追踪各个点在连续帧之间的二维运动轨迹 。图中间画面上密集的彩色线条即代表了提取出的 2D 像素移动路径 。
运动恢复结构 (Structure from Motion, SfM):计算视频拍摄过程中相机的位姿 。图右侧的一排紫色金字塔模型,直观地表示了相机在三维空间中的移动轨迹和朝向 。
3. 3D 轨迹估计 (3D Track Estimation)
这一步是该流水线的核心融合环节 。系统利用前面计算出的相机姿态和立体深度,将平面的 2D 运动轨迹“提升(lift)”并反向投影到 3D 空间中 。
在提升到 3D 之后,这些初步的 3D 轨迹会经过滤波和降噪优化,以消除逐帧计算深度时产生的剧烈抖动,从而保持动态轨迹的平滑和静态场景的稳定 。
4. 最终输出:3D 轨迹 (3D Tracks)
最下方展示了流水线的最终输出结果:在世界坐标系下、具有真实物理尺度的 3D 点轨迹 。
左侧的画面是将这些 3D 轨迹重新叠加在 2D 图像上的效果;右侧则是一个纯粹的 3D 视角,你可以清晰地看到行人的 3D 点云结构、他们在空间中的长程运动轨迹(彩色线条),以及场景中相机的确切位置(紫色金字塔) 。
3D轨迹估计与优化
系统需要把视频画面(2D)上追踪到的点,放到三维空间(3D)里去. 这样,原本二维的轨迹 j 就变成了一条跨越所有帧的 3D 运动轨迹 pj1, ... , pjN
现在我们有了初版的 3D 轨迹,但这里存在一个大问题:高频时间抖动 (high-frequency temporal jitter) . 抖动的原因:因为“深度图”是系统一帧一帧独立估算出来的,难免会有误差 。假如有一个原本静止的树桩,由于每一帧估算的深度有一点点偏差,在反投影出来的 3D 空间里,这个树桩的 3D 坐标就会在原地前后轻微“鬼畜”抖动,显得很不真实。
解决思路(优化策略):为了消除这种由深度估算不一致引起的抖动,作者提出了一个优化方案 。他们不打算全方位去乱调这个点的位置,而是只允许这个点在一条特定射线上前后移动来修正误差
损失函数
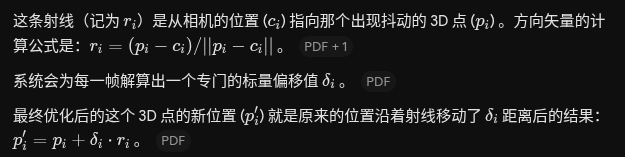
静态损失
在计算同一条轨迹上,任意两帧之间优化d后的点位(p'i 和 p'j)在真实 3D 空间中的距离平方和。(如果一个点是静止的,那它在第 1 帧、第 10 帧、第 100 帧的三维坐标应该是完全一样的。)
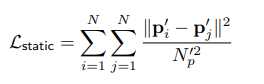
动态损失
括号里的这一长串 (p'i - 2pi + p'i) 在数学上叫“离散拉普拉斯算子”,它在这里的物理意义代表加速度。
这个算子乘以后面的 ri(相机的视线射线),意味着系统在极力减小沿着相机视线方向的加速度。因为深度估算的误差主要表现为顺着镜头方向的忽远忽近。
下面的 W = {1, 3, 5} 代表时间窗口。也就是说,系统不仅看相邻 1 帧的加速度,还要看跨越 3 帧、5 帧的加速度,以此来保证短期和长期运动都非常丝滑。
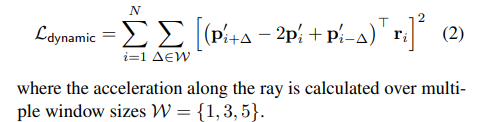
正则化损失
在调整 3D 点的位置时,系统通过加上一个偏移量 δi 来微调。但是,如果不加限制,系统为了追求极致的平滑,可能会把 δi 设得非常大,导致这个点被挪到了一个完全脱离现实的物理位置。为了防止这种情况,作者引入了 Lreg
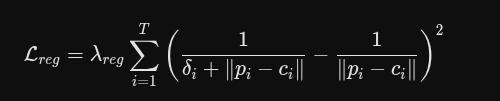
||pi - ci|| 是原始估算的深度(点到相机的距离)。
δi + ||pi - ci|| 是加上偏移量后的新深度。
核心精髓在于“倒数”:作者没有直接比较新老深度的差值,而是比较了深度的倒数(即视差空间,Disparity space)。
为什么要用视差(深度的倒数)来计算?
原因有两个:
尊重原始数据:深度图最开始是通过立体相机的“视差”(左右眼看到的像素位移)算出来的,原始的测量单位本身就是视差。
远近容忍度不同(极其关键):在立体视觉中,物体越远,深度估算越不准(视差差 1 个像素,近处可能只差 10 厘米,在几百米外可能就差了 10 米)。通过在视差空间做限制,系统在数学上自动实现了一个效果:对于近处的点,系统不允许 δi 有太大变化;但对于远处的点,系统会非常宽容,允许 δi 有非常大的调整幅度。
系统到底是怎么判断一个点是“静止”还是“运动”的?它该如何分配静态损失和动态损失的权重?
为什么用 2D 像素来衡量运动幅度,而不是直接用 3D 距离?
远处物体的 3D 噪声会被放大 (noise amplification at low disparities)。
在立体视觉中,远处的物体(比如远处的山或建筑)在左右眼画面中的视差(disparity)非常小。
此时,哪怕只有 1 个像素的估算误差,转换成 3D 深度时,也会变成好几米的剧烈波动。
如果用 3D 距离来算,系统会误以为远处的静止大楼在以极快的速度“狂奔”。因此,退回到 2D 图像平面(算像素移动了多少)反而更稳定、更可靠。
运动幅度 m 是怎么计算的?
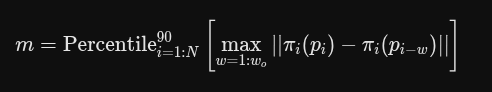
πi(·) 投影:系统假装在这 wo = 16 帧的时间窗口里,相机是完全定在第 i 帧的位置不动的。然后把这 16 帧里的 3D 点都“投影”到当前这一个相机的 2D 画面上。这样就能剔除相机自身移动带来的视觉干扰,纯粹看这个点相对画面移动了多少。
max 取最大值:在这个 16 帧的短窗口里,找出这个点在 2D 画面上偏离最远的那一次距离。
Percentile90 取 90 百分位数:对整个视频的所有帧都做上述计算后,不用最大值,而是取第 90% 大的值作为最终的运动幅度 m。这是一种统计学上的过滤手法,目的是剔除极个别的极端错误噪点。(避免选取的 特定投影帧[1到 N的某一帧] 误差较大)
权重函数

DynaDUSt3R 的网络架构
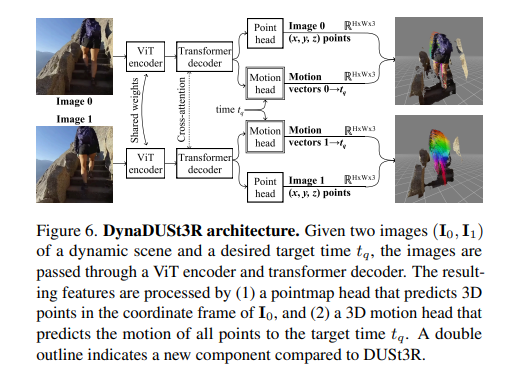
1. 模型的输入 (Inputs)
模型需要接受两部分输入:
图像对: 拍摄于不同时间点的两张同一动态场景的照片,标记为 Image 0 (I0) 和 Image 1 (I1)。
目标时间 (tq): 这是一个时间参数,用来告诉模型:“我想知道在这两张照片拍摄期间的某一个特定时刻 tq,物体处于什么位置。”
2. 特征提取与交互 (Encoders & Decoders)
图像输入后,需要被转化为计算机能理解的数学特征:
ViT Encoder (视觉 Transformer 编码器): Image 0 和 Image 1 分别进入编码器。请注意它们之间有一个标注为 “Shared weights (共享权重)” 的双向箭头,这意味着模型使用完全相同的“大脑逻辑”来提取这两张图像的基础特征。
Transformer Decoder (解码器): 提取的特征随后进入解码器阶段。这里最核心的是中间的 “Cross-attention (交叉注意力机制)” 箭头。这代表模型在处理图 0 的特征时,会参考图 1 的信息,反之亦然。这就像人类依靠双眼视角的差异来感知深度和运动一样,模型通过比对两张图的差异来理解 3D 空间。
3. 双头输出设计 (The Output Heads)
这是该架构最核心的创新点。解码后的特征兵分两路,进入两个不同的“预测头”:
Point head (点图头):
这是继承自上一代静态模型 (DUSt3R) 的基础组件。
它的任务是预测静态的 3D 几何形状。
它输出的数据维度是 RH * W * 3,意思就是为图像上的每一个像素点 (高 H 宽 W),预测出一个三维空间坐标 (x, y, z)。图中明确提到,两张图像算出的 3D 点,都会被统一对齐到 Image 0 的空间坐标系下。
Motion head (运动头):
图例下方特别说明了,双层边框代表这是相比老模型新增的组件,是处理动态场景的关键。
它接收了前面提到的目标时间 tq 作为额外条件。
它的任务是预测运动向量 (Motion vectors)。例如对于 Image 0,它预测的是从时间 0 到目标时间 tq 之间,每一个 3D 点在空间中移动的方向和距离;维度同样是RH * W * 3。
4. 最终的可视化结果 (Right side)
最右侧展示了将两个预测头的结果结合起来后的 3D 效果:
不仅能把 2D 照片里的人物重建成立体的 3D 点云(如右上角的静态人像)。
还能结合 Motion head 预测出的运动向量,画出他身体各个部位在三维空间中随时间移动的彩色轨迹(如右下角的彩色拖影)。
神经网络是如何理解“时间”的
时间编码 (Positional Embedding):神经网络本质上只认识矩阵,它不懂什么是“时间 0.5”。为了让网络理解你想查询的时间 tq,作者参考了 Transformer 经典的“位置编码”技术,把 tq 这个简单的数字,编码成了一个复杂的 128 维特征向量 (128-D vector)。然后,通过线性投影层,把这个代表时间的向量“注入”到图像特征中,这样网络就知道该推演出哪个时间点的画面了。
损失函数
尺度归一化
为了消除这种整体物理尺度的模糊性,作者采用了“尺度不变性(scale-invariant)”的设计。
计算尺度因子: 公式提到的 z = norm(P0, P1) , z̄ = norm(p̄0, p̄1) 。这里的 norm 算的是所有 3D 点到世界坐标系原点的“平均距离”。
z 是 AI 预测出来的点云尺度,而带有上划线的 z̄ 则是真实点云(标准答案)的尺度。
在计算误差之前,系统会先把预测点 P 除以 z,把真实点 p̄ 除以 z̄ 。这就相当于强行把两套 3D 点云缩放到同一个绝对大小,然后再去比较它们的形状对不对,从而避免了因为整体放大或缩小导致的冤枉扣分。
3D 几何点损失
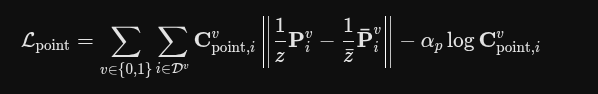
欧氏距离项 || ... ||: 这是最直观的部分,计算在统一尺度下,AI 预测的 3D 坐标位置与真实位置之间的直线距离。距离越大,损失越高。
置信度感知 Cvpoint,i: 这是一个极其聪明的“软心智”设计。AI 会为自己预测的每个点输出一个自信程度(0 到 1 之间)。如果 AI 觉得某个区域(比如纯色墙壁、被遮挡的死角)非常难猜,它会输出一个很低的置信度,这会作为权重乘在距离误差上,从而减轻惩罚。
防止 AI 偷懒的正则项 : 如果只看上一条,AI 为了不被惩罚,干脆对所有点都输出“我毫无自信(置信度为 0)”就行了。为了防止这种作弊,这个 log 惩罚项会逼迫 AI 尽可能提高置信度。只有当它真的遇到了极其困难的像素时,它才会权衡利弊,选择降低置信度。
预测轨迹:3D 运动损失
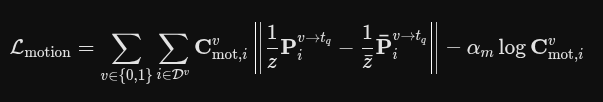
作者并没有直接去比较“预测的运动向量”和“真实的运动向量”,而是让“基础位置(起点)”加上“运动向量(位移)”,算出了目标时间点 tq 的“终点位置”
可改进之处
从“串行堆叠”向“端到端联合优化”演进:目前,相机姿态、深度图和 2D 轨迹是分别用不同的独立算法算出来的,然后再强行融合 。未来可以引入端到端的神经隐式表达(如 4D Gaussian Splatting 或动态 NeRF),让姿态、几何和运动在同一个可微的网络中进行联合优化,从而彻底消除“上游误差传递给下游”的问题。
引入视频级全局一致性 (Video-level Input & Global Optimization):目前模型一次只能处理两张图片推演运动 。未来可以引入时序注意力机制(Temporal Cross-Attention)或者 3D 卷积核,将模型升级为接收“视频流”输入。正如作者展望的,采用额外的全局优化能保证长视频中物体形状和轨迹的全局时空一致性 。
几何与运动特征的更深度耦合:目前的架构在 Decoder 之后强行拆分了两个独立的预测头(Point head 和 Motion head)。作者在消融实验中提到,尝试用一个头直接结合时间 embedding 回归点坐标会导致效果下降,可能是因为 Decoder 容量不够 。未来的架构可以设计一种专门的“时空耦合 Transformer 块”,让模型在提取特征时,就能意识到空间几何与时间运动本质上是不可分割的 4D 流形
POMATO
https://arxiv.org/pdf/2504.05692
framework
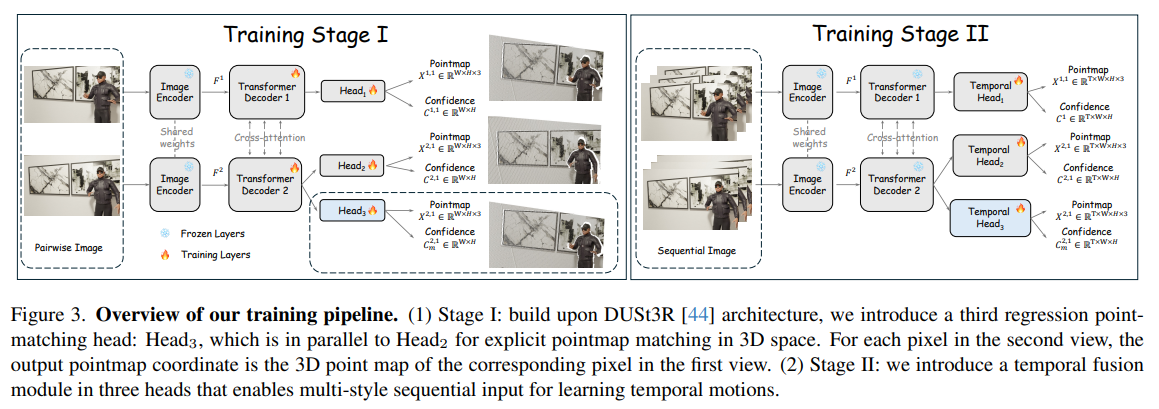
第一阶段:成对图像训练 (Training Stage I)
这一阶段的主要目的是学习基础的几何结构并在 3D 空间中建立显式的点图匹配关系 。
输入形式:采用两张视角的成对图像(Pairwise Image)。
网络状态:图像编码器(Image Encoder)的权重是共享且冻结的(图中的浅蓝色雪花图标),而 Transformer 解码器(Transformer Decoder)和回归头(Head)的参数参与训练(图中的橙色火焰图标)。两个解码器之间会进行交叉注意力(Cross-attention)的信息交互。
head2 : 它预测的是第二张图像中的每个像素,假设整个世界是静止的,经过相机的全局刚体变换(旋转和平移)后,在第一张图像坐标系下应该处于的 3D 位置
核心创新点 (Head3):在原有的 Head1 和 Head2 基础上,模型专门引入了一个平行的第三回归头(动态物体),即点图匹配头(Head3) 。
输出结果:所有的 Head 都会输出点图(Pointmap,形状为 X∈R W * H * 3)和置信度图(Confidence,形状为 C ∈R W * H )。其中,Head3 的特殊之处在于:对于输入第二视图中的每一个像素,它输出的是该像素在第一视图中对应位置的 3D 点图坐标 。
第二阶段:时序序列训练 (Training Stage II)
这一阶段的目的是通过时序融合,让模型能够处理连续的动态视频并学习时序运动(temporal motions)。
输入形式:采用包含多帧图像的连续视频序列(Sequential Image)。
网络状态:在这一阶段,不仅图像编码器保持冻结,Transformer 解码器的参数也被冻结了(图中的解码器上也变成了雪花图标)。
核心创新点 (Temporal Head):在解码器之后,原有的三个基础回归头被替换/升级为时序头(Temporal Head1, Temporal Head2, Temporal Head3) 。这些时序融合模块是这一阶段唯一参与训练的层(带有火焰图标)。
输出结果:由于输入变成了多帧序列,输出张量中增加了一个时间维度 T。例如,点图的输出形状变为了 X∈R T * W * H * 3 ,这使得模型能够应对多风格的序列输入,从而保证长视频中的 3D 追踪和重建具有高度的时序一致性 。
如何通过相机的相对位姿进行全局坐标对齐
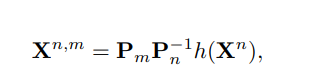
Xn : 相机 n 自己坐标系下的 3D 点云(点图)。
Xn,m : 将相机 n 的 3D 点转换到相机 m 坐标系下的结果 。
Pn : 相机 n 的“世界到相机” (World-to-Camera) 位姿矩阵 。它包含旋转和平移信息。
Pm : 相机 m 的“世界到相机”位姿矩阵
h(Xn) : 齐次坐标映射 (homogeneous mapping) 。它把普通的 3D 坐标 $(x, y, z)$ 扩展为 4D 向量 (x, y, z, 1),以便能够和 4 *4的位姿矩阵进行线性乘法运算
第一步:将点从“相机 n 坐标系”转到“全局世界坐标系”
第二步:将点从“全局世界坐标系”转到“相机 m 坐标系”
第三步:组合公式
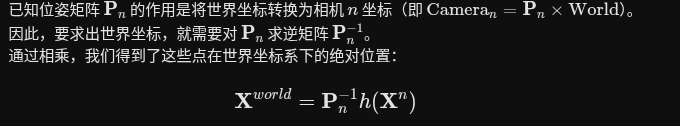
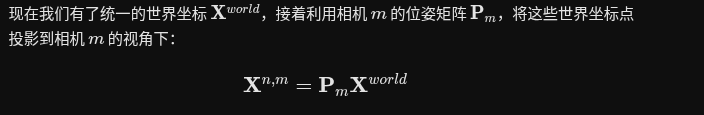
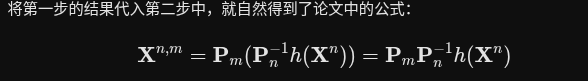
显式点图匹配 (Explicit Pointmap Matching)

在处理动态场景时,仅仅依靠相机的刚体位姿变换(如论文之前的公式 1 所示)无法准确追踪移动的物体,会产生歧义 。为了解决这个问题,作者提出了这个匹配公式
(x1, y1) 和 (x2, y2):分别代表第一张图像(Image 1)和第二张图像(Image 2)上对应像素的 2D 网格坐标 。
X1,1(x1, y1):表示图像 1 中坐标为 (x1, y1) 的像素,在图像 1 自身坐标系下预测的 3D 点坐标(由模型的 Head1 输出)
Xm2,1(x2, y2):表示图像 2 中坐标为 (x2, y2) 的查询像素,经过模型新增的匹配头(Head3 预测后,直接映射到图像 1 坐标系下的 3D 点坐标
通过对比物理匹配位置和刚体投影位置的偏差,来揪出画面中移动的物体。
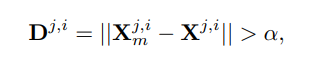
表示图像 j 到图像 i 的动态遮罩(Dynamic Mask)
第二阶段训练中引入的时序运动模块(Temporal Motion Module)
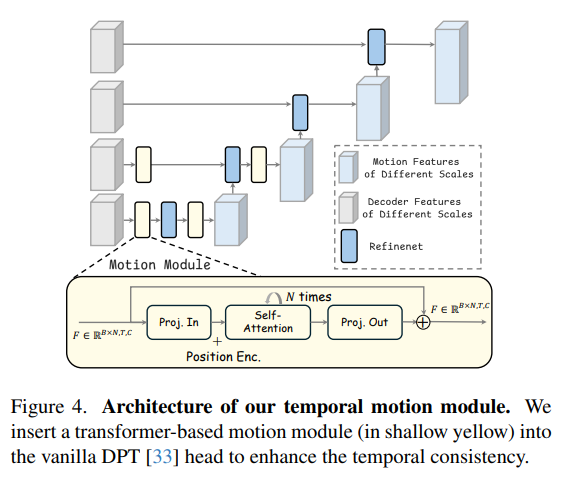
1. 宏观架构:嵌入 DPT 头部 (上半部分)
上半部分展示了该模块是如何被集成到模型的预测头(Head)中的:
基础骨架:整个结构基于经典的 DPT(Dense Prediction Transformer)头部网络 。
特征图层(灰色与蓝色块)
灰色块:代表来自解码器的不同分辨率/尺度的特征(对应DPT)(Decoder Features at Different Scales) 。
深蓝色块(Refinenet):用于特征的上采样和融合网络 。
浅蓝色块:处理后得到的不同尺度的运动特征(Motion Features of Different Scales)
核心插入点(浅黄色块):浅黄色的块就是作者引入的时序运动模块(Motion Module) 。
关键细节:注意看,浅黄色模块并没有加在最上面两层高分辨率的特征上,而是只插入在了网络较深的、低分辨率的特征层。论文中解释,这样做的目的是为了大幅度降低计算成本,同时依然能捕捉到全局的运动规律 。
2. 微观架构:时序注意力机制 (下半部分)
下半部分的黄色大框是对上述“浅黄色块”内部结构的放大,揭示了它是如何处理时间信息的:
输入张量:输入的特征表示为 F∈R B * N,T,C。结合论文正文,这里的维度分别是:B(Batch size,批次大小)、N(Token number,空间 Token 数量)、T(Window length,时间窗口/视频帧数)和 C(Token dimension,通道维度) 。
运算逻辑:
为了让模型专门学习“时间”上的运动规律,网络会将空间的 Token 数量 (N) 合并到 Batch 维度中,从而专门沿着时间维度 (T) 进行计算 。
特征首先经过输入线性投影层 (
Proj. In) ,并加上位置编码 (Position Enc.) ,这是为了告诉模型当前处理的是视频中的哪一帧(时间顺序)。接着,特征会穿过 N 层标准的多头自注意力机制(Self-Attention)和前馈网络 。在这一步,不同帧之间的特征会互相交换信息。
最后,通过输出投影 (
Proj. Out) 并叠加一个残差连接(图中的 $\oplus$),得到输出
三大下游任务流程图

1. 3D 点追踪 (Point Tracking)
输入构造:
上方分支(网络 1):输入连续的视频帧序列(t1, t2, t3 ... )。
下方分支(网络 2):将第一帧作为关键帧 tk,并复制多份与上方对齐输入(tk, tk, tk...)。
使用预测头:输出端使用的是 时序匹配头 (Temporal Head3)。
原理解释:正如我们之前讨论的,Head3 负责寻找“物理对应点”。模型会把后续视频帧(t1, t2 ...)中的像素,强制去匹配到第一帧(tk)的 3D 坐标系中。这样就能清晰地描绘出画面中某个点(比如车上的某点)在 3D 空间中的运动轨迹(图右侧的彩色轨迹线)。
2. 视频深度估计 (Video Depth)
输入构造:
上方分支:视频序列(t1, t2, t3, t4...)。
下方分支:完全一样的视频序列(t1, t2, t3, t4...)。
使用预测头:输出端主要依赖 时序基础头 (Temporal Head1)。
原理解释:深度估计不需要跨视角的复杂坐标转换,只需要每张图自身的 3D 深度信息。因此输入两组完全相同的序列,利用 Head1 输出每帧在其自身坐标系下的点图。得益于网络内部的“时序运动模块”,输出的深度图序列在时间上会非常连贯、平滑,不会出现单张图片预测时常见的“闪烁”现象。
3. 多视图 3D 重建 (Multi-view Reconstruction)
输入构造:
上方分支:将序列的最后一帧作为关键帧 tk,重复输入(tk, tk, tk, tk...)。
下方分支:视频序列(t1, t2, t3, t4 ...)。
使用预测头:输出端使用的是 时序刚体头 (Temporal Head2)。
原理解释:Head2 的作用是通过刚体变换进行坐标系对齐。这里的逻辑是把所有视频帧(t1, t2 ...)的 3D 结构,统一强行“搬运/投影”到关键帧 tk 的世界坐标系之下。这样,一段视频里不同视角拍到的片段,就被自动拼合成了一个完整且全局对齐的 3D 场景点云(图右侧的道场重建结果)。
时序一致性损失

仔细分析 此论文 有什么 不足之处 或者架构 可以改进的 点
消融实验表明,在室内数据集(如 TUM, Bonn)这类运动受限、视角变化极小的场景中,新增的匹配头(Head3)带来的性能提升非常微薄 。这说明该架构对于高度动态的场景收益最大,但在准静态场景下,可能付出了不必要的计算开销
TriSplat: Simulation-Ready Feed-Forward 3D Scene Reconstruction
https://arxiv.org/pdf/2605.26115
framework
Shape of Motion
https://arxiv.org/pdf/2407.13764
解决什么问题
研究目标:如何仅通过一段由单台相机随意拍摄的视频(单目视频),重建出复杂动态场景的持久3D几何结构,并追踪场景中每个点在整个视频期间的3D运动轨迹 。
传统痛点:单目动态重建一直是一个极具挑战性的病态(ill-posed)问题 。过去的方法大多需要同步的多视角视频、雷达/深度传感器,或者受限于准静态场景 。近期的单目方法通常只能模拟连续帧之间的短距离场景流(scene flow),无法捕捉贯穿整个视频的持久3D运动轨迹 。
framework
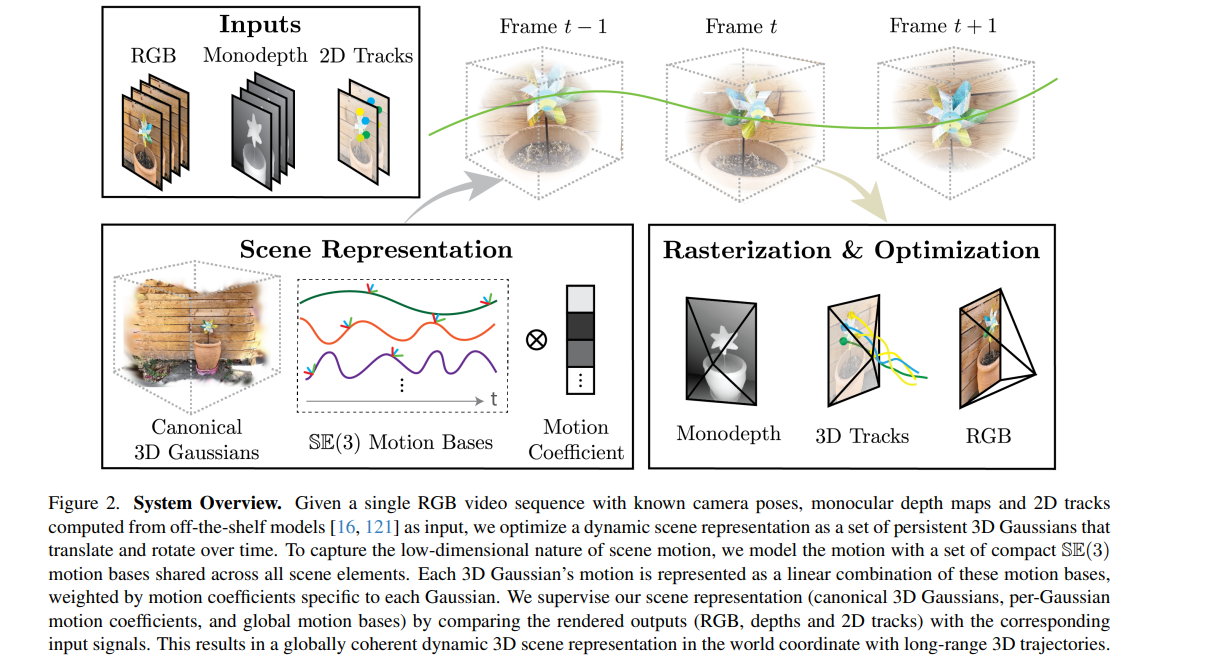
1. Inputs (输入阶段)
为了解决单摄像机视角的局限性,系统利用了现成模型提取的三种互补信息作为输入 :
RGB (视频帧):带有已知摄像机位姿的原始单目视频序列 。
Monodepth (单目深度图):由深度估计模型(如 Depth Anything)生成的每帧相对深度信息 。
2D Tracks (2D点追踪轨迹):由点追踪模型(如 TAPIR)提取的跨帧2D像素运动轨迹 。
2. Scene Representation (场景表示阶段)
这是该方法最核心的创新点,展示了系统在底层如何通过数学模型来表达这个动态的三维世界:
Canonical 3D Gaussians (规范3D高斯):系统首先在参考坐标系中建立一组持久的3D高斯集合,用来表示场景的初始几何结构和外观 。这些高斯点会随着时间平移和旋转 。
SE(3) Motion Bases (SE(3)运动基) * Motion Coefficient (运动系数):为了捕捉真实世界场景运动的低维物理特性(比如物体的整体刚性移动),系统并没有让每一个高斯点独立、自由地移动,而是学习了一组全局共享的紧凑 SE(3) 运动基 。
融合 (图中的 符号):场景中任意一个3D高斯点的运动,都是通过这组全局运动基,乘以该点专属的“运动系数”进行线性组合而成的 。
3. Rasterization & Optimization (光栅化与优化阶段)
系统通过这一步进行自我纠错和学习:
渲染输出:通过可微渲染(光栅化)技术,系统将上述构建的“动态3D高斯”模型重新投影到特定的摄像机视角,生成预测的 单目深度 (Monodepth)、3D轨迹 (3D Tracks) 以及 RGB图像 。
对比监督:系统将这些渲染出来的预测结果,与第一步提供的原始输入信号(RGB图、深度图、2D轨迹)进行比对 。通过计算它们之间的误差,系统不断反向传播,优化3D高斯的初始状态、全局运动基以及各个点的运动系数 。
总结(顶部效果展示)
在图的最上方(Frame t-1 到 Frame t+1),展示了该系统最终达成的工作效果:风车在连续帧中随时间旋转,一条贯穿前后的绿色曲线精确地描绘了它的移动。这种闭环优化过程,最终成功生成了在世界坐标系下具有极长程3D轨迹的连贯动态3D场景表示 。
3D Gaussian Splatting
为了高效地优化和渲染,动态场景的几何形状和外观被表示为一组分布在全局的3D高斯点。在初始的“规范帧”(即初始参考时间点 t0)中,每一个3D高斯点的参数集被定义为向量 g0:
投影后的 2D 高斯由中心点 μ0'∈ R2 和二维协方差矩阵 Σ0'∈ R2*2 来参数化表示
当所有的 3D 高斯都被投影成 2D 形状后,系统需要计算屏幕上每一个像素点 p 的最终颜色(RGB 图像)和深度图 。这个过程被称为 Alpha 混合(Alpha Compositing)

其中,H(p) 代表所有与从像素 p 射出的光线相交的高斯点的集合 。简单来说,就是把挡在这个像素视线上的所有高斯体按前后顺序排好,把它们叠加起来求和
正如图片最后一句所强调的:"This process is fully differentiable"(这个过程是完全可微的)


SE(3) 刚性变换与公式
SE(3) 的含义:公式中提到了 SE(3),这在数学上被称为“特殊欧几里得群”(Special Euclidean group)。虽然名字很学术,但它的物理意义非常直观:它代表了三维空间中的刚体运动,即仅仅包含旋转(Rotation)和平移(Translation),没有任何形变或缩放
变换矩阵

如何让成百上千万个 3D 高斯点在运动时既不会计算爆炸,又不会像散沙一样毫无规律?
全局运动基

权重归一化 (||w(b)|| = 1): 为了防止组合出来的运动出现离谱的拉伸或飞出天际,算法强制要求每个点身上的权重总和(或范数)必须等于 1。
6D 旋转参数化: 在数学上,直接把几个旋转矩阵(3x3矩阵)按权重加起来,得到的结果往往不再是一个合法的旋转矩阵。为了解决这个平滑过渡和混合的问题,作者使用了 6D 旋转表示法(6D rotation)和标准的平移向量来进行加权组合,这在深度学习中能提供更稳定的梯度。
显式的低维正则化(Explicit Regularization) 因为所有的 3D 高斯点只能通过这区区几个(比如 B=10 个)基础动作来组合自己的轨迹,算法被迫去寻找那些一起运动的群体。运动轨迹相似的高斯点,自然会学习到相似的运动系数(w(b))。这在无形中实现了对场景运动部件的“软聚类”或“分割”。
如何把 3D 运动轨迹“渲染”成我们可以直接利用的 2D 特征图
核心目标:追踪像素的 3D 未来位置
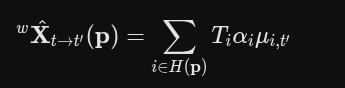
H(p)(视线相交集合):在当前的查询时间 t,从相机的位置向屏幕像素 p 射出一条光线,找出这条光线穿过的所有 3D 高斯点。
Tiαi(混合权重):这和渲染颜色时一模一样。αi 是当前高斯点的不透明度,Ti 是透射率(表示它前面有没有被其他高斯挡住)。这个乘积决定了该高斯点对这个像素到底有多大的“代表性”或“权重”。注意,这个权重是基于时间 t 的状态计算的。
μi, t'(目标时间的 3D 中心):这是公式里最精妙的地方。 在进行加权求和时,算法提取的不是这个高斯点在时间 t 的位置,而是它在目标时间 t' 的三维中心坐标。
视角转换:从“世界”到“相机”
提取预测深度
投影出未来的 2D 像素位置



问题一:我们是怎么知道 t 的高斯点在 t' 时刻的位置的?
从一开始,轨迹方程就写好了: 就像我们在之前公式 (3) 和 (4) 中看到的,每一个 3D 高斯 i 都有一个在初始时刻的绝对坐标 μi,0,以及一组专属的运动系数 wi(b)。
位置是“算”出来的,不是“找”出来的: 当系统想知道这个高斯点在 t' 时刻跑到哪里去了时,它不需要去图像里找。它只需要把时间 t' 代入该高斯点的运动方程(即全局运动基的线性组合),直接用公式计算(解析求值)出它在 t' 时刻的 3D 坐标 μi, t' 。
问题二:这个加权坐标求出的值好像没什么意义?
公式中的加权权重是 Tiαi。在体渲染(Volume Rendering)中,由于遮挡关系(透射率 Ti),这个权重分布是极其不均匀的。
大多数真实的 3D 高斯点在训练后会变得非常不透明(αi ≈ 1)。
当视线穿过空间时,碰到第一个不透明的高斯点,它的 Tiαi 就接近 1.0
直接提取最前面的点”这个操作是不可微的(Non-differentiable) 而加权求和(Soft Argmax / 期望值)是完全平滑且可微的
初始化
1. 确立“大本营”与初始位置 (Canonical Frame & Gaussian Means)
寻找规范帧 t0:系统首先会在整个视频中寻找 3D 追踪点(3D tracks)可见数量最多的一帧。这一帧被定义为规范帧 t0,相当于整个场景的“大本营”。
初始化位置 μ0:接着,算法从这帧的初始观测数据中,随机抽取 N 个 3D 轨迹点的位置,作为 N 个 3D 高斯点的初始 3D 中心位置(μ0)。
2. 寻找场景的“运动骨骼” (K-means Clustering for Motion Bases)
速度聚类:我们前面提到过,场景中几百万个点共享 B 个基础运动(Motion bases)。那么这 B 个基础运动最初是怎么找出来的呢?算法提取了所有带有噪声的 3D 轨迹的速度向量,并对它们运行 K-Means 聚类算法。
物理意义:速度相似的点,通常属于同一个刚体(比如一辆车上的所有点都会一起移动)。通过聚类,系统初步把场景“切割”成了 B 个一起运动的群组。
3. 计算基础运动轨迹 (Weighted Procrustes Alignment)
普氏对齐:对于每一个找出来的群组 b,算法需要计算它从时间 0 到时间 τ 具体的旋转和平移矩阵 。这里用到了一种经典的几何算法叫做普氏对齐(Procrustes alignment)。它的作用是:给定两组点云(时间 0 的点云 和时间 τ 的点云,算出它们之间最优的刚体变换。
引入置信度:为了防止 TAPIR(2D 追踪模型)预测出的错误噪点干扰计算,算法在做对齐时加入了“权重”。TAPIR 预测越确定的点,在这个计算中的话语权就越大。
4. 空间距离决定运动权重 (Exponential Decay of Motion Coefficients)
公式意义:既然有了 B 个运动基底,那么每一个具体的 3D 高斯点,该怎么分配自己的运动权重 呢?
指数衰减原则:作者使用了一个非常符合物理直觉的规则——距离越近,跟随你运动的概率越大。在规范帧中,一个高斯点距离群组 b 的中心越远,它受该群组运动基底控制的权重 就会呈指数级衰减 (decay exponentially)。
5. 预热优化 (Initial Optimization)
在完成上述硬编码的初始化后,所有的参数(位置 μ0、权重 、运动基 )还不完美。
因此,在进入最终的主力训练之前,系统会先跑一轮“预热优化”。它使用 L1 损失函数(一种对异常值不那么敏感的误差计算方式)让这些参数去贴合观测到的 3D 轨迹,同时加入时间平滑性约束(temporal smoothness constraints),防止运动轨迹出现瞬间的“瞬移”或“抽搐”。
动态部分(Dynamic Gaussians):完全靠运动基驱动 , 静态部分(Static Gaussians):彻底放弃运动基 , 是 如何区分 动态和静态的
Training
单帧重建损失(Reconstruction Loss)
“我们怎么知道目前学习到的 3D 高斯是对的?” 答案是:把当前的 3D 高斯渲染成 2D 画面,然后和真正的输入视频进行‘找茬’对比。
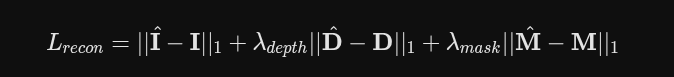
算法在当前视角渲染出的 RGB 彩色图像 I,必须和该时刻真实的视频帧画面 I 长得一模一样 。
算法渲染出的深度图 D,必须和用 Depth Anything 模型提取出的参考深度图 D 吻合
算法渲染出的物体轮廓遮罩 M,必须和预先提取的运动物体遮罩 M 重合
遮罩 就是 静态高斯和动态高斯投影
轨迹追踪损失

物理刚性损失
虽然公式 8 和 9 已经在教高斯点怎么运动了,但 TAPIR 给出的 2D 轨迹总是带有噪声的。如果完全信任这些噪声数据,3D 高斯点在运动时就会像一盘散沙一样各自乱飞,导致物体发生奇怪的形变(比如一个人的手臂在挥动时像面条一样被拉长)。
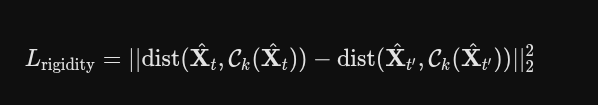

可能有的不足点
极度依赖外部“先验模型”(误差级联风险) 局限表现:系统强依赖现成的深度估计(Depth Anything)、2D 点追踪(TAPIR)以及相机位姿估计(MegaSaM 或 COLMAP)。论文作者坦言,如果在缺乏纹理的区域,或者遇到极其剧烈的运动,这些底层模型预测失败,那么随后的整个 4D 重建也会跟着“翻车”或降级
“测试时优化”导致极高的时间与算力成本 局限表现:与大多数 NeRF 或 3D 高斯方法一样,它需要针对每一个新视频进行漫长的“测试时优化”(Test-time Optimization)。论文提到,一段 300 帧、分辨率仅为 960*720 的视频,在顶级的 A100 GPU 上需要跑约 2 个小时才能完成训练
WAFT
https://arxiv.org/pdf/2506.21526v1
framework
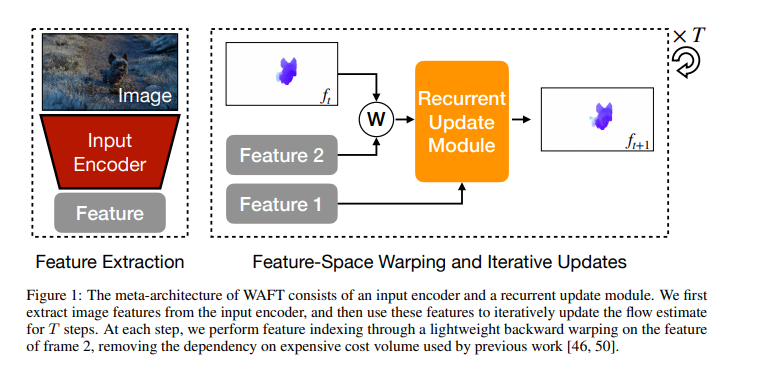
第一阶段:特征提取 (Feature Extraction)
这是图左侧虚线框内的部分,负责图像的基础处理。
输入编码器 (Input Encoder):模型首先接收原始图像(Image)作为输入。在这个阶段,两帧连续的图像(帧1和帧2)会分别通过这个红色的编码器网络。
特征 (Feature):编码器处理后,会为每一帧图像提取出底层的“特征图”(图中灰色的 Feature 框)。在后续步骤中,它们分别被称为 Feature 1 和 Feature 2。
第二阶段:特征空间变形与迭代更新 (Feature-Space Warping and Iterative Updates)
这是图右侧虚线框内的部分,也是 WAFT 预测光流的核心循环过程。右上角的 *T 表示这个过程会循环迭代 T 次。
当前光流估计 (ft):在第 t 步时,模型已经有了一个初步的光流预测结果(图中最上方的蓝色小狗形状)。
变形操作 (W - Warping):这是 WAFT 的精髓所在。图中的圆圈 W 代表“向后变形”(backward warping)。它利用当前的光流估计 ft,去第二帧的特征图(Feature 2)中“抓取”对应的特征信息。
循环更新模块 (Recurrent Update Module):这个橙色的模块接收两个关键输入:第一帧的原始特征(Feature 1)以及刚刚通过 W 操作变形后的第二帧特征。该模块(在论文中是基于 Transformer 的 DPT 架构)对这些信息进行处理后,输出一个更加精确的新的光流估计值 ft+1。
循环 (Loop):产生的 ft+1 会作为下一次迭代的输入,再次进行变形和更新,如此往复 T 次,不断打磨和修正光流边界。
ZipMap: Linear-Time Stateful 3D Reconstruction via Test-Time Training
https://arxiv.org/pdf/2603.04385
framework
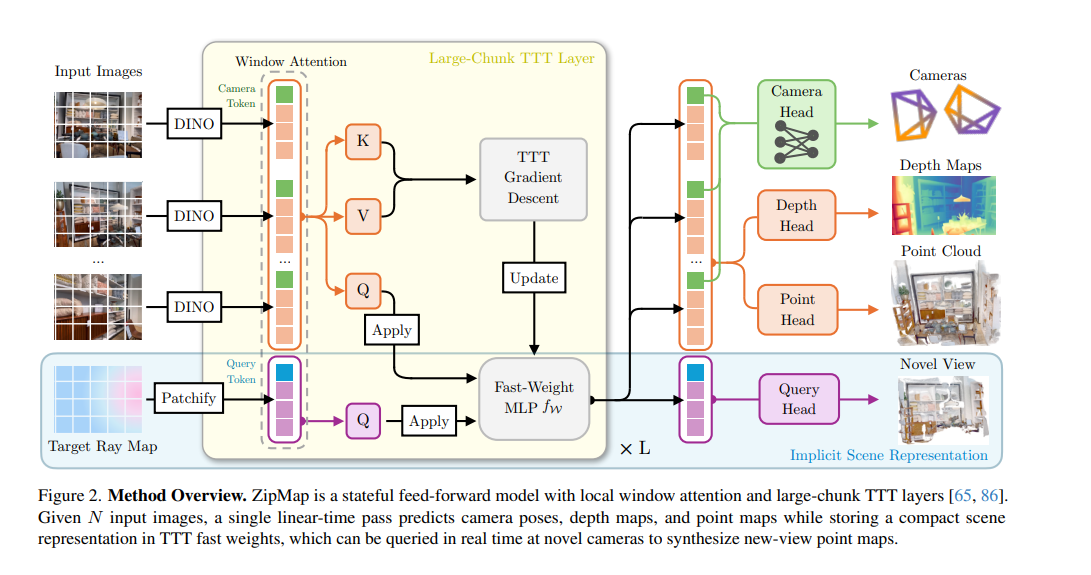
1. 输入与分词 (Tokenization)
模型可以处理两条平行的输入流:
输入图像 (Input Images,上方): 将多张输入图像通过一个预训练的视觉特征提取器(如图中标记的 DINO,具体为 DINOv2)进行处理。提取出的特征被展平为一系列的图像特征 Token。其中,每张图像都会分配一个特殊的相机 Token (Camera Token)(图中最上方绿色的方块),用于后续预测相机参数。
目标光线图 (Target Ray Map,下方浅蓝区域): 这是为了查询新视角而准备的。根据目标相机的参数生成光线图,然后通过 Patchify(分块)操作,转换为一系列的查询 Token (Query Token)。
2. 核心骨干网络:交替注意力与 TTT 层
这是 ZipMap 实现“线性时间”处理长序列的核心部分。该模块会重复 L 次(如图中右下角的 所示)。它包含两个主要操作:
局部窗口注意力 (Window Attention):
仅仅在单张图像内部(或单个目标视图内部)进行标准的自注意力计算。这一步的目的是捕捉单张图片内部的局部空间结构和特征。
大块 TTT 层 (Large-Chunk TTT Layer,黄色高亮区域):
这是替代传统全局注意力(导致二次方复杂度的元凶)的创新设计。
生成 K、V: 将所有输入图像的 Token 投影为键 (K) 和值 (V)。
梯度下降更新 (TTT Gradient Descent -> Update): 利用这些 K 和 V,通过一步梯度下降,在线更新一个多层感知机(即图中的 Fast-Weight MLP fW)的“快速权重”。这一步非常关键:它将所有输入图像的全局 3D 场景信息压缩并存储到了这个 MLP 的权重中。
应用查询 (Q -> Apply): 将输入图像 Token 投影为查询 (Q),并输入到刚刚更新好权重的 fW 中,从而让每个图像的 Token 都获得了全局的上下文信息。
3. 任务预测头 (Prediction Heads)
经过 L 层处理后,带有全局信息的 Token 会被送入不同的预测头(右侧橙/绿区域),输出具体的 3D 重建结果:
相机头 (Camera Head): 专门接收那几个绿色的“相机 Token”,输出每张输入图像的相机位姿 (Camera Poses)。
深度头 (Depth Head): 接收图像 Token,预测密集的深度图 (Depth Maps)。
点云头 (Point Head): 接收图像 Token,预测出局部的 3D 点云 (Point Cloud)。
4. 隐式场景表示与新视角查询 (下方浅蓝色区域)
ZipMap 的一大优势在于,那个经过更新的 Fast-Weight MLP fW 实际上已经成为了整个场景的隐式表示 (Implicit Scene Representation)。
如果想看一个全新的视角(图中右下角的 Novel View),只需将新视角的查询 ($Q$) 直接输入(Apply)到这个 MLP 中。
输出的特征送入查询头 (Query Head),即可在恒定时间内(实时)直接渲染出该新视角下的 3D 结构(通常是带颜色的点图或深度图),而不需要重新进行复杂的全局计算。
目标光线图的处理
当你希望 ZipMap 生成一个全新的视角(Novel View)时,模型需要知道目标相机在 3D 空间中的具体位置和朝向。论文中提到,光线图的形状是 T ∈ RH*W*9 , 对于这其中的每一个像素,它都包含了 9 个维度的数值
ro ∈ R3 (光线起点 Ray Origin): 包含 3 个数值 (x, y, z),代表目标相机在 3D 空间中的具体物理位置
rd ∈ R3 (光线方向 Ray Direction): 包含 3 个数值 (x, y, z),代表从相机起点出发,穿过该特定像素点的视线方向
ro * rd (叉积 Cross Product): 包含 3 个数值。这是起点和方向向量的数学叉积 。在 3D 几何(特别是普吕克坐标系 Plücker coordinates)中,引入这个叉积可以帮助神经网络更好地感知这条直线在 3D 空间中的全局几何性质,而不仅仅是局部的位置和方向
然后,像处理普通图像一样,把这个光线图切成小块(Patchify),展平,并转换成 查询 Token (Query Token) 。这些包含几何位置信息的 Query Token 会被送入那个已经记忆了全局场景的 MLP(多层感知机)中去“查询”
快速权重网络结构:SwiGLU-MLP
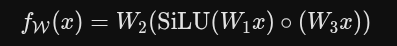
快速权重(Fast Weights):这里的W = {W1, W2, W3} 是模型中的权重矩阵。之所以叫它们“快速”权重,是因为它们在推理/测试阶段也会被在线实时更新,以适应当前看到的这批新图片,而不是像普通权重那样在训练结束后就彻底冻结。
网络结构:这是一个采用 SwiGLU 架构的多层感知机(MLP)。它结合了线性变换、SiLU 激活函数以及逐元素相乘, 用来增强网络的表达能力。
虚拟记忆目标
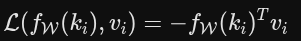
在处理输入的图像 Token 时,模型会将它们分别投影到查询、键和值空间。接下来是替代传统全局注意力的关键步骤
模型会对上面提到的快速权重 W 进行单步梯度下降更新,优化的损失函数就是公式 (2)
通俗解释:这个公式计算的是网络对输入键 ki 的输出结果 fW(ki) 与对应的值 vi 之间的点积(内积),然后取负号。最小化这个负数,就等于最大化两者的方向对齐度和相似度
目的是构建一个上下文联想记忆
计算快速权重梯度

所有图像的token
牛顿-舒尔茨正交化


提取全局信息:替代自注意力
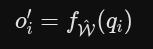
模型把每一个输入图像 Token 的“查询向量”(qi)输入到这个刚刚更新过权重的多层感知机(MLP)中,得到初步的输出特征
恒定时间的查询: 那些代表目标新视角的查询向量,也可以直接输入到同一个更新后的 MLP 中进行查询。
门控过滤输出
查出来的初步结果 oi' 不能直接用,还需要经过最后一道加工

当新视角的预测结果不好,产生了查询损失(Query loss,如颜色和深度误差),产生的梯度传回来,会不会破坏 TTT 的快权重?
这里需要理清深度学习中的双层优化(Inner-Loop 与 Outer-Loop):
内层循环(推理时的 TTT 更新):在跑每一批数据时,模型先用输入图像的 K, V 算虚拟损失,单步更新出 fW 。
外层循环(Meta-Training 真正的模型参数训练):得到最终重建和新视角预测后,计算总损失(公式 9),并通过反向传播更新整个网络的基本参数(Base Weights) 。这些参数包括 DINOv2 后的特征投影层、目标光线图的线性映射层,以及 TTT 层尚未更新前的初始权重 。
外层训练的梯度不会直接去破坏内层刚刚更新好的那个快权重,相反,外层梯度是在强迫两者的特征空间进行几何对齐(Alignment)
Any4D: Unified Feed-Forward Metric 4D Reconstruction
https://arxiv.org/pdf/2602.23361
Any4D 模型的数学公式
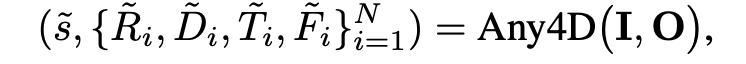
1. 模型的输入 : RGB 图像 , 表示一段包含 N 帧画面的连续视频或图像集 ; 多模态传感器辅助输入 (可选) : 果设备具备其他传感器,模型可以直接利用这些信息,例如深度图(Depth maps)、相机内参(Camera intrinsics)、来自外部系统或 IMU 的相机位姿(Camera poses),以及雷达测量的多普勒速度(Doppler velocity)
2. 输出物理量解析 :
A. 全局物理量 , s 全局度量尺度因子(Metric scaling factor)。它是一个实数,用于将归一化的预测结果还原到真实的物理世界尺度(例如真实的米或厘米)
B 自我中心物理量 (Egocentric quantities): 这些是在局部相机自身坐标系下预测的数值.
R 光线方向 (Ray directions)。代表当前视角下每个像素在 3D 空间中的射线指向(3 个通道代表 x, y, z 方向)
D 尺度归一化深度 (Scale-normalized depth)。代表沿着上述光线方向,每个像素距离相机的深度值
C. 外在中心物理量 (Allocentric quantities)
这些是在统一的全局世界坐标系下预测的数值,用于确保多帧之间的一致性 . F 前向场景流 (Forward scene flow)。描述了从第一帧视角到其他所有帧视角的三维像素运动轨迹,同样经过了尺度归一化处理。 T 相机位姿 (Camera pose)。表示在第一帧所在的坐标系下,当前这一帧的相机位置与朝向。它由两部分组成:尺度归一化的平移向量 pi(3维)和表示旋转的四元数 qi(4维),总计 7 个维度
还原出具有真实物理尺度的 3D 几何结构和动态运动轨迹
恢复绝对尺度下的 3D 几何(静态结构)
恢复绝对尺度下的场景流(动态运动)
预测运动后的新位置(未来的 3D 状态)
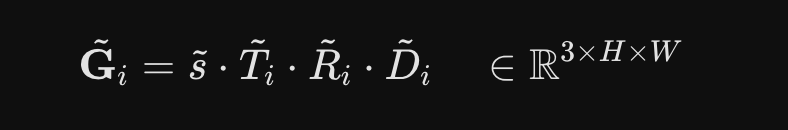


DGGT
https://arxiv.org/pdf/2512.03004
framework
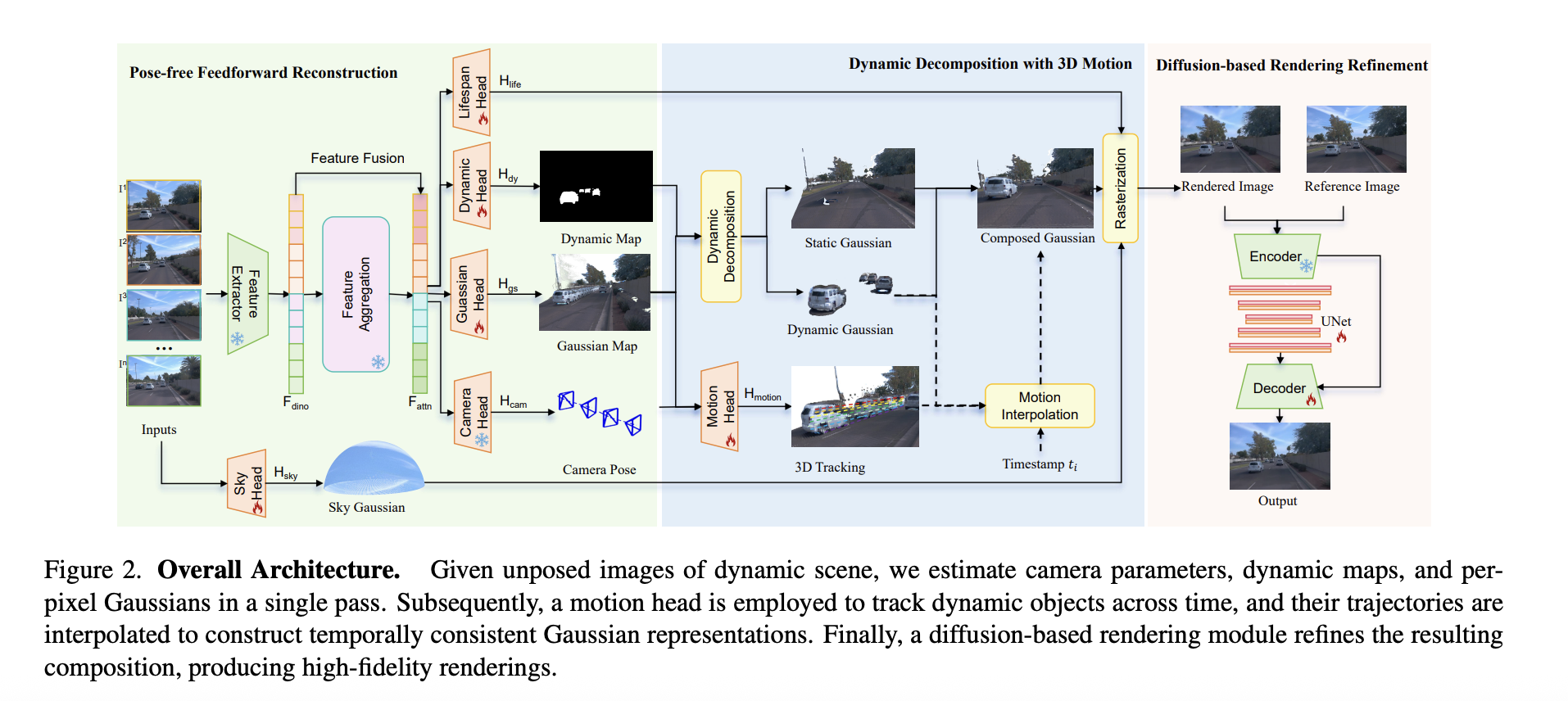
1. 无姿态前馈重建 (浅绿色区域:Pose-free Feedforward Reconstruction)
这是模型的输入和基础特征提取阶段,它的最大突破在于彻底摆脱了对已知相机姿态的依赖。
输入 (Inputs): 输入的是一段未标定相机姿态的连续图像序列。
特征提取与融合 (Feature Extractor & Aggregation): 图像首先经过特征提取器(利用了预训练的 DINO 特征),随后进行特征聚合与融合,得到包含丰富空间和语义信息的全局特征。
多头预测机制 (Multi-Heads): 这是该阶段的核心。融合后的特征被分发到多个并行的“预测头”中,一次性输出构建 3D 场景所需的所有参数:
Lifespan Head (生命周期头): 预测高斯点的存活时间,帮助维持场景在时间轴上的连贯性。
Dynamic Head (动态头): 预测动态掩模 (Dynamic Map),用于区分图像中哪些是运动的物体(如行驶的汽车),哪些是静止的背景。
Gaussian Head (高斯头): 生成基础的 3D 高斯特征图 (Gaussian Map)。
Camera Head (相机头): 直接预测出相机的空间位姿 (Camera Pose)——直接将相机参数作为输出,实现了“无姿态”输入。
Sky Head (天空头): 独立的一条支路,专门用于处理并生成无限远的天空背景 (Sky Gaussian)。
2. 基于 3D 运动的动态解耦 (浅蓝色区域:Dynamic Decomposition with 3D Motion)
这个阶段负责将场景里的“动”与“静”剥离开来,并计算物体的运动轨迹,以便在任意时间点生成画面。
动态解耦 (Dynamic Decomposition): 结合前面生成的 3D 高斯图和动态掩模,模型将整个场景干净利落地拆分为两部分:静态高斯 (Static Gaussian)(例如马路、建筑物、树木)和 动态高斯 (Dynamic Gaussian)(例如移动的车辆和行人)。
3D 追踪与运动插值 (3D Tracking & Motion Interpolation): 独立的运动头 (Motion Head) 会估算动态物体的 3D 运动轨迹。如果需要生成两个输入帧之间某一时间点 (ti) 的画面,模型会基于预测出的轨迹对动态物体进行插值计算,精准推测出它们在该时刻的位置。
光栅化渲染 (Rasterization): 将静态背景、插值后的动态物体以及天空背景重新组合 (Composed Gaussian),并通过可微分的光栅化器,渲染出该视角的初步图像 (Rendered Image)。
3. 基于扩散模型的渲染细化 (浅橙色区域:Diffusion-based Rendering Refinement)
这是最后的“精修”阶段。因为仅靠 3D 高斯的前推和运动插值,画面中往往会出现重影、遮挡空洞或边缘模糊等伪影。
扩散模型重绘: 模型将刚刚渲染出的初步图像 (Rendered Image),与序列中随机抽取的一张真实参考图像 (Reference Image) 组合,一起送入一个单步扩散模型中。
高保真输出: 这个扩散模块包含一个冻结的编码器 (Encoder)、一个用于降噪的 UNet 核心,以及一个微调过的解码器 (Decoder)。它能像“高级修复画笔”一样,智能填补画面的瑕疵,最终输出极其逼真、细节丰富的高质量图像 (Output)。
特征融合
模型在处理图像时,提取出的特征被称为 Fattn(经过注意力机制聚合后的特征) ; 外观重建的缺陷: 作者发现,Fattn虽然包含了很好的“高层语义信息”(比如它知道画面里有一辆车、一条马路),但由于经过了多层网络处理,它丢失了大量的“空间细节”(比如车漆的具体光泽、马路表面的粗糙纹理)。如果只用它来生成 3D 高斯图,渲染出来的画面会缺乏细节、不够真实
为了弥补空间细节的丢失,作者采用了一个经典的做法:将原始的 DINO 特征 Fdino 与高层的注意力特征 Fattn 进行融合(Fuse)。
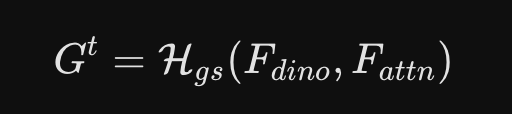
运动头是如何工作的?

第一步:构建时空特征云 (Spatio-temporal feature cloud)
模型不会只看 2D 图像,也不会只看 3D 结构。它首先提取 2D 图像的多尺度特征,然后将这些特征与从高斯图中提取出的 3D 点关联起来,拼凑成一个既有空间深度、又有时间变化、还有颜色细节的庞大特征数据云。
第二步:锁定追踪目标 (寻找 Query)
去哪里找运动的物体呢?对于任意一个时间点 ta,模型会去查看之前生成的动态图 (Mtad)。它会把动态图里值为 1 的像素(即被判定为“正在运动”的像素)挑出来,作为我们的查询像素 Q。接着,利用相机的反投影原理,把这些 2D 像素映射回 3D 空间,确定它们在三维世界里的初始位置。
第三步:利用注意力机制优化轨迹 (Trajectory Refinement)
找到了运动目标在 3D 空间中的起始点后,模型利用 Transformer 特有的“邻域到邻域注意力机制(neighborhood-to-neighborhood attention)”,通过比对前后帧的信息,不断地纠正和优化这些点,从而算出它们极其精确的运动轨迹。
基于扩散模型的渲染细化
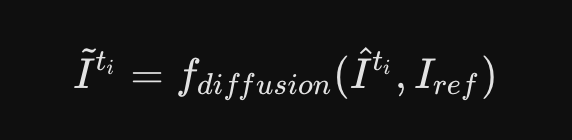
输入准备: 模型接收两张图。一张是刚刚用 3D 高斯粗略渲染出来的、带有瑕疵的当前帧图像 Iti;另一张是从原视频序列中随机抽取的一张真实参考图 Iref。引入参考图是为了给模型提供真实的纹理和光影线索。
特征编码 (VAE Encoder): 将这两张图拼在一起,送入一个冻结的(Frozen,不参与训练) VAE 编码器中,将它们压缩成低维的“隐空间(Latent space)”特征。这能大幅降低计算量。
核心去噪 (UNet Denoiser): 隐空间特征进入 UNet 去噪器,这里的任务是把特征中的“瑕疵和噪声”抹去,还原出干净的结构。
解码还原 (LoRA Decoder): 最后,通过一个使用了 LoRA 技术微调过的解码器,将干净的特征重新还原成一张高清、无瑕疵的最终图像 Iti。
MotionCrafter
https://arxiv.org/pdf/2602.08961
什么叫传统观点认为 应该 align the value range of 4D data to that of the original VAE in the diffusion model
1. 什么是“原始 VAE 的数值范围”?
MotionCrafter 是站在“巨人”肩膀上做研究的,它直接使用了已经训练好的视频生成大模型(比如 Stable Video Diffusion, SVD) 。这些大模型内部包含一个 VAE 模块。 这个“原始 VAE”最初是被设计用来处理普通彩色图像(RGB 图片)的。普通图像的像素值通常是 0 到 255,在送入 AI 模型时,标准的做法是把它们压缩(归一化)到一个严格的固定区间,通常是 [-1, 1] 。
2. 什么是“4D 数据的数值范围”?
在这篇论文中,4D 数据指的是世界坐标系下的 3D 点云坐标(几何)和场景流(运动) 。 与普通图片不同,现实世界中的 3D 坐标是没有绝对边界的,数值可以从 (-∞, +∞) 任意延伸 。比如,一个广阔的室外场景,它的深度和空间跨度非常大,其数据分布和普通的 RGB 图片有着本质的区别 。
3. 什么是“对齐 (Align)”?为什么要对齐?
以前在 3D 视觉学术界有一种普遍的“常识”:如果你想借用那些在海量图片上训练好的扩散模型的强大先验知识,你就必须把你的 3D 数据伪装成普通图片的样子 。 这就意味着,你需要用一种叫“最大值归一化 (Max Rescale)”的方法,强行把那些无边无际的 3D 坐标数据,按比例硬塞进 [-1, 1] 这个狭窄的盒子里,以此来“对齐”原始 VAE 的输入标准 。
4. MotionCrafter 为什么反对这种“严格对齐”?
这篇论文的一个重要突破就是:他们发现这种严格的对齐不仅没有必要,反而会破坏性能 。
强行对齐的坏处: 如果把一个宏大且深度变化剧烈的室外场景强行压缩到 [-1, 1] 的区间里,很多细微的几何结构和真实的物理尺度信息就会被抹杀,导致模型重建出来的 3D 效果很差(就像把大象按比例硬塞进冰箱,细节全糊了) 。
MotionCrafter 的做法: 他们打破了常规,不再追求把数值严格卡在 [-1, 1] 之间 。他们改用了一种基于“均值和平均距离”的标准化方法(Mean Rescale / Canonical Normalization) 。虽然这样做导致输入给 VAE 的数据范围和原本 RGB 图片的范围不一致(不对齐)了,但实验证明,这种做法更好地保留了 3D 尺度,而且扩散模型依然能完美理解这些数据,重建质量大幅提升 。
framework
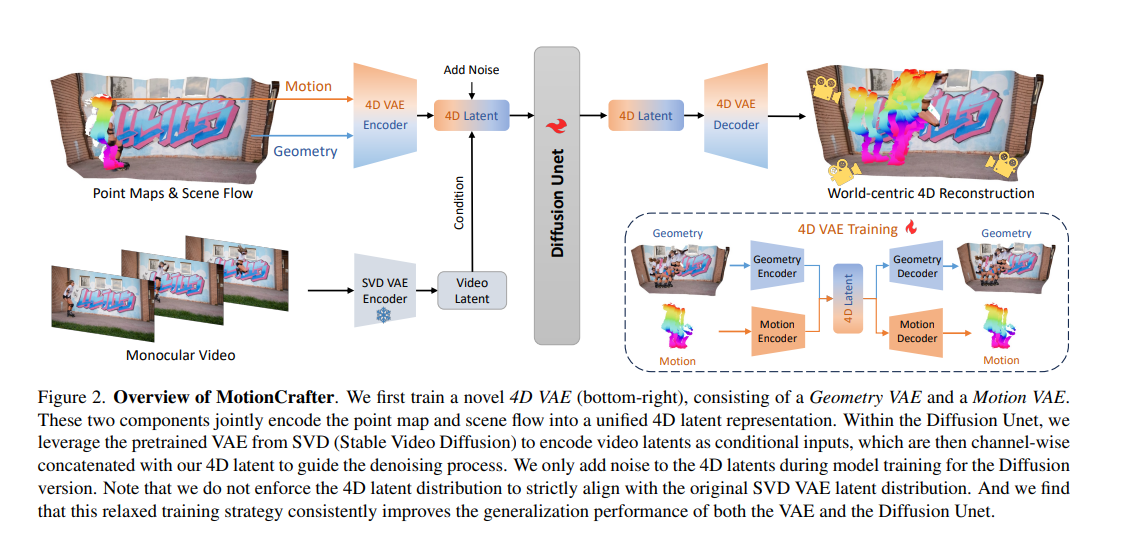
1. 右下角:新型 4D VAE 的训练 (4D VAE Training)
这是系统能理解“4D信息”的基础。
首先,研究人员训练了一个新颖的 4D 变分自编码器(4D VAE)。
这个 4D VAE 由两部分组成:负责处理空间形状的“几何编码器/解码器 (Geometry Encoder/Decoder)”和负责处理运动的“运动编码器/解码器 (Motion Encoder/Decoder)”。
它们协同工作,将输入的点云图(Point Maps)和场景流(Scene Flow)联合压缩编码成一个统一的“4D 潜在表示 (4D Latent)”。这个过程将复杂的3D结构和运动信息打包成了扩散模型更容易处理的格式。
2. 左下角:视频条件提取 (Conditioning)
这部分负责告诉主干网络,当前要生成的4D画面究竟长什么样。
输入的单目视频(Monocular Video)会被送入一个预训练好的视频扩散模型(如 Stable Video Diffusion, SVD)的 VAE 编码器中。
注意该模块下方有一个“雪花”图标,代表这个 VAE 编码器的参数是被冻结(锁定)的,只用来提取视频的潜在特征(Video Latent)。这些视频特征随后作为条件输入(Condition),在扩散模型的去噪过程中提供引导。
3. 上方主干:基于扩散模型的 4D 生成 (Diffusion Unet & 4D Reconstruction)
这是系统的主生成网络。
在模型训练期间,研究人员只对上述提取出的“4D 潜在表示 (4D Latent)”添加噪声(Add Noise)。
接着,带有噪声的 4D Latent 和作为条件的 Video Latent 在通道维度上进行拼接(channel-wise concatenated)。
核心的去噪网络(Diffusion Unet)在这两者的配合下进行去噪,试图还原出干净、准确的 4D Latent。
最后,这个干净的 4D Latent 通过前面训练好的“4D VAE 解码器 (4D VAE Decoder)”,被还原成直观的“世界坐标系4D重建结果 (World-centric 4D Reconstruction)”。
所以 motioncraft 复用了哪些模型 已有的 权重?
直接复用的
feature_extractor:直接从预训练 SVD/扩散模型里加载。见 unet_base.py (line 158)
image_encoder:直接复用 CLIP vision encoder 权重。见 unet_base.py (line 166)
vae:视频这支用的是 AutoencoderKLTemporalDecoder,直接从预训练模型的 vae 子目录加载。见 unet_base.py (line 175)
推理时整个 pipeline 也是从 stable-video-diffusion-img2vid-xt 这套体系加载的,只是把其中的 unet 替换成 MotionCrafter 自己的 UNet。见 run.py (line 129)
部分复用后改造的
最重要的是 UNet。
MotionCrafter 的 UNetSpatioTemporalConditionModelVid2vid 本体不是从零初始化的,而是从预训练 UNet 加载,然后按任务改输入输出通道。加载位置在 unet_base.py (line 212)。
UNet 主干大部分权重是复用的
除了输入层 conv_in 和输出层 conv_out 可能会改,其他 down blocks、mid block、up blocks、时空 attention、resnet 等主体参数基本都继承了原始预训练权重。
deterministic 模式下
conv_in 是从原 8 通道里裁出来的 在 unet_determ.py (line 35): 原始 conv_in.weight 是 [320, 8, 3, 3] 它直接取原权重的 4:8 通道作为新的 4 通道输入层 也就是说 deterministic 模式的输入层不是随机初始化,而是“拿预训练 8 通道输入中的条件部分权重来用”。
diffusion 模式下
conv_in 是“部分复用 + 部分新加” 在 unet_diffusion.py (line 50):新的 12 通道输入层由三段组成 前 4 通道:拷贝原来 0:4 , 中间 4 通道:拷贝原来 4:8 , 最后 4 通道:全零初始化
geometry_motion_vae 也复用了现成 VAE 权重