
Lexical Analysis
https://gemini.google.com/app/1a083e5d938aaf91?hl=zh
易错点
最长匹配和规则匹配 的 概念
最长匹配原则 的 机制和回溯机制
NFA 转 DFA : 交替使用 ϵ闭包 和 输入一个状态 ; DFA 的最小化 : 合并等价状态 (Equivalent states)
历年题
2017年期中考试及答案.pdf
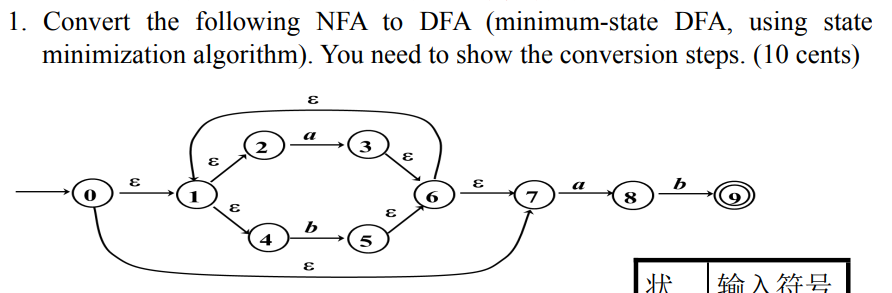
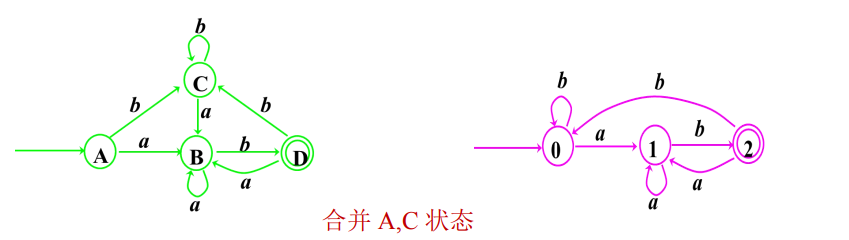
1. 即使是最终状态(左边是D),也要有发出的 a , b 边 , 因为 DFA 就是要每个都状态对应的输入对应的转换要确定的
2. 如何合并? 如果两个状态 ,对应的每个输入转换的状态都一样,即可合并
3. 此题, 先写 每个状态遇到空转移,a转移,b转移 的 对应状态
thompson算法
2023-2024 期末(24期末)
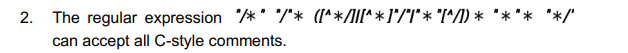
它会拒绝合法的注释(无法处理注释内容中包含 /* 的情况):
在 C 语言中,注释是不支持嵌套的,从第一个 /* 开始直到遇到第一个 / 结束,中间包含任何内容(包括 /)都是合法的,比如 /* hello /* world */ 是一个完全合法的单行注释。
但我们来看正则中循环体 (...) 的部分:([^/] | /[^*] | "*" [^/])。如果它在注释内部遇到了 /* 这个字符串,没有任何一个分支能匹配它:
它会错误地吞掉注释结束符(存在过度匹配的漏洞):
考虑字符串 /* /a /。在真正的 C 语言中,注释会在第一个 / 处结束(即 /* /),剩下的 a */ 会导致语法错误。
但这个正则表达式会错误地把整串全部当成一个注释
(
[^*/]): 匹配任何不是*且不是/的单个普通字符(比如字母、数字、空格等)。
期中卷1.pdf
2020-2021 回忆卷
2021-2022 回忆卷
2022-2023 回忆卷 / 23年期末整理
Parsing
https://gemini.google.com/app/5e403762f476a57b?hl=zh
复习
预测分析(Predictive Parsing) / 递归下降(Recursive-descent)
这是一种自顶向下的解析方法。它能正常工作的前提条件极其严格——仅凭输入字符串的“第一个终结符(first terminal symbol)”,就必须能明确决定使用哪一条产生式
解决问题: 之前 为了解决
1+2*3和1-2-3歧义问题 提出了 无二义性表达式文法 . 它通过严格的层级划分,完美地规定了运算符的优先级和结合性因式 F (Factor): 代表优先级最高的基本单元。产生式为 F→id∣num∣(E) ; 项 T (Term): 代表乘除法运算。产生式为 T→T∗F∣T/F∣F ; 表达式 E (Expression): 代表优先级最低的加减法。产生式为 E→E+T∣E−T∣T
第一张图片指出,尽管前面章节构造出了完美的、无二义性的文法(比如引入了 E, T, F 来控制优先级),但在实际写代码时,解析器依然会陷入困境:程序不知道该走哪条分支。 直观的例子: 假设编译器正在解析两个字符串:(1*2-3)+4 和 (1*2-3) 矛盾点: 编译器是从左到右逐个字符读取的。在这两种情况下,编译器看到的第一个字符都是左括号 (。仅凭这个 (,解析器根本无法“预知”句子末尾到底有没有 +4。这就导致程序卡住了,不知道该调用哪条推导规则
推算出 每个 符号的 isnull , 迭代推出 其他isnull , 再根据 isnull 和 first 推出 follow (略)
构建预测分析表
题目
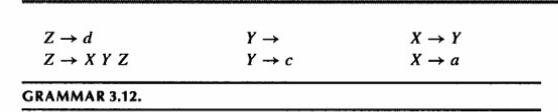
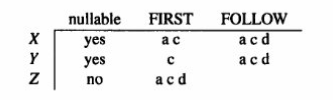
填表规则
看 FIRST 集: 如果有一条规则 X→a,并且下一个输入的字符正好是 a,那就把 X→a 填到表格的
[X, a]单元格里。看 FOLLOW 集(针对可空符号): 如果 Y 可以推导为空(Y→ϵ),编译器就会去查 Y 的 FOLLOW 集。只要输入的字符在 Y 的 FOLLOW 集中,就把 Y→ (空) 这条规则填进去。意思是:“既然遇到这个字符了,说明当前结构已经结束,直接让 Y 变为空即可”。
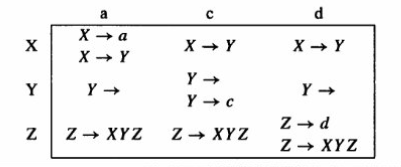
如果你仔细观察图 3.14 的分析表,你会发现一个严重的问题:有很多单元格里填了不止一条规则!
例如,在行 X 列 a 的格子里,同时存在 X→a 和 X→Y 两条指令。
这意味着什么? 这意味着即使编译器提前看了一个字符,它依然不知道该选哪条代码分支。这就是我们之前提到的冲突(Conflict)。
如果一个文法在构建预测分析表时,没有任何一个单元格包含重复的规则(即零冲突),那么这个文法就被称为 LL(1) 文法
第一个 L (Left-to-right): 解析器从左到右依次读取源代码的字符。
第二个 L (Leftmost-derivation): 解析器在推导语法树时,总是优先展开最左边的非终结符。
什么是左递归?为什么它是 LL(1) 的死穴?
E→E+T
E→T
因为 E 可以推导出 T,所以 T 的 FIRST 集和 E+T 的 FIRST 集一定会发生重叠。一旦重叠,预测分析表里就会出现冲突。因此得出一个铁律:含有左递归的文法绝对不可能是 LL(1) 文法。
既然如此,我们可以换一种思路重写文法(引入一个新的非终结符 E′):
先抓住打头的元素: 任何表达式肯定是以 T 开头的。
E→TE′
用右递归处理尾巴: 剩下的部分交由 E′ 处理。E′ 要么是一个+T 后面再跟着一个 E′,要么就什么都没有(直接结束)。
E′→+TE′
E′→ϵ
此时的文法(Grammar 3.15)已经是一个纯正的 LL(1) 文法。编译器只要查这张表,看一眼当前状态(行)和下一个输入的字符(列),就能毫不犹豫地选择唯一正确的代码分支,绝不会死循环,也不会陷入歧义。
新的危机:相同前缀 (The Problem)
假设我们要解析编程语言里的条件语句,文法通常是这样的:
S→if E then S else S (带有 else 分支)
S→if E then S (只有 if 分支)
为什么会冲突? 当解析器遇到单词
if时,它会去查 FIRST 集。很显然,这两条规则的 FIRST 集都包含if。解析器仅仅通过往前看一个字符(if),根本无法预知这行代码到了末尾到底有没有else。因此,在预测分析表里,[S, if]这个格子里又会同时塞进这两条规则,导致冲突。改造后的文法如下:
提取公共前缀: S→if E then S X
让新符号 2X 处理分歧:
X→else S (对应原本有 else 的情况)
X→ϵ (对应原本没有 else 的情况,ϵϵ 即图片中右侧留空的部分,代表空字符串)
LR 解析算法的全流程
准备工作: 查看栈顶的状态,并偷看下一个输入字符,去状态转移表里查出对应的动作(Action)。
如果动作是
Shift(n):把输入流的游标往后挪一位(消耗掉一个字符)。
直接把状态 n 压入栈顶。(代表带着这个字符进入了新状态)。
如果动作是
Reduce(k)(最复杂也最精妙的一步):去看第 k 条语法规则长什么样(假设规则是 X→A B C)。
这条规则右边有几个符号(比如有 3 个),就从栈顶连续弹出(Pop)几次。这相当于把 A,B,C 对应的状态都清除了,露出了在读入 A 之前的“老状态”。
找到规则左边的非终结符(这里是 X)。
拿着刚才露出来的“老状态”,结合非终结符 X,去表里查一个 Goto(n) 动作。
把状态 n 压入栈顶。(这就相当于把 A,B,C 打包成 X 后,重新送回了栈里)。
如果动作是
Accept: 停止循环,宣布代码编译成功。如果动作是
Error: 停止循环,报错(或者进入上一节提到的错误恢复机制)。
LR(0)
例
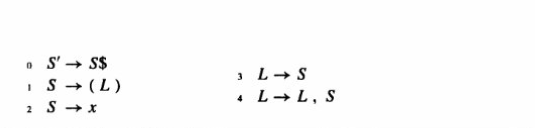
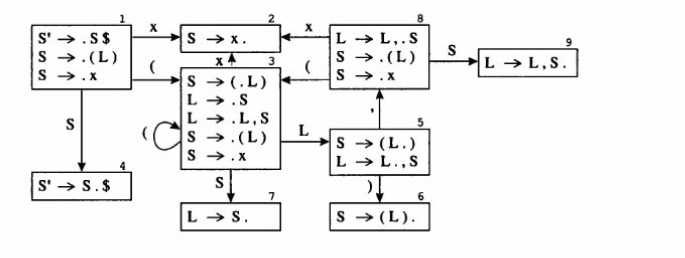
DFA 貌似只画 移进 和 跳转,不画规约, 但实际上规约已经蕴含在里面了. 没有出箭头的 状态就是准备规约的状态, 每次跳转之前都是经过规约的

reduce n 表示 这是按文法中的第 n 条规则规约 , 而不是 第n个状态
LR(0) 为什么太弱了?
最后一张图给出了一个全新的文法(Grammar 3.23)。这是一个极其常见的算术表达式文法:
S→E
E→T+E
E→T
T→x
为什么作者要在这里引入它?
这实际上是一个“反面教材”。如果你尝试用前面的算法为这个 Grammar 3.23 构建 DFA,你一定会在某个状态中遇到类似这样的组合:
E→T. (圆点在最后,暗示需要归约)
E→T .+E (期待读取一个
+号,暗示需要移进)
回想第一张图末尾的论断:“一个状态要么移进,要么归约,不能兼有”。
但在处理这个极其普通的加法文法时,LR(0) 的状态机里不可避免地出现了既想“移进”又想“归约”的状态。由于 LR(0) 算法不允许往后看哪怕一个字符,它根本不知道当前是该把 T 归约掉,还是该把后面的
+移进栈里。表格里会出现重复条目这种冲突在编译原理中被称为 移进-归约冲突 (Shift-Reduce Conflict)。这张图实际上是在宣告 LR(0) 算法的破产,并为下一节引出更强大的 SLR 或 LR(1) 算法(允许往后看字符来解决冲突)做好了铺垫。
SLR
它的状态机(DFA 图)和 LR(0) 是一模一样的 . 回顾 LR(0) , 只要发现圆点走到了最后(例如 A→α.),LR(0) 就会在这一行的每一个终结符列里全填上 reduce。这就是冲突的根源 . 当发现 A→α. 时,SLR 不再盲目填表,而是去查阅非终结符 A 的 FOLLOW 集 只有当下一个即将读入的字符 X,刚好存在于 FOLLOW(A) 集合中时,SLR 才会在 (I,X) 这个格子里填入 reduce
如果一个文法按照 SLR 的规则画出的解析表里没有任何冲突,那它就是 SLR 文法
但 SLR 依然有一个弱点:FOLLOW 集是全局的。也就是说,只要某个字符能跟在非终结符 X 后面,SLR 就会允许归约。但这有时过于宽泛了,在某些极端的上下文中依然会导致冲突。
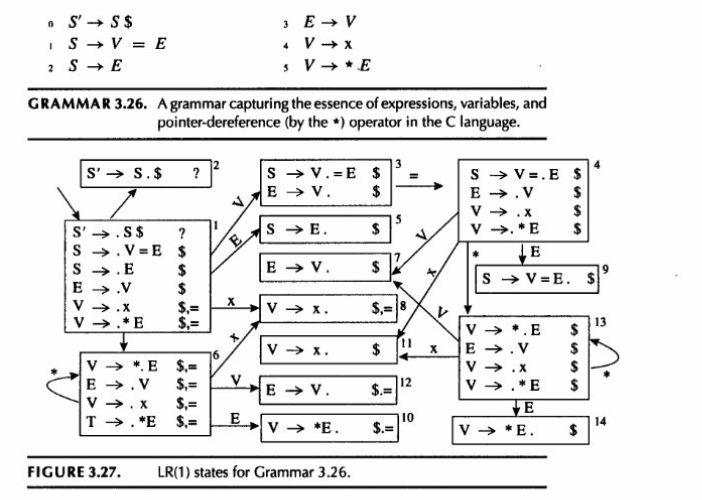
LR(1)
全新的概念:LR(1) 项目 (LR(1) Items)
在 LR(1) 中,项目升级为了一个二元组:
(A→α.β,x)
逗号后面的 x: 这就是 lookahead(向前看符号)。
物理意义: 这个项目的意思是,解析器目前已经读取了 α,期待接下来读出能由 β 推导出的字符串;并且,仅仅当紧跟在 β 后面的下一个字符是 x 时,解析器才被允许在未来将这一整段归约为 A。
LR(1) 的闭包运算:Closure(I)
这是 LR(1) 算法中最精妙、也是最难理解的一步。当圆点停在一个非终结符前面时,我们需要展开它的子规则。但是,这些新展开的子规则,它们的 lookahead 应该填什么呢?
图片中的算法给出了严密的数学定义:
假设当前有一个项目是 (A→α.Xβ,z),圆点在非终结符 X 前面,当前的 lookahead 是 z。
现在要把 X 展开,加入规则 X→.γ。
决定新 lookahead 的公式:w∈FIRST(βz)
通俗解释: 什么是能合法跟在 X 后面的字符?当然是在当前这条具体规则里,排在 X 后面的那个 β 的开头字符(即 FIRST(β))。
如果 β 是个空字符串(或者可以隐身),那么跟在 X 后面的自然就是继承下来的、跟在 A 后面的那个 lookahead 符号 z。
因此,把 β 和 z 拼起来求 FIRST 集,就能算出在此时此地的绝对上下文中,究竟哪些字符才配跟在 X 后面。这就比 SLR 全局乱查 FOLLOW 集要精准无数倍!
LR(1) 的跳转运算:Goto(I, X)
这个操作相对简单,和 LR(0) 几乎一模一样,只是把 lookahead 顺手“夹带”过去:
在集合 I 中找所有圆点在 X 前面的项目 (A→α.Xβ,z)。
让圆点跨过 X,变成 (A→αX.β,z)。注意,在此过程中 lookahead z 保持不变。
把这些新项目放入集合 J,然后对 J 重新跑一遍上面的
Closure(J)算法,就得到了新的状态。
初始状态的定义
算法的起步点是计算初始项目的闭包:
(S′→.S$,?)
这里的S′ 是整个程序的增广起始符号,$ 是文件结束符。
逗号后面的
?代表此处填什么 lookahead 都无所谓。因为$ 本身就代表了文件的绝对终点,解析器永远不可能跨过 $ 去读取后面的东西,所以无需关心。
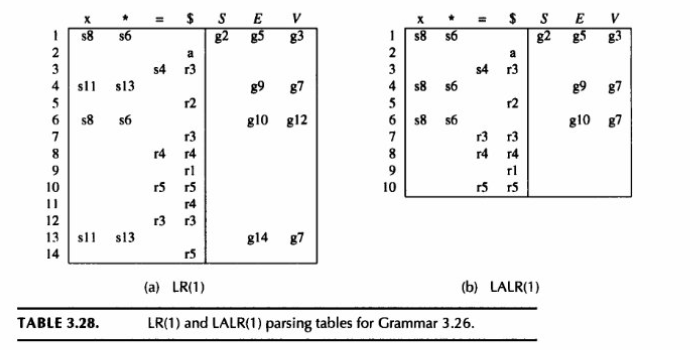
LALR(1)
合并条件: 仔细检查 LR(1) 生成的所有状态。如果发现哪两个状态里的项目,除了逗号后面的 lookahead 集合不一样之外,前面的核心部分(产生式规则和圆点位置)完全一模一样,就立刻把它们合并成一个新状态。
合并效果: 图片中给出了示例(比如将状态 6 和 13 合并,7 和 12 合并等)。合并后,新状态的核心规则不变,而 lookahead 集合变成了原来几个状态的并集。这样生成的解析器,就被称为 LALR(1) 解析器。
历年题
T1 2017年期中考试及答案.pdf
求First 的时候,空串ε不能丢, LL(1) 表中如果有的话也要 写上ε列
Yacc
Yacc 用 LALR(1)
冲突默认 shift
语义值 $1, $2, ... ($$ = $1 + $2 )
语义值放在 value stack
在 Yacc(以及 Bison 等类似的语法分析器生成工具)中,生成的自底向上(Bottom-Up)解析器在运行期间实际上维护着两个平行且同步的栈:
Parsing Stack(解析栈 / 状态栈): 用于控制语法的解析流程,里面存放的是状态机的状态编号(States),用来决定解析器下一步是执行移进(Shift)还是归约(Reduce)。
Value Stack(值栈 / 语义值栈): 专门用于存储与解析栈中符号相对应的语义值(Semantic Values)。
它的工作机制如下:
每当解析器读取到一个词法标记(Token)或完成一次非终结符的归约,并将相应的状态压入解析栈时,该符号携带的具体信息(比如一个
num标记代表的实际数字、或者一个表达式计算出的抽象语法树节点)就会被同步压入 value stack 中。这也就是为什么你在 Yacc 中可以写出类似
$$ = $1 + $3这样的代码。这里的$1和$3本质上就是解析器在归约时,去这个平行的 value stack 里提取出来的对应语义值。
2020-2021春夏编译原理%20回忆卷.pdf

尽管看起来有 R --> L , L --> *R 循环,但实际上每循环一次 都会消耗 一个 * , 这里没有 空循环和 ε 产生式 , 所以不会溢出

合并同心集后,各状态中都不存在 shift/reduce 或 reduce/reduce 冲突,所以该文法是 LALR(1) 文法
别忘了 每推出一个新状态后要做闭包运算! 每个新状态(包括初始状态)内的闭包运算可以是迭代的!
去除文法左递归时 别忘了 给 新非终结符 的右侧 加上 | ε
24期末.pdf
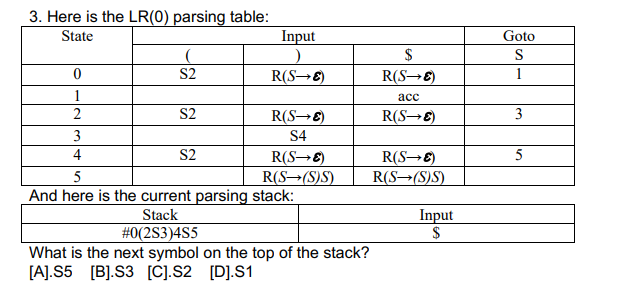
D , 其实这题更像 SLR , 如果是 LR(0) 的话, 每个状态点在 S之前的状态 都可以做规约 r0 (epsilon) (因为DFA由状态点在 S之前的的规则 得出的该state的新规则 由于点在最后(空即最后),又可以在接下来的填表中写入 r
根据 表格反推 DFA 即可
lex / output of lex / yacc / output of yacc 哪个是 scanner
为了更清晰地理解它们之间的关系,我们可以把它们分为“生成工具”和“最终产物”:
Lex: 是一个 Scanner Generator(扫描器生成工具)。你写好包含正则表达式的规则文件(
.l文件),Lex 会读取它并将其“翻译”成 C 语言代码。Output of Lex: Lex 生成的 C 语言代码(默认通常名为
lex.yy.c)。这段代码在被编译器(如 GCC)编译并运行后,才是真正在程序中负责逐个读取输入字符、并把它们组合成 Token(记号)的 Scanner。Yacc: 是一个 Parser Generator(语法分析器生成工具)。它读取包含上下文无关文法的文件(
.y文件),并生成相应的 C 语言代码。Output of Yacc: Yacc 生成的 C 语言代码(默认通常名为
y.tab.c)。编译运行后,它充当的是 Parser(语法分析器),负责不断向 Scanner 索要 Token,并根据语法规则构建语法树。
Daily
LR(0)/SLR 状态机问题 : 所以说 如果 两个式子 属于同一个 LR(0) 状态机 的 同一个 I 中的时候,只有以下两种情况:1. 注意到I中的第一项,如果第一项关系式中的点后面是个非终止符的话,那么这个终止符可以推出一系列表达式,如果推出的表达式第一项也是非终止符,那么可以递归下去;最终 生成出来的表达式,-> 左侧是那个非终止符,右侧的点永远在最前面; 2. 由于LR(0)只能根据 当前吞入的字符判断状态,那么 假设I0 中有两个这样的状态关系式 : S -> .V=E , E -> .V , 那么当我们仅吞入一个 V 的时候,我们不知道这属于 I0 的哪个,所以需要在 I1中写出两个 : S -> V.=E , E -> V. ,可以观察到这种情况下会导致 I 中有超过一项 关系式的 -> 右侧 的 . 不在最前面 。 我的理解正确吗?
https://gemini.google.com/app/9bd92601bd74a8df?hl=zh
Yes



对于可能出现左递归的语法,其LL(1)预测表中会产生conflict,据此可判断它不是LL(1); 但对于右递归算法,LL(1)没有conflict的情况,为什么还算LL(1)?

LL(1)是自顶向下的,也就是说,对于一个字符串,我们拿到他的一个字母w, 之后,需要从当前非终止符S推出这个w;如果有conflict的话,那么在这里就会有两条规则 使得 S 的第一个字母可以推出w,就难以选择了
SLR 相对于 LR(0)


举例一个 SLR能解决 但 LR(0)不能解决的情况



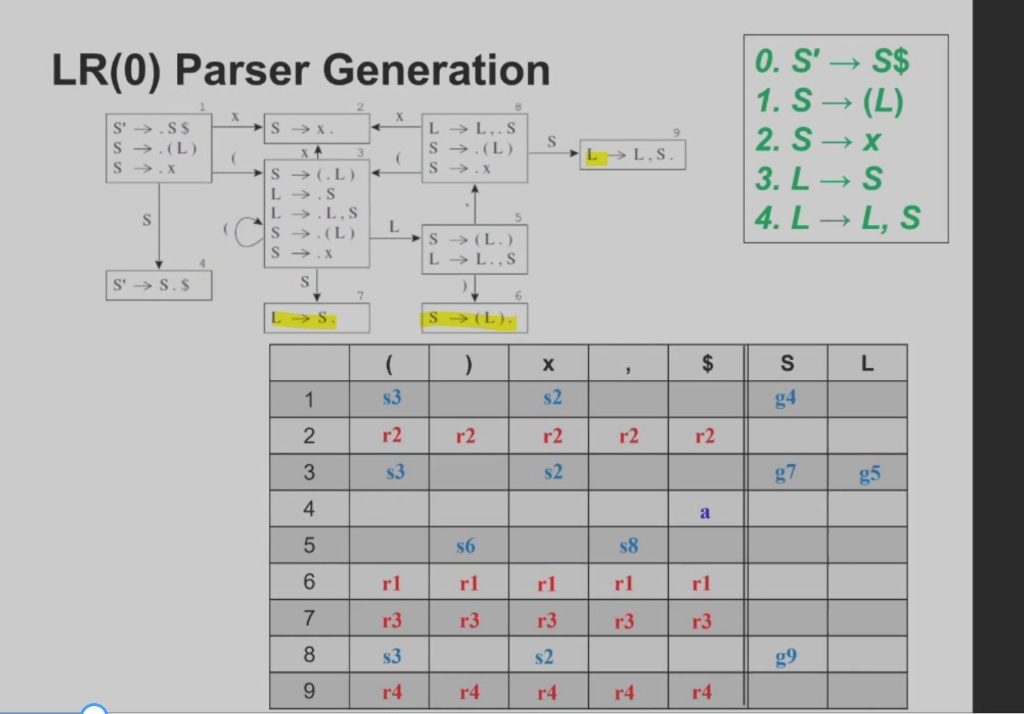
T1

第一步:LR(0) 状态机 (Automaton)

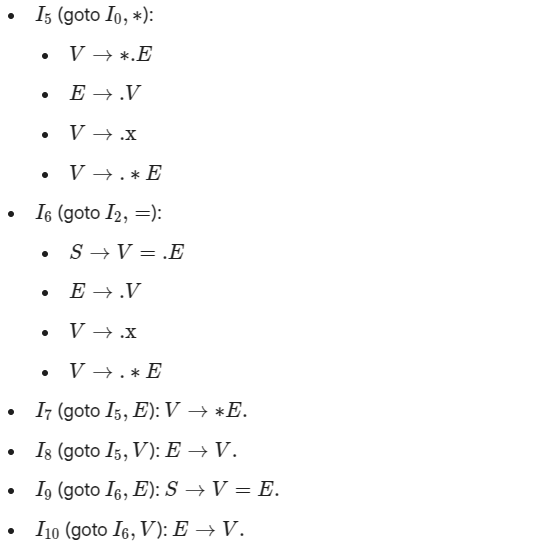
这里 I2 的 冲突 LR(0) 和 SLR 都无法解决
可以看到,除了I0, 其他 (例如I5) 只有在 ->右侧 . 后面是非终止符时,才会继续递归下去
第二步:计算 FOLLOW 集合(在通过 LR(0)状态机制作 SLR表的时候,我们该如何知道哪个地方应该填reduce呢?当LR表的一个箭头表达式的 . 在最后,并且->前面的状态的FOLLOW中包含下一个输入的内容,则可以进行填写reduce,reduce里的数字 参考算FOLLOW时的顺序 )

第三步:SLR 预测分析表
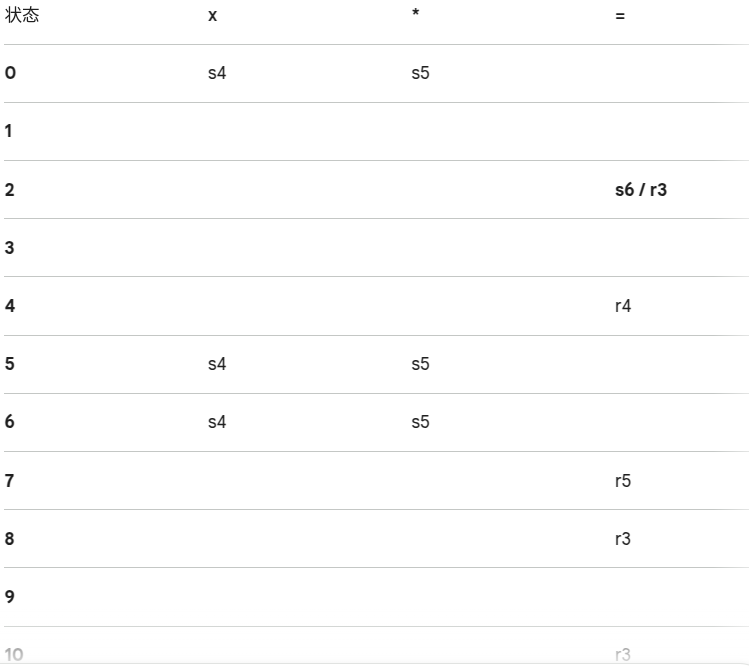
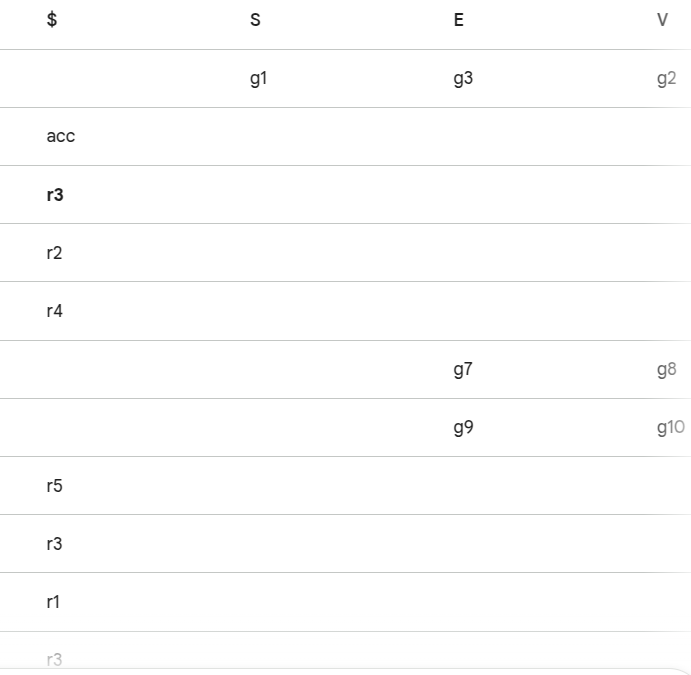
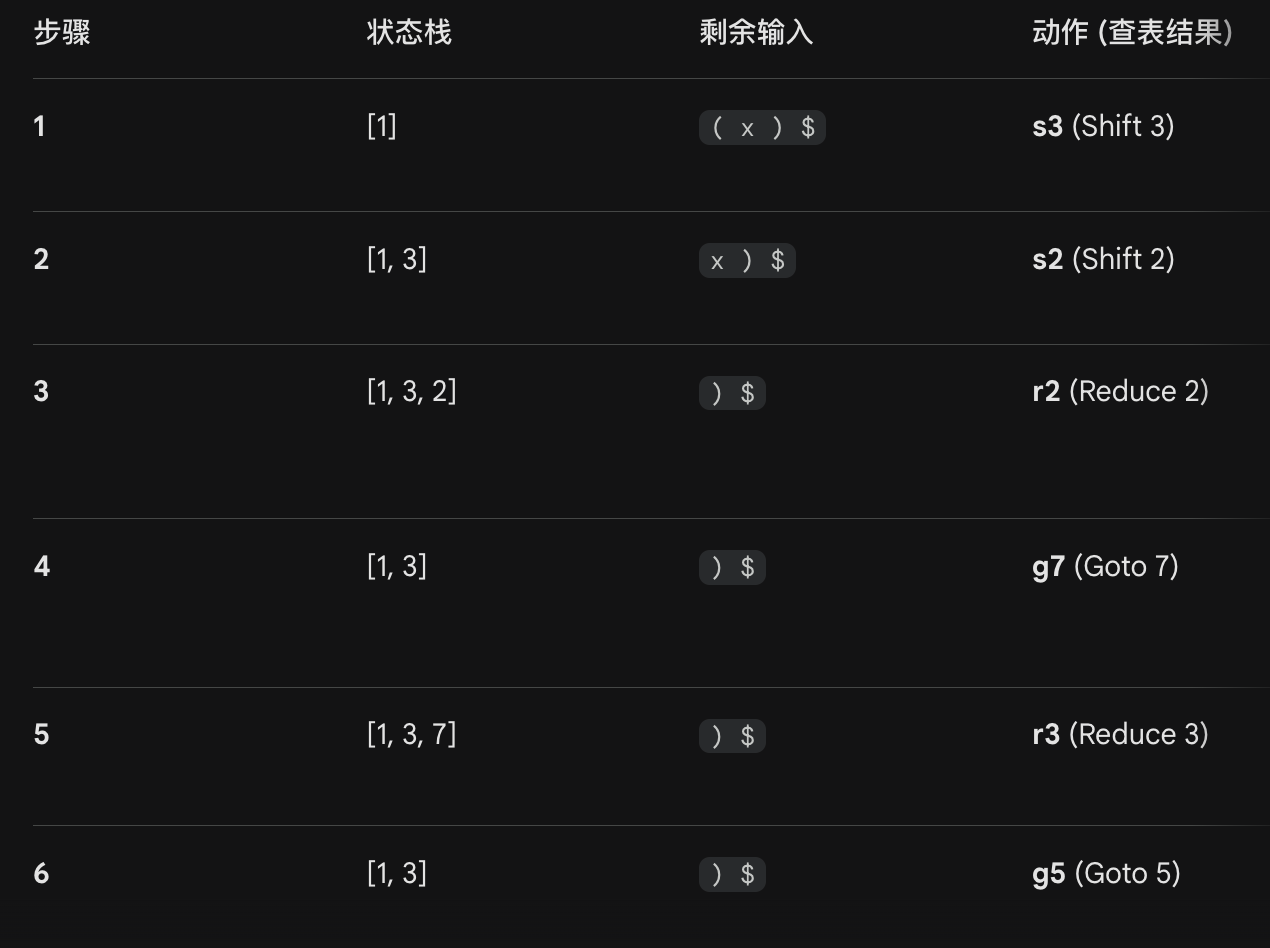
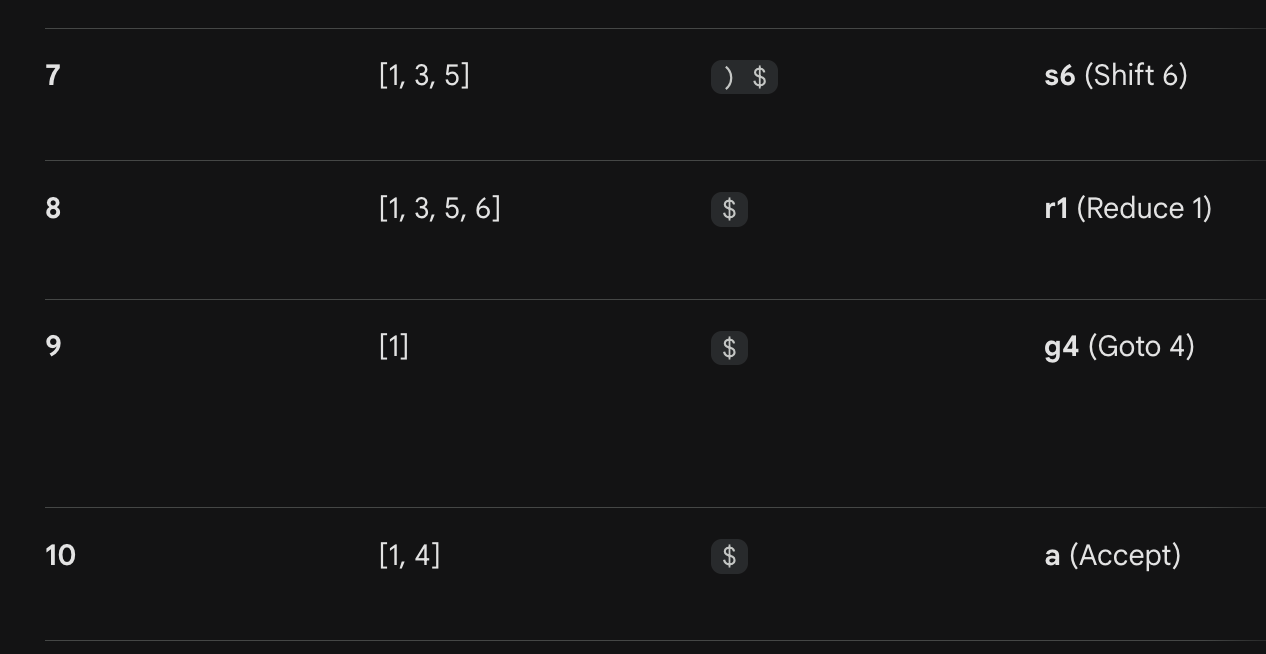
模拟

more clear (LR(0),它不看下一个输入是什么,只要点到了最后,就强制规约。)
ESEQ(
SEQ(
MOVE(TEMP t1, CALL(NAME_f, [TEMP_x])),
SEQ(
MOVE(TEMP_x, CONST_0),
MOVE(TEMP t2, CALL(NAME_g, [TEMP_x]))
)
),
BINOP(PLUS, TEMP t1, TEMP t2)
)Abstract Syntax
1. 抽象语法是什么
课本先区分了两种树:
concrete parse tree:具体语法树,严格跟文法规则一一对应,里面会保留很多语法细节,比如括号、层层的 E/T/F
abstract syntax tree:抽象语法树,只保留“程序真正的结构” 比如 2 + 3 * 4:
具体语法树会有 E -> E + T、T -> T * F、F -> n 这些层次 , 抽象语法树只关心这是一个 PlusExp(2, TimesExp(3,4))
所以抽象语法的核心思想是:
去掉对后续阶段没用的符号,比如 ( ) 这种纯解析符号 ; 不让后续阶段依赖具体文法写法 ; 给语义分析、类型检查、IR 翻译一个更稳定的数据结构接口
2. 语义动作是什么
语义动作就是:parser 在识别某个产生式时,顺手做的事
这一章里说得很明确,parser 不应该只判断“句子是否合法”,它还可以:
1. 构造 AST 2. 直接求值 3. 做语义检查 4. 生成中间代码
在递归下降里,语义动作通常表现为:1. 解析函数的返回值 2. 或者解析函数产生的副作用 3. 或者两者都有
例如: F -> num:返回这个数字 ; F -> id:查符号表,返回这个标识符相关的值 ; exp -> exp PLUS exp:把左右子树组合成 A_PlusExp($1, $3),或者直接算 $1 + $3
在 Yacc/Bison 里,语义动作就是花括号里的代码: $1, $2, $3 表示右侧各符号的语义值 ; $$ 表示左侧非终结符的语义值
例如
exp : NUM { $$ = A_NumExp($1); }
| exp PLUS exp { $$ = A_PlusExp($1, $3); }
| exp TIMES exp { $$ = A_TimesExp($1, $3); }所以“语法分析”和“简单翻译/求值/建树”可以绑在一起做
递归下降 / Yacc 是“怎么解析” ; 语义动作 是“解析时顺手做什么” ; 抽象语法树 是“把解析结果保存成什么形式,交给后续阶段”
递归下降解析器, 它的工作方式是 : 从开始符号往下展开 , 一边看当前输入,一边决定用哪个产生式, 很适合讲义里的“语义动作”“返回值”“建 AST” , 但 一般要求文法适合预测分析,常见是 LL(1) . 特点是每个非终结符对应一个函数,比如 E()、T()、F()
Semantic Analysis
https://gemini.google.com/app/2943eca4f3acf543?hl=zh
https://wanghx2025.notion.site/Chapter-5-Semantic-Analysis-33e9c6b6155b80139c8fe34b4adac3ca
历年题
2019-2020 春夏期末机考

词法分析 (Lexical Analysis):
它的任务是读取源代码的字符,并将其转换为有意义的词素。
输出:a token stream(记号流/词法单元流)。所以选项 D 是词法分析的输出。
语法分析 (Syntax Analysis/Parsing):
它的任务是接收 Token 流,检查这些词法单元是否符合语言的语法规则。
输出:a syntax tree(抽象语法树 AST)或 a parse tree(解析树/具体语法树)。所以选项 A 和 C 是语法分析的输出(也是接下来语义分析的输入)。
语义分析 (Semantic Analysis):
它的任务是接收前面生成的语法树,并结合符号表(Symbol Tables,正是你之前学习的内容)来检查程序在语义上是否合法。主要工作包括类型检查(Type Checking)、作用域解析、变量声明检查等。
输出:语义分析通常不会去创建一个全新的树结构,而是将收集到的类型信息、属性、以及指向符号表中条目的指针附加(annotate/decorate)到原有的语法树节点上。
因此,这棵经过信息填充和装饰的树,就被称为 an annotated tree(带有注释/标注的树)。
2019-2020 春夏期末机考 2

在语法分析树中:
综合属性 (Synthesized Attribute):它的值是由其子节点的属性值、以及节点自身的其他属性(比如自身的继承属性)计算得来的。数据流向是自底向上(Bottom-up)的。
继承属性 (Inherited Attribute):它的值是由其父节点的属性值、及其兄弟节点的属性值计算得来的。数据流向是自顶向下(Top-down)或从左到右(侧向)的。
2019-2020 春夏期末机考 3 判断题

Yacc 实际上是可以处理二义性文法(ambiguous grammars)的,而且在实际的编译器开发中,使用二义性文法配合优先级规则是非常常见且被推荐的做法。
以下是具体的原理解释:
冲突的产生:当提供给 Yacc 一个二义性文法时,它在构建 LALR 解析表时必然会遇到移进/规约冲突(Shift/Reduce Conflicts)或规约/规约冲突(Reduce/Reduce Conflicts)。
Yacc 的解决机制:为了解决这些冲突,Yacc 提供了强大的声明机制,允许用户显式地定义操作符的优先级(Precedence)和结合性(Associativity)。
例如,使用
%left(左结合)、%right(右结合)或%nonassoc(无结合性)等关键字。
经典案例(四则运算):
假设我们要处理算术表达式。非二义性文法通常非常冗长(需要引入
Expr,Term,Factor等多个非终结符),而直接写出的二义性文法非常直观:E→E+E∣E∗E∣id
在 Yacc 中,你完全可以直接使用上面这个二义性文法,只需要额外声明
*的优先级高于+即可。当 Yacc 遇到状态冲突时,它会查阅你定义的优先级规则来决定是“移进”还是“规约”,从而完美消除二义性。
Activation Records
https://gemini.google.com/app/8b806ab764ed600b?hl=zh
栈帧内部结构
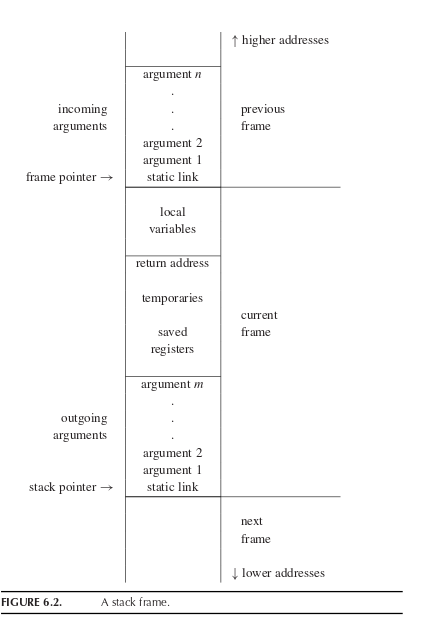
首先观察图 6.2 的右侧:高地址(higher addresses)在上,低地址(lower addresses)在下。栈是像冰柱一样向下生长的。
为了在这个大冰柱中准确定位数据,系统使用了两个关键的“路标”寄存器:
栈指针 (stack pointer, SP): 指向当前栈的最底部(即警戒线),图中最下面一条横线。它的位置会随着栈帧的分配和释放动态变化。
帧指针 (frame pointer, FP): 也叫基址指针。它指向当前栈帧的顶部边界(图中间偏上的横线)。为什么需要它? 因为 SP 可能会在函数执行期间动态移动,导致相对位置不稳定;而 FP 在整个函数执行期间是固定不动的,编译器可以非常稳定地以 FP 为基准点(通过加减偏移量)去寻找局部变量和参数。
栈帧内部结构拆解(从高地址到低地址 / 从上到下)
按照图表的顺序,一个正在执行的“当前栈帧(current frame)”连同它的上下文包含以下几个核心区域:
1. 传入参数 (incoming arguments)
物理位置: 紧挨着帧指针的上方。严格来说,它其实是上一个栈帧(调用者)底部的一部分。
作用: 当上一层函数调用当前函数时,上一层函数负责把参数放在这里。当前函数启动后,通过 帧指针 + 偏移量 就能读取到别人传给它的数据。
2. 静态链 (static link)
作用: 这正是呼应了你最初发的第一张图中“嵌套函数”的概念! 在支持嵌套定义的语言(如 ML、Pascal)中,如果当前函数是嵌套在另一个函数内部的,这个指针就指向其外部包裹函数的栈帧,目的是为了让内部函数能顺藤摸瓜,找到并使用外部函数的局部变量。如果是 C 语言,通常没有这个区域。
3. 局部变量 (local variables)
作用: 存储当前函数内部定义的、且无法放入 CPU 寄存器的变量(例如太大的数组,或者寄存器不够用时溢出的变量)。文字中也提到,现代编译器为了优化速度,会优先把变量放在寄存器里,栈只作为“备用仓库”。
4. 返回地址 (return address)
作用: 由 CPU 的
CALL指令自动写入。它记录了当前函数执行完毕后,CPU 应该回到上一层函数的哪一行代码继续执行。这是函数能“按原路返回”的关键。
5. 临时变量与保存的寄存器 (temporaries & saved registers)
作用: 现场保护。CPU 里的寄存器是全局共享的稀缺资源。如果当前函数需要借用某个寄存器做计算,而这个寄存器里碰巧存着上一层函数的重要数据,当前函数就必须先把它“备份”到自己栈帧的这个区域里。等自己马上要执行完返回时,再从这里把数据读出来恢复到寄存器里,做到“完璧归赵”。
6. 传出参数 (outgoing arguments)
作用: 如果当前函数自己又要调用下一个子函数,它就会在自己栈帧的最底部开辟一块空间,把传给子函数的参数提前摆放在这里。
妙处: 当子函数被调用、产生“下一个栈帧(next frame)”时,这块“传出参数”区域,就自然而然地变成了子函数的“传入参数 (incoming arguments)”区域,完美衔接!
跨越栈帧找变量
为了让内部函数能顺藤摸瓜找到外部变量,教材列出了三种经典方案:
方案一:静态链 (Static Links) —— 也就是本书重点介绍的方案
原理: 每次调用一个函数 f 时,编译器都会偷偷给它多传一个隐藏的指针。这个指针永远指向在代码字面上直接包裹它的外层函数的栈帧。
比喻: 就像每个子节点都牵着一根绳子连着它的亲生父亲。如果要找爷爷的变量,就顺着自己的绳子找到父亲,再顺着父亲的绳子找到爷爷。
方案二:全局显示表 (Display)
原理: 维护一个全局数组。数组的第 1 个格子永远指向当前最外层的栈帧,第 2 个格子指向第二层,以此类推。
比喻: 相当于在大堂设了一个“当前活跃层级导航牌”。内部函数不用自己顺藤摸瓜,直接去查导航牌就能瞬间定位到任何一层的栈帧。这种方法查找极快,但维护导航牌的成本较高。
方案三:Lambda 提升 (Lambda Lifting)
原理: 返璞归真!既然找外层变量这么麻烦,干脆不要外层变量了。如果
indent需要用n和output,编译器会在底层直接把 indent 改写成 indent(i, s, n, output)。把所有需要跨层访问的变量,统统变成显式传递的普通参数。比喻: 既然你不认识去总部的路,那总部派任务时,直接把你需要的所有资料都打包塞到你手里。
如何传递和使用静态链

Line 21 & Line 15 (老子调儿子): prettyprint 调用 show;或者 show 调用 indent。 编译器操作: 调用者会把自己的当前栈帧指针(Frame Pointer)作为静态链传给子函数。
Line 17 (自己调同辈 / 递归调用): show 内部由于递归,再次调用了一个新的 show。 编译器操作: 调用者(旧 show)会把自己现有的静态链,原封不动地传给新 show。
Line 12 (indent 找 show 的 n):indent 在深度 3,show 在深度 2。深度差 = 3 - 2 = 1。底层动作: 编译器生成机器码,让程序顺着 indent 的静态链往上跳 1 次,来到 show 的栈帧,成功读取变量 n。
Line 13 (
indent调用write):这是一个稍复杂的例子。
indent(深 3) 要调用write(深 2)。write运行需要一个指向 prettyprint (深 1) 的静态链。底层动作:
indent必须先顺藤摸瓜跳 2 次,找到 prettyprint 的栈帧地址,然后把这个地址作为“大礼包”传给即将启动的write。
静态链(Static Link)的指向,是由函数在代码里“定义的位置”(静态词法结构)决定的,而不是由它“被谁调用”(动态运行过程)决定的。
历年题
24期末1

D
通过 帧指针 (FP) 访问的变量
传入参数 (Incoming Arguments) 需要分配到内存的局部变量 (Local Variables) (也就是我们在前面“变量逃逸”一节中提到的那 6 种必须放在内存里的局部变量(比如被取了地址、被嵌套函数访问、数组等) 静态链指针 (Static Link)
通过 栈指针 (SP) 访问的变量
传出参数 (Outgoing Arguments) 临时变量和中间计算结果 (Temporaries) 原因: 比如执行一个非常复杂的数学公式 a * b + c / d - e ...,如果寄存器不够用了,CPU 就必须把一些算到一半的中间结果临时存到内存里(这就叫 Spill 溢出) 被保存的寄存器 (Saved Registers)
24期末2

Saved fp pointer (保存的帧指针): 完全正确。我们在讨论“为什么需要 FP”那一节时提到过,当函数 A 调用函数 B 时,B 启动时做的第一件事(函数序言 Prologue),就是把 A 的旧帧指针(FP)保存(压入)到 B 自己的栈帧里。等 B 执行完毕准备返回时,再从栈帧里把它取出来恢复到 CPU 的寄存器中,确保 A 能够按原样恢复现场。因此,“保存的旧 FP”是栈帧(激活记录)中极其核心的标配成员。
[A] Static variable (静态变量) & [D] Global variable (全局变量): 它们被统一安排在内存中一块专门的 全局/静态数据段 (Data Segment / BSS) 里
[B] Sp pointer (栈指针) 栈指针 (SP, Stack Pointer) 是 CPU 内部的一个物理硬件寄存器
在同一个单线程的调用栈中,不可能同时存在多个 leaf procedure(叶子过程)的栈帧
这要从“调用栈的生长规律”和“叶子过程的定义”这两个硬性条件说起。
叶子过程的绝对定义: 叶子过程是指在自己的代码内部绝不调用任何其他函数的函数。它就像树枝的最末端。
栈帧的 LIFO(后进先出)机制: 只有当函数 A 调用函数 B 时,B 的栈帧才会被叠加(压入)到 A 的栈帧之上/之下。当前正在执行的函数,永远位于栈的最顶端(或生长的最底端)。
跨过程调用还要继续存活的变量,适合放 caller-save 还是 callee-save
如果变量在一次调用前后都要保留,那么放在 callee-save register 更合适 因为被调用者必须负责恢复它
不跨过程调用的变量,适合放 caller-save , 因为调用者可以主动选择不恢复
access link 也就是 static link
它表示的是 defining environment / lexical environment , 用来找到词法外层过程的活动记录,从而访问 non-local non-global 变量
calling environment 对应的是:control link / dynamic link
2020-2021 回忆卷
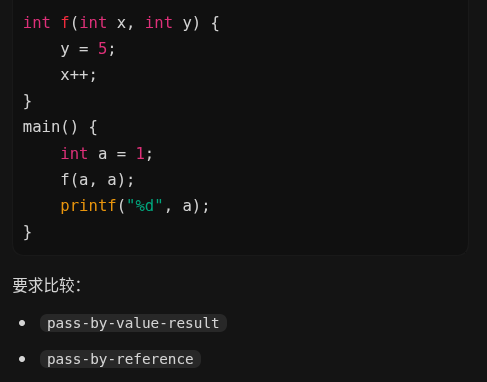
pass-by-reference 含义: 形参不是值拷贝,而是直接引用实参地址 ;
执行过程: 初始:a = 1 y = 5,因为 y 引用 a,所以 a = 5. x++,因为 x 也引用 a,所以 a = 6 输出: 6
pass-by-value-result 含义: 调用时先把实参值拷入形参 返回时再把形参值拷回实参 也叫 copy-in / copy-out
执行过程: 调用前:a = 1 传参后:x = 1 y = 1 函数内:y = 5 , x++,变成 2 此时关键问题来了: x 和 y 最后都要 copy-out 回 a 但它们对应的是同一个实际参数 a . 所以最终结果取决于拷回顺序 如果: 先拷 x 再拷 y,最后 a = 5 , 先拷 y 再拷 x,最后 a = 2 所以标准回答是: 结果不确定,可能是 2,也可能是 5
2020春夏编译原理期末考试 1

这道题的正确答案是 D. pass by name (按名传递)。
延迟求值 (Delayed Evaluation): 这个概念的核心在于“不见兔子不撒鹰”。当调用一个函数时,如果传入的参数是一个表达式(比如
x + 1),程序不会在调用发生的那一瞬间去计算x + 1的结果。相反,它会把这个表达式原封不动地带入函数内部。只有当函数内部的代码真正执行到、需要读取这个参数时,才会触发计算。Pass by name 的机制: 这种参数传递机制(最著名的是在 Algol 60 语言中)完美契合了延迟求值。它的底层行为类似于文本替换(宏替换)。如果参数在函数体内根本没被用到,那它就永远不会被求值;如果被用到了 3 次,它就会被重新求值 3 次。
其余选项 , 它们都属于及早求值 (Eager Evaluation)
2020春夏编译原理期末考试 2

为什么选 C?
局部过程 (local procedures) = 嵌套函数: 当一门语言(如 Pascal, ML, Tiger)允许在一个函数内部定义另一个函数时,内部函数需要访问外部函数的局部变量。
基于栈 (stack-based): 现代语言的函数调用都是基于栈帧(Stack Frame / Activation Record)的。
Access link / Static link 的作用: 正是因为这两种特性的结合,导致运行时栈帧在内存中是动态分布的。为了让内部函数能跨越栈帧找到它“爸爸”(外围函数)的变量,编译器必须在调用时传递一个访问链(Access link/静态链),像绳子一样把相关的栈帧串起来。
2020春夏编译原理期末考试 3

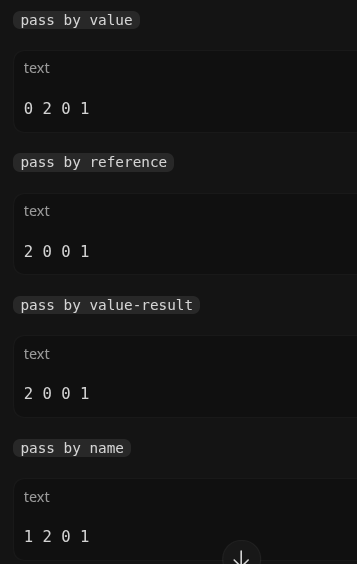
按名传递 (Pass by name) ⚠️ 终极陷阱
按名传递的本质是文本替换(延迟求值)。函数体内的
x和y遇到时,会直接替换为实参表达式 i 和 a[i]。执行 swap(进行文本替换):
i = i + a[i]; a[i] = i - a[i]; i = i - a[i];
Translation to Intermediate Code
https://gemini.google.com/app/d8c5a892768c1d51?hl=zh
复习
https://gemini.google.com/app/d8c5a892768c1d51?hl=zh
while 循环的底层标准结构
在高级语言中,while 循环是一个代码块。但在底层机器码或中间表示(IR)中,没有循环的概念,只有标签(Labels)和跳转(Jumps)。
图片顶部给出了 while 循环被拆解后的标准汇编/IR 布局:
test:(测试标签):循环的起点。if not(condition) goto done:条件判断。如果循环条件为假,立刻跳出循环,去往done标签处。body:如果条件为真,执行循环体内的实际代码。goto test:循环体执行完毕后,无条件跳转回test标签,重新进行条件判断。done:(结束标签):循环结束后的代码继续执行的位置。
如果代码在 body 内部遇到了一个 break 语句,编译器只需要生成一条无条件跳转指令:JUMP to done
for 循环
原始代码:
for i := lo to hi do body改写后的代码: 先定义初始值
i = lo和上限limit = hi。 然后使用while循环:只要 i <= limit,就执行循环体 body,并在最后执行 i := i + 1。极端场景: 假设程序员写的循环上限 hi 正好是计算机能表示的最大整数 (maxint)。
灾难发生: 当循环执行到最后一次(此时 i 等于 maxint),循环体执行完毕后,会执行 i := i + 1。
为了避免这个溢出陷阱,编译器不能把条件判断简单地放在循环开头。正确的做法是重构底层跳转逻辑:
在进入循环之前,先加一个额外的测试:确认 lo <= hi,如果不满足直接跳过整个循环。
将递增条件判断 i < limit 移到循环体的底部,并且必须在执行 i = i + 1 之前进行测试。如果此时 i 已经等于 limit,说明这是最后一次迭代,直接跳出循环,从而彻底避开 maxint + 1 的计算。
函数调用 (FUNCTION CALL) 的翻译机制
把高级语言的函数调用
f(a1, ..., an)翻译成底层的CALL节点看似简单,但有一个核心的隐藏机制:编译器必须悄悄地塞入一个额外的参数。底层 IR 表示:
CALL(NAME lf, [sl, e1, e2, ..., en])解析:
lf是目标函数f的汇编标签(内存地址)。sl(Static Link, 静态链): 这是编译器自动添加的第一个隐藏参数。
为什么需要静态链? 如前几节所述,由于 Tiger(以及 Pascal 等语言)支持嵌套函数,内部函数可能需要访问外部函数的局部变量。这个
sl指针就是用来告诉被调用函数:“你的父级作用域的栈帧基址在哪里”。
历年题
2019机考

在编译器设计中,中间代码(Intermediate Representation, 简称 IR)并不是一种单一的、固定格式的代码,它是一个非常灵活的概念。根据编译阶段的不同,IR 通常被划分为不同的层次:
高层中间代码 (High-level IR, HIR): 这种表示非常接近高级语言源代码。例如抽象语法树(AST)或者带有循环、数组下标等复杂结构的中间表示。它非常适合编译器前端用来做语义分析、类型检查以及独立于机器的高层优化。
低层中间代码 (Low-level IR, LIR): 这种表示则非常接近最终的“目标代码(Target code,即机器码或底层汇编)”。正如我们在前面章节讨论过的,它会将复杂的逻辑彻底拆解为最基础的指令:比如具体的临时虚拟寄存器(
TEMP)、内存基址加偏移量计算(MEM和BINOP)、以及基础的条件跳转(CJUMP)。它非常适合编译器后端用来做指令选择、寄存器分配和针对特定硬件的优化。
实际上,现代的工业级编译器(如 LLVM、GCC 或书中所讲的 Tiger 编译器)在编译程序时,通常会采用多级 IR 的策略。代码会被首先转换成高级 IR,然后再一步步“降级(Lowering)”,最终变成高度类似于目标机器码的低级 IR。
2019机考 2

“三地址代码”(Three-address code, TAC)之所以叫这个名字,是因为它规定一条指令最多包含三个“地址”(即操作数),通常是两个源操作数和一个目的操作数(例如
x = y + z中的x、y、z)。它指的是地址(操作数)的数量限制,而不是字段(Fields)的数量。
在编译器实际的数据结构实现中,三地址代码最标准的表示方法是四元式(Quadruples),它实际上包含 4 个字段:
op:操作符(例如+,-,*,/)arg1:源操作数 1arg2:源操作数 2result:用于存放结果的目的地址
举个例子: 对于代码
a = b + c,它的四元式结构字段划分是:(op: +, arg1: b, arg2: c, result: a)—— 这里明显是四个字段。虽然编译器中也存在“三元式(Triples)”这种为了节省空间而省去
result字段的特殊变体,但笼统地说“三地址代码有三个字段”是完全错误的。四元式具体写法
场景一:基本算术与赋值 a = b * c + d;
先算乘法
b * c,结果存入临时变量t1。 👉(*, b, c, t1)再算加法
t1 + d,结果存入临时变量t2。 👉(+, t1, d, t2)最后把
t2的值赋给真正的变量a。注意,赋值操作不需要第二个操作数,所以arg2留空。 👉(=, t2, -, a)
场景二:一元运算(单目运算) x = -y;
通常用一个特殊的单目减法操作符(比如
@minus或UMINUS)。 👉(@minus, y, -, t1)👉(=, t1, -, x)
场景三:条件判断与跳转(控制流) if (a < b) { x = 1; }
我们需要引入标签(Label)来标记代码位置,比如
L1,L2。判断
a < b,如果为真(True),跳转到标签L1执行赋值。 👉(j<, a, b, L1)(注:j<代表 jump if less than)如果为假,直接跳过赋值,跳到结束标签
L2。 👉(j, -, -, L2)(注:j代表无条件跳转 goto)标签
L1所在的代码(虽然标签本身不写在四元式里,但它是这条指令的目标): 👉(=, 1, -, x)标签
L2(后续代码继续执行)。
场景四:函数调用y = func(a, b);
传递第一个参数。 👉
(param, a, -, -)传递第二个参数。 👉
(param, b, -, -)调用函数
func,并指明有 2 个参数,返回值存入t1。 👉(call, func, 2, t1)将返回值赋给
y。 👉(=, t1, -, y)
Basic Blocks and Traces
https://gemini.google.com/app/1e6a14ad530207ba?hl=zh
规范化树(Canonical Trees)
定义
没有
SEQ或ESEQ节点(这意味着表达式内部不能包含有副作用的语句,所有的语句必须被展平)。每个
CALL节点的父节点必须是EXP(...)或MOVE(TEMP t, ...)。这意味着函数调用(
CALL)不能作为其他表达式的子部分(例如不能写成A + CALL(f))。函数调用的返回值必须立即赋值给一个临时寄存器(MOVE),或者直接丢弃(EXP)。
ESEQ 的转换规则
规则 (1):合并相邻的 ESEQ
公式: ESEQ(s1, ESEQ(s2, e)) => ESEQ(SEQ(s1, s2), e)
解释: 如果一个
ESEQ里面还嵌套着另一个ESEQ,意思是:“先执行语句 s1,再执行语句 s2,最后计算表达式 e”。转换: 我们直接把 s1 和 s2 合并成一个顺序执行块
SEQ(s1, s2),然后计算 e。这消除了嵌套。
规则 (2):ESEQ 在二元操作符的“左子树”
公式: BINOP(op, ESEQ(s, e1), e2) => ESEQ(s, BINOP(op, e1, e2))
解释: 在进行二元运算(比如加法
op)时,左边是一个ESEQ(先执行语句 s,再得到 e1),右边是 e2。转换: 因为表达式的求值顺序通常是从左到右,所以语句 s 本来就应该最先被执行。因此,我们可以非常安全地把 s 直接“拔”到最顶层。变成:“先执行 s,然后再计算 e1 和 e2 的运算结果”。
(图中的 MEM, JUMP, CJUMP 的规则原理相同,都是因为它是第一个被求值的部分,可以直接把内部的 s 提出来。)
规则 (3):ESEQ 在二元操作符的“右子树”(最复杂也最重要的一条)
公式: BINOP(op, e1, ESEQ(s, e2)) 转化为引入新临时变量
t的结构。解释: 这是一个大麻烦。运算顺序要求先计算左边的 e1,然后再处理右边。但是右边包含一个语句 s。如果像规则(2)那样直接把 s 提到最顶层(变成先执行 s,再计算 e1 和 e2),执行顺序就被破坏了! 如果语句 s 修改了表达式 e1 依赖的某个变量,那么 e1 计算出的结果就错了。
转换: 为了保证严格的从左到右的求值顺序,我们必须:
先计算 e1,并把结果强制保存到一个新的临时寄存器 (TEMP t) 中。
然后执行语句 s。
最后用保存好的
t和 e2 进行二元运算。
右侧的树结构: ESEQ(MOVE(TEMP t, e1), ESEQ(s, BINOP(op, TEMP t, e2)))。虽然树变大了,但 s 被成功“提”出了一层。
规则 (4):ESEQ 在“右子树”,但满足“可交换(commute)”条件
公式: 如果语句 s 和 表达式 e1 是独立的(commute),那么 BINOP(op, e1, ESEQ(s, e2)) => ESEQ(s, BINOP(op, e1, e2))
解释: 这是对规则 (3) 的优化。如果编译器能证明“语句 s 绝对不会修改 e1 用到的变量”,并且“e1 的计算也绝对不会影响 s”(它们互不干扰)。
转换: 既然互不干扰,那么 s 和 e1 谁先执行都无所谓。我们就可以省去引入临时寄存器
t的开销,直接像规则 (2) 那样,把 s 提拔到最顶层。
在“天花板”上破裂(ESEQ 转化为 SEQ)
当这 4 条规则不断把
ESEQ往上推时,ESEQ最终会撞到这棵树的“天花板”。什么是天花板?就是树最顶层的语句节点(Statement Node),最常见的就是赋值MOVE或裸表达式语句EXP。当
ESEQ被推到了这些顶层语句节点内部时,就会触发另一组消除规则:情况 1:撞到
MOVE语句公式: MOVE(TEMP t, ESEQ(s, e)) => SEQ(s, MOVE(TEMP t, e))
质变发生: 注意看等号右边!由于
ESEQ已经到了最外层的赋值操作中,我们可以直接把它的副作用s剥离出来,作为最先执行的语句。此时,ESEQ彻底解体,变成了SEQ。
情况 2:撞到裸表达式
EXP语句 (即计算一个表达式,但丢弃它的返回值,通常用于执行独立的函数调用)公式: EXP(ESEQ(s, e)) => SEQ(s, EXP(e))
质变发生: 同样地,副作用
s被提取到了前面,ESEQ消失,转化成了SEQ。
函数调用(CALL)提升到语句的最顶层
1. 核心问题:寄存器覆盖风险
在 IR 树语言中,允许将 CALL 节点作为表达式的一部分(子表达式)。但在真实的机器实现中,所有函数通常都使用同一个固定的寄存器来返回结果(例如名为 RV 的返回值寄存器)。
坏处示例:
如果你有一个加法运算:BINOP(PLUS, CALL(f), CALL(g))
执行
CALL(f),结果存入RV。紧接着执行
CALL(g),结果也存入RV。问题: g 的返回值会把 f 的返回值给覆盖掉,导致
PLUS运算时拿不到正确的第一个参数。
2. 解决方案:重写规则 (image_f1edd0.png)
为了解决这个问题,编译器引入了一条重写规则,强制将每个调用的返回值立即“抢救”出来,存入一个新的临时变量中:
CALL(fun,args)→ESEQ(MOVE(TEMP t,CALL(fun,args)),TEMP t)
动作: 先执行函数调用并把结果
MOVE到一个新的临时寄存器t中。结果: 表达式最后返回这个
t。提升: 配合我们之前讨论的
ESEQ消除器,这个MOVE语句会被“拔”到最顶层,从而避开了多个调用挤在同一个表达式里的冲突。
现在 , CALL 的父结点只能是:EXP(CALL(...)) [丢弃返回值] / MOVE(TEMP t, CALL(...))
将处理后的 IR 树转换为线性的语句列表
消除树的层级结构
虽然经过之前的处理,
SEQ节点已经处于树的顶端,但它们可能仍然以嵌套的形式存在(例如左子树也是一个SEQ)。线性化的目标是让所有的语句 s1,s2,…,sn 按顺序排成一列,而SEQ节点仅仅充当连接它们的“链条”。关键重写规则:右结合变换
为了达到线性化的目的,
linearize函数反复应用结合律规则:SEQ(SEQ(a,b),c) = SEQ(a,seq(b,c))
原理:这个规则将原本向左倾斜或平衡的树结构,统一转换为向右倾斜的结构。
结果:最终整棵树会变成如下形式:
SEQ(s1,SEQ(s2,…,SEQ(sn−1,sn)…))
这种结构在逻辑上等价于一个简单的列表:s1,s2,…,sn 其中每个 si 都不再包含
SEQ或ESEQseq 最后被直接抛弃, 成为线性化
驯服条件分支
在编译器内部使用的“树语言”(Tree language)中,
CJUMP指令非常“豪华”:它有两个目标标签(lt 和 lf),分别对应条件为真和为假时的跳转去向。现实困境:真实的物理 CPU 指令集通常没这么慷慨。真实的条件跳转指令往往只有一种逻辑:如果条件成立,跳转到目标地址;如果条件不成立,则“掉入”(Falls through)执行紧随其后的下一条指令。
解决方案:为了让生成的代码符合硬件逻辑,编译器需要重新排列指令,确保每一个 CJUMP(cond, l_t, l_f) 后面紧跟着的就是它的“假分支”标签 LABEL(l_f)。这样,如果条件不成立,程序自然而然地就执行到了 lf 指向的代码。
基本块划分算法
该算法通过从头到尾扫描指令序列来识别块的边界:
扫描方式:从序列的开始处扫描到结束。
识别起点:每当遇到一个 LABEL(标签)时,就开始一个新块,同时结束前一个块。
识别终点:每当遇到 JUMP(无条件跳转)或 CJUMP(条件跳转)时,当前块结束,并开始下一个新块。
为了保证每个块都严格遵守基本块的定义,算法会进行以下修正:
补全跳转:如果某个块结束时没有
JUMP或CJUMP(即直接“掉入”下一个块),算法会在该块末尾添加一个指向下一个块标签的JUMP指令。补全标签:如果某个块的开头没有
LABEL,算法会虚构(invent)一个新标签并放置在开头。
在处理函数体时,通常会遇到函数结束后的“收尾”代码(Epilogue,负责弹出栈帧并返回调用者):
逻辑位置:收尾代码不属于函数体块的一部分,但紧随其后。
保持一致性:为了避免最后一个块成为没有
JUMP的“特殊案例”,编译器会虚构一个名为done的标签(代表收尾代码的开始)。强制结束:在函数体的最后一个块末尾添加一条 JUMP(NAME done),使其符合基本块必须以跳转结尾的规则。
追踪调度(Trace Scheduling)
什么是“追踪”(Traces)?
虽然每个基本块都以跳转结尾,理论上可以按任意顺序排列,但不同的排列方式执行效率大不相同。
核心目标:
优化
CJUMP:确保每个条件跳转后面紧跟着它的 false 标签。这样当条件为假时,处理器可以直接“掉入”(Fall through)下一行,无需执行跳转指令。消除
JUMP:让无条件跳转的目标紧跟其后,这样这条 JUMP 指令就可以被完全删掉,提升运行速度。
定义: 追踪是一个可以在程序执行期间连续执行的语句序列。一个程序可以有很多重叠的追踪,但我们的目标是用一组最少的追踪来覆盖整个程序,确保每个块恰好出现在一个追踪里。
追踪生成算法(第一步)

条件跳转(CJUMP)的最终调整(第二步)
在真实的物理机器上,条件跳转指令通常只有“满足则跳转,不满足则掉入(Fall-through)下一条指令”的特性。为了匹配这种硬件逻辑,必须确保
CJUMP后面紧跟着它的false标签。针对
CJUMP(cond, a, b, l_t, l_f),图片中列出了三种处理情况:情况 A:紧跟 lf(理想情况)
如果
CJUMP后面直接就是它的原始假标签 lf,则不需要做任何改动。情况 B:紧跟 lt(取反逻辑)
如果后面紧跟的是真标签 lt,编译器会反转判定条件并交换真假标签。
例如:
CJUMP(>, i, N, done, body)后面跟着LABEL(done),会重写为CJUMP(<=, i, N, body, done)。
情况 C:两段都不紧跟(引入跳转)
如果后面既不是 lt 也不是 lf,则需要发明一个新标签 lf′,并按如下方式重写:
CJUMP(cond,a,b,lt,lf′)
LABEL lf′
JUMP(NAME lf)
这样做是为了强制制造一个“掉入”环境,再通过一个额外的无条件跳转导向原本的假分支。
历年题
23-24小题 1

根据上述规则 2 和规则 3,每一个基本块的末尾都必须有且仅有一条跳转指令。也就是说,代码中基本块的总数 = JUMP 指令的数量 + CJUMP 指令的数量。
求最小值:题目已知有 k 个 CJUMP 指令。要求出基本块的最少数量,我们只需假设这段代码中没有任何无条件跳转指令(即 JUMP 数量为 0)。
得出结论:当 JUMP 数量为 0 时,基本块的总数 = 0 + k = k。
eg
24期末1

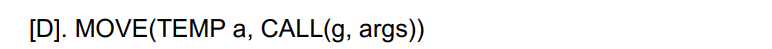

如何将 A, B, C 化为规范树?
选项 [A]
ESEQ(MOVE(MEM(TEMP fp), 10), MEM(TEMP fp))违规原因:包含了
ESEQ节点。如何规范化:这通常出现在一个顶层语句的上下文中,比如我们把它放在一个
EXP里,或者把它赋值给某个寄存器。情况 1(作为独立语句丢弃返回值):如果我们用
EXP包装它,即EXP(ESEQ(s, e)),根据规则会变成SEQ(s, EXP(e))。在这里也就是:SEQ(MOVE(MEM(TEMP fp), 10), EXP(MEM(TEMP fp)))然后通过
linearize展平成列表:Plaintext
MOVE(MEM(TEMP fp), 10) EXP(MEM(TEMP fp))情况 2(赋值给新变量 $t$):如果是
MOVE(TEMP t, ESEQ(s, e)),会变成SEQ(s, MOVE(TEMP t, e)):Plaintext
MOVE(MEM(TEMP fp), 10) MOVE(TEMP t, MEM(TEMP fp))(注意:规范化后的结果是一组语句列表,而不是单一的一棵树。)
选项 [B]
MOVE(MEM(CALL(f, args)), TEMP a)违规原因:
CALL节点的父节点是MEM,违反了CALL必须位于顶层的铁律。如何规范化:需要引入临时变量来“抢救”
CALL的返回值,然后再执行内存写入。应用 CALL 规则:将
CALL替换为 ESEQ(MOVE(TEMP t, CALL(...)), TEMP t)。 原式变为:MOVE(MEM(ESEQ(MOVE(TEMP t, CALL(f, args)), TEMP t)), TEMP a)从
MEM中提取ESEQ(Figure 8.1 规则 2): MOVE(ESEQ(MOVE(TEMP t, CALL(f, args)), MEM(TEMP t)), TEMP a)从
MOVE的目标地址提取ESEQ(do_stm 规则):SEQ(MOVE(TEMP t, CALL(f, args)), MOVE(MEM(TEMP t), TEMP a))线性化为语句列表:
Plaintext
MOVE(TEMP t, CALL(f, args)) MOVE(MEM(TEMP t), TEMP a)
25期末

B 是对的
Instruction Selection
https://gemini.google.com/app/5f75f8d805b8bf77?hl=zh
复习
1. 核心思想:树模式与平铺 (Tree Patterns & Tiling)
IR 树: 编译器在前端把源代码转换成了抽象的树状中间表示(IR),树上的每个节点代表非常基础的操作(如加法、内存读取)。
树模式(拼图块): 目标机器的每一条指令,都可以看作是一小块“树模式(Tile)”。复杂的指令对应的拼图块很大(能涵盖多个节点),简单的指令对应的拼图块很小。
平铺(Tiling): 指令选择的过程,就是用这套“指令拼图”,把庞大的 IR 树严丝合缝地、无重叠地完全覆盖起来。
2. 评判标准:最优解的定义
对于同一棵树,往往有多种拼图方案,编译器通过给指令赋予“成本(Cost)”来评估好坏:
全局最优: 所有拼图块的成本总和绝对最低。
局部极优: 拼图方案处于稳定状态,找不到任何相邻的拼图块可以合并成一个更便宜的大拼图块。
架构差异: 对于 RISC(精简指令集),指令成本均匀,局部极优往往就是全局最优;而对于 CISC(复杂指令集),由于指令威力差异大,必须努力寻找全局最优。
3. 两大核心算法:如何去拼图?
这是本章最重要的实战算法:
最大吞噬算法 (Maximal Munch):
策略: 自顶向下(Top-down)的贪心算法。
做法: 从树根开始,每次都试图匹配能盖住最多节点的最大拼图。然后对剩下的未覆盖子树递归执行。
特点: 简单、极快,通常能找到局部极优(a local Optimum)解。由于它是从树根开始匹配的,所以指令在代码中是逆序生成的。
动态规划算法 (Dynamic Programming):
策略: 自底向上(Bottom-up)的全局搜索。
做法: 分两步。第一步从叶子节点往上算,算出每个节点如果采用各种匹配方案的最小成本,并记录下来;第二步从树根往下,顺着记录的最优路径发射(Emit)指令。
特点: 复杂一些,但保证能找到全局最优(Optimal solution)解。由于大拼图会“吞噬”内部节点,被吞噬的节点在第二步会被直接跳过。
动态规划(Dynamic Programming)
阶段一:自底向上的成本计算 (Cost Calculation)

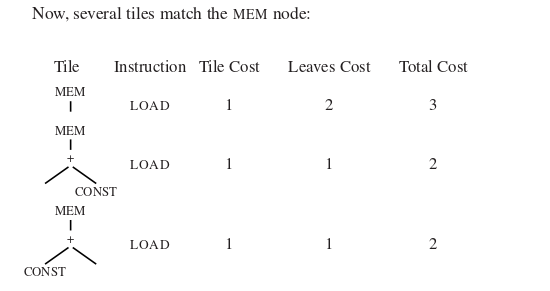
阶段二:指令发射 (Instruction Emission)
算出成本后,第二步就是真正生成汇编代码。这部分是自顶向下(Top-down)进行的(对应第二张图下半部分和第三张图)。
核心发射规则: 算法从根节点开始看起,采用之前记录的最优拼图。然后,算法只会递归进入该拼图暴露出来的“叶子”节点,而不会进入被拼图“吞噬”的内部节点。
实战演示:
处理根节点 (
MEM): 算法选择方案 2 的超级大拼图(包含了MEM,+和CONST 2)。这条对应的指令是LOAD r_i <- M[r_j + 2]。因为这个大拼图只在左下角露出了一个叶子(CONST 1),所以算法接下来只去递归处理CONST 1。处理叶子 (
CONST 1): 匹配ADDI拼图,生成指令ADDI r1 <- r0 + 1。回归根节点: 叶子处理完了,现在把根节点的大指令发射出来,即
LOAD r1 <- M[r1 + 2]。
树语法
1. 为什么需要树语法?(痛点分析)
在简单的处理器(如纯 RISC)中,所有的寄存器都是一视同仁的。但在真实的、复杂的处理器(如 x86 系列或 Motorola 68k)中,寄存器是分三六九等的。
有些专门用来算数(数据寄存器,记为 dd)。
有些专门用来存放内存地址(地址寄存器,记为 aa)。
甚至还有专门的浮点寄存器、向量寄存器。
如果一条内存读取指令严格要求:“必须用地址寄存器作为基址,读出的结果必须放进数据寄存器”,以前那种粗放的“最大吞噬算法”就很难处理了,因为它无法在匹配时动态追踪数据到底放在哪种类型的寄存器里。
2. 树语法的精妙映射
为了解决这个问题,编译器设计者巧妙地借用了语法分析的理论。在树语法中:
终结符(Terminals): 对应着你 IR 树上那些具体的节点,比如相加 PLUSPLUS、内存 MEMMEM、常数 CONSTCONST。它们是原材料。
非终结符(Non-terminals): 对应着数据最终存放的位置或状态。比如 aa 代表“存在地址寄存器里的值”,dd 代表“存在数据寄存器里的值”。
推导规则(Production Rules): 每一条规则,就等价于目标机器上的一条机器指令!
3. 硬核图解:规则就是指令
让我们看几条典型的树语法规则,看看它们是如何与真实的机器指令对应的:
规则 1: d→MEM(+(a,CONST))
翻译: 如果你有一个地址寄存器 a 和一个常数 CONST,把它们相加,去读取内存 MEMMEM,最后你会得到一个放在数据寄存器 dd 里的结果。
对应的真实指令: 这就是一条标准的、带偏移量的内存加载指令,比如
LOAD d_i <- M[a_j + offset]。
规则 2: d→+(d,d)
翻译: 两个数据寄存器里的值相加,结果仍然存放在数据寄存器中。
对应的真实指令: 基础算术指令,如
ADD d_k <- d_i + d_j。
规则 3: a→d
翻译: 数据寄存器的值,可以变成地址寄存器的值。
对应的真实指令: 寄存器之间的数据移动指令,如
MOVED a_i <- d_j。
4. 化缺点为优点的“高度歧义性”
如果你学过编译前端,老师一定会告诉你:文法有“歧义(Ambiguity)”是万恶之源,这意味着代码意思不明确。
但在后端的树语法中,歧义是一件天大的好事! 一棵复杂的 IR 树,按照这套树语法,通常可以推导出几十甚至上百种不同的匹配路径。这种“歧义”,在物理世界中代表的就是“实现相同代码逻辑的不同机器指令组合”。
既然有这么多选择,编译器怎么选?这就轮到动态规划(Dynamic Programming)出场了。 我们在写树语法规则时,会给每一条规则(指令)标上一个成本(Cost)(比如执行所需的时钟周期)。编译器会在树的每个节点上,为每个非终结符(如 a 或 d)穷举所有可能匹配的规则,累加成本,最终在树的根节点挑出一条总成本最低的推导路径。这就是生成最优机器码的过程。
历年题
24期末.pdf
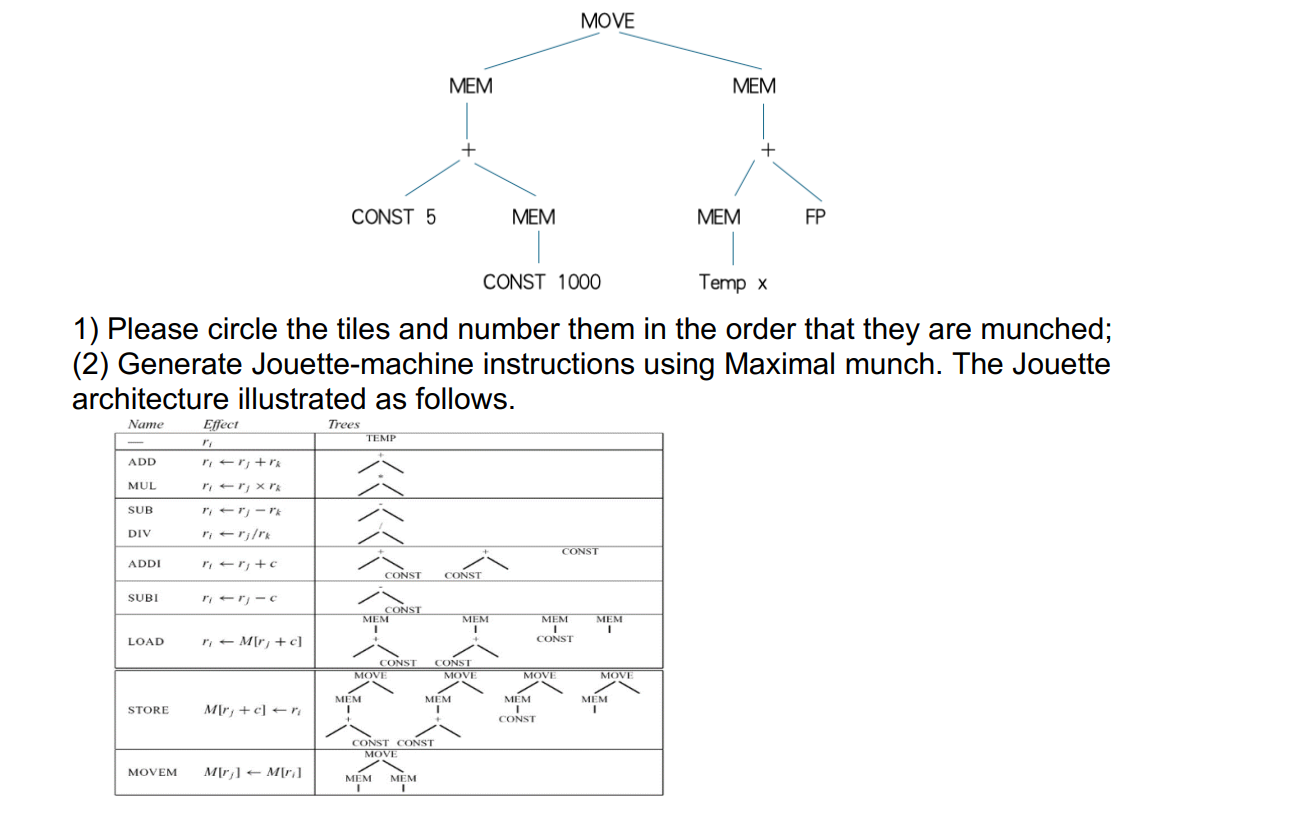
第一部分:划分拼图 (Tiles) 与吞噬顺序 (Munch Order)
由于我无法直接在图片上画圈,我将详细描述每次“吞噬”覆盖了哪些节点,以及它们的执行顺序。
注意:TEMP x 和 FP (帧指针) 本身就代表寄存器,它们是叶子节点,不需要单独的指令来生成它们。
1. Munch 1 (第一次吞噬):根节点
当前子树: 整棵树,根节点为
MOVE。匹配分析: * 乍一看,左右孩子都是
MEM,很容易让人联想到MOVEM指令(树模式为MOVE(MEM, MEM),包含 3 个节点)。但是,再仔细看左子树:
MEM下面是+,+的左边是CONST 5。这完美匹配了STORE指令的一种复杂寻址模式:MOVE(MEM(+(CONST, reg)), reg)。这个模式包含了 4 个节点 (MOVE,MEM,+,CONST)。根据最大吞噬原则(4 > 3),算法会选择
STORE。
覆盖的节点: 顶部的
MOVE,左侧的MEM,左侧的+,以及CONST 5。剩余待吞噬的子树: 左侧留下了
MEM(CONST 1000);右侧留下了整棵MEM(+(MEM(Temp x), FP))。
2. Munch 2 (第二次吞噬):左侧剩余部分
当前子树:
MEM(CONST 1000)匹配分析: 匹配
LOAD指令的直接内存地址模式MEM(CONST)。覆盖的节点: 左下角的
MEM和CONST 1000。剩余: 左侧分支完全处理完毕。
3. Munch 3 (第三次吞噬):右侧剩余部分顶部
当前子树:
MEM(+(MEM(Temp x), FP))匹配分析: 根是
MEM,孩子是+。Jouette 的LOAD指令有MEM(+(reg, CONST))模式,但这里的+孩子是MEM和FP(两个都是寄存器,没有常数)。因此,它无法匹配复杂的LOAD模式,只能退而求其次匹配最基础的LOAD模式:MEM(reg)。覆盖的节点: 右侧最顶部的
MEM。剩余待吞噬的子树:
+(MEM(Temp x), FP)。
4. Munch 4 (第四次吞噬):右侧加法
当前子树:
+(MEM(Temp x), FP)匹配分析: 匹配基础的
ADD指令模式+(reg, reg)。覆盖的节点: 右侧的
+。剩余待吞噬的子树:
MEM(Temp x)。
5. Munch 5 (第五次吞噬):右侧底部
当前子树:
MEM(Temp x)匹配分析:
Temp x已经在寄存器中,匹配基础的LOAD指令模式MEM(reg)。覆盖的节点: 右侧底部的
MEM。剩余: 全部处理完毕(
Temp x和FP直接作为寄存器操作数使用)。
第二部分:生成 Jouette 机器指令
最大吞噬算法在生成指令时,采用的是逆序生成(自底向上),因为根节点的操作必须等待所有子节点计算完毕后才能执行。
我们将按照上面分析的 Munch 顺序的倒序(5 -> 4 -> 3 -> 2 -> 1)来发射(Emit)汇编指令。
假设我们分配以下寄存器存放中间结果:r1,r2,r3,r4r1,r2,r3,r4。假设
Temp x位于寄存器 rxrx,帧指针FP位于寄存器 fpfp。代码段
; 从 Munch 5 生成 (处理最底层的变量读取) LOAD r1 <- M[rx + 0] ; 匹配: LOAD(MEM(Temp x)),注意这里简写为 M[rx] ; 从 Munch 4 生成 (处理地址相加) ADD r2 <- r1 + fp ; 匹配: ADD(+(reg, FP)) ; 从 Munch 3 生成 (读取右侧内存值) LOAD r3 <- M[r2 + 0] ; 匹配: LOAD(MEM(reg)) ; 从 Munch 2 生成 (读取左侧内存值,这两步叶子节点的顺序可以互换) LOAD r4 <- M[1000] ; 匹配: LOAD(MEM(CONST 1000)) ; 从 Munch 1 生成 (最终的写入操作,利用了带常数偏移量的 STORE) STORE M[r4 + 5] <- r3 ; 匹配: STORE(MOVE(MEM(+(CONST 5, reg)), reg))
IR是前端还是后端生成
在编译器(如 LLVM、GCC)的经典架构中,IR(Intermediate Representation,中间表示)是由编译器的前端(Frontend)生成的。
为了更清晰地理解这个过程,我们可以把现代编译器的“三段式”流水线拆开来看:
1. 前端(Frontend):生成 IR
前端负责“读懂”程序员写的源代码(如 C、C++、Rust、Swift 等)。
主要工作:进行词法分析、语法分析和语义分析。它会检查你的代码有没有语法或类型错误。
最终产出:一旦确认代码合法,前端就会将源代码翻译成 IR 并交接给下一环。
2. 中端(Middle-end / Optimizer):优化 IR
中端(也叫优化器)专门负责“打磨”代码,它的输入和输出都是 IR。
主要工作:接收前端生成的原始 IR,对其进行一系列与具体硬件无关的优化(例如删除永远不会执行的死代码、提前计算好常量结果、展开循环等)。
最终产出:执行效率更高、逻辑更精简的优化后 IR。
3. 后端(Backend):消耗 IR,生成机器码
后端负责和底层的物理硬件打交道。
主要工作:接收优化后的 IR,结合目标硬件的特性(比如寄存器数量、指令集),将其翻译成特定 CPU 架构(如 x86、ARM、RISC-V)能直接执行的机器码或汇编指令。
Liveness Analysis
https://gemini.google.com/app/ff302bc9d337b808?hl=zh

第二条,仅不能给 ac 连线, out里的内容可以和a连线
复习
数据流方程

从“集合”提炼出“冲突图 (Interference Graph)”
编译器会遍历我们之前算出的所有
out集合。如果发现变量
A和变量B同时出现在了某一行代码的out集合里,就说明它们“同时存活”,发生了冲突(Interference)。把所有的变量画成圆圈(图的节点),把有冲突的变量之间连上一条线(图的边)。这张图就叫冲突图。
保守的近似与静态活跃性
既然数学定律封死了完美预测的可能,编译器要怎么做活跃变量分析呢?答案就是彻底放弃完美,选择退而求其次。书里明确区分了两个概念:
动态活跃(Dynamic liveness):
定义:在程序真正运行时,如果控制流真的走到了一处需要使用变量 a 的地方,那 a 才是动态活跃的。
现实:由于停机问题,这在数学上是不可计算的(cannot be computed)。
静态活跃(Static liveness):
定义:只要我们在程序的控制流图(图纸)上,能找到一条画着箭头的路径通向变量 a 被使用的地方,我们就当它是活跃的。我们完全不去管现实运行中,这条路上的
if/else到底走不走得通。现实:这很容易计算。优化型编译器(Optimizing compiler)必须基于这种静态信息来分配寄存器。
MOVE(数据拷贝/赋值)指令进行“网开一面”的特殊优化
规则 1:对待普通指令(Nonmove instruction)
如果是像加减乘除这样的普通运算定义了变量 a(比如 a:=x+y)。那么没得商量,此时只要有哪些变量(b1,b2...)是活着出来的(live-out),就给 a 和它们一一连上冲突线。
规则 2:对待 MOVE 指令的特权(Move instruction)
如果是拷贝指令 a←c。此时虽然很多变量活着出来,但你在给 a 连冲突线时,必须跳过 c。也就是说,即使 c 此时是活的,也绝对不给 a 和 c 之间连线。
数据流方程和“一直循环直到不变为止”的算法
方程只规定了必须满足的约束条件(比如:如果你这步用了变量,它之前就必须活着)。
正如我们在前面看到的,满足这套规则的解不止一个。
解 X:最完美的真实情况。
解 Y:混入了一个根本不存在的垃圾变量 d。虽然荒谬,但在数学上它依然满足方程的规则,所以它也是方程的解。
算法的结果 = 最小解 / 最小不动点 (Least Fixed Point)
这正是这个算法最伟大的地方,也是书里最后特别强调的定理:
因为 Algorithm 10.4 的第一步是把所有的活跃集合初始化为空集 {},然后在循环中只添加绝对必要的数据。这就好比一个极其吝啬的侦探,只有在证据确凿时才承认某个变量是活的。
因此,数学上可以严格证明:这个算法一旦停下来(不再变化),它输出的结果永远是方程所有解当中“最小、最干净”的那一个(即最完美的解 X)。它绝对不会算出包含垃圾变量的解 Y。
Register Allocation
https://gemini.google.com/app/2fad901dade0997a?hl=zh
复习
“通过简化进行着色(Coloring by Simplification)”的启发式算法
1. 构建 (Build)
目标:建立冲突图(Interference Graph)。
过程:编译器使用数据流分析来找出在程序的每个时间点上,哪些临时变量是同时活跃的。如果两个临时变量在同一时刻都处于活跃状态,它们就不能共享同一个物理寄存器。此时,算法会在冲突图中的这两个变量节点之间画一条边,表示它们存在“冲突”。
2. 简化 (Simplify)
这是整个算法的核心启发式思想,基于一个非常巧妙的数学逻辑:
核心逻辑:假设目标机器有 K 个物理寄存器。如果图中的某个节点 m 的相邻节点数量(在图论中称为“度”,degree)少于 K,那么我们就可以安全地把节点 m 从图中暂时移除。
为什么安全? 因为即使节点 m 的所有邻居在后续都被分配了完全不同的颜色(寄存器),它们最多也只会占用 K−1 种颜色。这意味着当我们稍后把节点 m 加回图中时,总会剩下至少一种空闲的颜色(寄存器)可以分配给它。
操作步骤:
在图中寻找度数小于 K 的节点。
将其从图中移除,并压入一个栈(Stack)中保存。
由于该节点被移除,与之相连的边的其他节点的度数也会相应减少。
这可能会导致原本度数大于等于 K 的节点,其度数现在降到了小于 K,从而暴露出更多可以被简化的节点。算法会不断循环这个过程,直到图中没有节点为止。
3. 溢出 (Spill)
触发条件:在简化过程中,如果图中的所有剩余节点的度数都大于或等于 K,简化过程就会卡壳。这意味着当前的物理寄存器极有可能不够用了。
应对策略:算法会挑选其中一个节点标记为“溢出节点”。这意味着在程序运行时,这个变量的值将被存放在内存中,而不是寄存器中。
继续简化:算法采用一种乐观的近似方法——假设这个溢出节点不再与图中的其他任何节点产生冲突。因此,它同样会被从图中移除并压入栈中,从而打破僵局,让简化(Simplify)过程得以继续进行。
4. 选择与着色 (Select)
在这个阶段,图着色(分配寄存器)才真正开始。
重建图:算法从一个空图开始,把在 Simplify 和 Spill 阶段压入栈(Stack)中的节点,从栈顶一个个弹出来,重新放回图中,并恢复它们原有的连线。
正常着色:对于在 Simplify 阶段(因为度数 <K)被正常入栈的节点,每次把它弹出来放回图里时,它一定能找到一个可用的颜色。这是因为即使它所有的邻居都已经被着色,邻居们最多也只会占用 K−1 种颜色,总会剩下至少一种空闲的颜色(也就是寄存器)留给它。
乐观着色 (Optimistic Coloring):当从栈中弹出一个当时被迫使用 Spill 策略(度数 ≥K)压入的“潜在溢出节点”时,奇迹可能会发生。虽然它有很多邻居,但它的邻居们可能被分配了相同的颜色。只要它现有的邻居使用的颜色总数 <K,这个原本以为要溢出的节点,依然可以成功分配到颜色!这种“尽人事听天命”的技巧在编译原理中被称为乐观着色。
实际溢出 (Actual Spill):当然,如果这个“潜在溢出节点”被弹出来时,发现它的邻居们恰好把 K 种颜色全占满了,那它就真的无路可走了。此时它被确认为“实际溢出”,不分配颜色,并且算法会继续去弹出栈里的其他节点,找出所有实际溢出的节点。
5. 重头再来 (Start over)
如果在 Select 阶段发现了任何“实际溢出”的节点,说明现有的代码结构超出了物理硬件的承受能力,必须进行修改。
重写代码:编译器会重写程序,把那些溢出的变量存放在主内存中。每次要用这个变量时,先从内存把它读取到一个全新的临时变量中(极其短暂的生命周期);一旦用完,立刻存回内存。
拆分生命周期:通过这种重写,原本一个生命周期很长、到处冲突的变量,被“粉碎”成了好几个生命周期极短的新临时变量。这些新变量与其他变量的冲突概率会大幅降低。
重新迭代:因为程序图(冲突图)已经改变,算法必须拿着重写后的代码重新开始第一步(Build -> Simplify -> Spill -> Select)。
收敛性:虽然听起来是个死循环,但在实际工程中,通常只需要重新迭代一到两次,图就会变得足够简单,最终成功完成 0 溢出的完美着色。
合并的基础概念
消灭 MOVE 指令:如果在程序中有一条指令
a := b(把 b 的值赋给 a),并且在冲突图中,节点a和节点b之间没有连线(即它们不会在同一时刻同时活跃,没有冲突),那么我们就完全可以让a和b共享同一个物理寄存器。合并节点:在图中,这表现为将
a和b两个节点“揉”成一个新的超级节点ab。这个新节点ab的连线(邻居),包含了原来a和b的所有连线(即边的并集)。收益:一旦它们被分配到同一个寄存器,这条
a := b的指令就变成了“自己把值赋给自己”,编译器就可以安全地将这条冗余指令直接删除,从而让程序跑得更快。
交替循环引擎 (Interleaving)
流程图 FIGURE 11.4 展示了完整的寄存器分配生命周期。你会注意到 simplify 和 coalesce 之间出现了一个来回循环的箭头。这正是现代寄存器分配的核心技巧——交替执行。
让我们看看加入“合并”功能后,前三个阶段发生了什么变化:
构建 (Build):
在建立冲突图时,编译器现在会给所有节点打上两种标签:
与 MOVE 相关的 (move-related):这个变量是一条
MOVE指令的发送方或接收方。与 MOVE 无关的 (non-move-related):普通的计算变量。
简化 (Simplify):
规则发生了重要改变!现在,即使一个节点的度数 <K,但如果它是与 MOVE 相关的,你就不能把它移除。简化阶段现在只允许移除那些度数 <K 且与 MOVE 无关的节点。
原因:一旦你把它移除了,你就失去了后续把它和别的节点“合并”以消除
MOVE指令的机会。合并 (Coalesce):
当“简化”阶段把所有能移的无关节点都移走后,图变得更小了,很多保留下来的节点的度数也随之降低了。此时再执行保守合并(Briggs 或 George),成功率会大幅提升。
循环的魔力:如果两个节点成功合并,并且消除了一条
MOVE指令,这个新生成的合并节点可能就不再连接任何其他的MOVE指令了。这就意味着,它从“与 MOVE 相关”变成了“与 MOVE 无关”。重返简化:这个新出炉的“无关节点”如果度数依然 <K,它就可以被送回 Simplify 阶段去处理。
打破僵局的应急机制:Freeze 与 Spill
在理想状态下,编译器会在“简化(Simplify)”和“合并(Coalesce)”之间愉快地来回循环。但现实中,图纸经常会卡在一个既找不到度数 <K 的无关节点,又找不到安全合并机会的尴尬状态。这时就需要引入图片顶部的两种机制:
冻结 (Freeze):
触发场景:图中还有度数 <K 的节点,但它们都是“与 MOVE 相关的”(即身上连着虚线),所以不能被简化;同时,由于保守策略的限制,它们当前也无法被安全合并。
处理方式:既然合并不了,那就算了!编译器会选择其中一个节点,放弃(冻结)它身上相连的 MOVE 指令。
结果:一旦放弃合并,这个节点身上的虚线就被抹除了,它瞬间变成了一个“与 MOVE 无关”的普通低度数节点。这样一来,它立刻就能被送进“简化(Simplify)”阶段进行处理,算法的死局就被打破了。
溢出 (Spill):
触发场景:图里连度数 <K 的节点都没有了(不管相关还是无关),全都是度数≥K 的高度数节点。
处理方式:和我们之前讨论的一样,别无选择,只能挑选一个节点标记为“潜在溢出节点”,并强行压入栈中,以继续简化流程。
溢出的代价:重头再来 (Spilling)
之前我们提到,如果遇到实在分配不开的高度数节点,算法不得不选择一个节点“溢出(Spill)”到内存中,并重写代码。图片最后一段解释了溢出发生后,算法该如何收场。
一旦发生溢出,说明之前的图纸彻底作废了,编译器必须拿着重写后的代码重新执行“构建(Build)”和“简化(Simplify)”阶段。那么,之前辛辛苦苦做好的那些“合并”操作该怎么办呢?
编译器有两种策略:
简单粗暴版(The simplest version):只要发生重试,就把之前找出的所有合并操作全部作废。大家全部变回独立的变量,从零开始重新算。这能绝对保证之前的合并不会给新的图增加复杂度(导致更多的溢出)。
高效优化版(A more efficient algorithm):这是一种更聪明的做法。它会保留那些在“发现潜在溢出节点之前”就已经完成的合并(因为这些合并已经被证明是安全的);但是,会撤销掉在“发现潜在溢出节点之后”做的任何合并操作。这样既保证了安全,又节省了重复计算的时间。
溢出节点的合并(Coalescing of spills)
1. 痛点:溢出带来的内存与性能灾难
栈帧膨胀:在寄存器很少的机器上(比如只有 6 个通用寄存器的早期 Intel Pentium),会产生大量的溢出变量。如果每个溢出变量都在内存的“栈帧(Stack Frame)”里独占一个位置,栈帧就会变得极其庞大。
致命的内存 MOVE:更糟糕的是,如果代码中有一条在两个溢出变量之间赋值的指令(例如 a←b),因为 CPU 通常不能直接把数据从一个内存地址搬到另一个内存地址,编译器必须生成一段“加载-存储(fetch-store)”序列:
先读入临时寄存器:t←M[aloc]
再写回目标内存:M[bloc]←t
恶性循环:这个过程不仅运行速度慢,而且还凭空产生了一个新的临时变量 t!这个 t 又需要占用物理寄存器,可能会导致图变得更复杂,引发更多变量溢出。
2. 破局之道:把内存当作“无限的寄存器”
计算机科学家们发现了一个盲点:很多溢出变量在程序运行的不同阶段并不会同时活跃(即没有冲突)。
既然没有冲突,为什么不让它们共享同一个内存地址(栈帧位置)呢?
这实际上就是把我们之前用的“图着色与合并”算法,原封不动地应用到了内存分配上!
最爽的一点是:物理寄存器数量 K 是固定的(比如 4 个、6 个),但内存地址几乎是无限的。因为没有了 K 的限制,我们再也不需要使用保守的 Briggs 或 George 规则了,我们可以进行激进合并(Aggressive Coalescing)!
3. 溢出节点的合并算法 (四步曲)
编译器在处理溢出变量时,会执行以下专门的算法:
构建局部冲突图:利用存活期信息,专门为这些“溢出节点”画一个冲突图。
激进合并:只要两个溢出节点之间有
MOVE指令相连,且它们之间没有冲突连线,不用管它们邻居的度数有多高,闭着眼睛直接合并!这样就能无损地删掉大量拖慢速度的内存 MOVE 指令。无限着色:使用
simplify(简化)和select(选择)阶段来为这个图着色。在这个阶段:绝对不会发生二次溢出,因为“颜色”数量没有限制。
简化阶段只需每次挑出度数最低的节点即可。
着色阶段,每次给弹出的节点分配当前最小的可用颜色数字(例如颜色 1, 2, 3…)。
映射到内存:最后分配的这些“颜色”,对应的不再是物理寄存器,而是栈帧(活动记录)中的具体内存槽位(Slots)。颜色 1 就是一号槽位,颜色 2 就是二号槽位。
预着色节点(Precolored Nodes)
1. 什么是预着色节点?
物理化身:预着色节点不是普通的临时变量,它们代表的是真实的、特定的机器物理寄存器。
特定用途:在不同模块间互相调用函数时,操作系统有严格的“调用约定(Calling Conventions)”。例如,规定必须用 1 号和 2 号寄存器传参数,用特定的寄存器作为栈帧指针(Frame Pointer)。前端编译器在生成代码时,会直接生成这些预定好的节点。
天生带色:正如其名,它们在图构建之初就已经有了固定的“颜色”(即绑定了特定的物理寄存器),并且每种颜色只能有一个预着色节点。
2. 与普通节点的“和平共处”
重复利用:一个普通的临时变量,只要在生命周期上与某个预着色节点不冲突(没有连线),在 Select 着色阶段,它完全可以被分配与预着色节点相同的颜色。这意味着特定的物理寄存器在完成传参等特殊任务后,可以被当成普通寄存器重复利用。
支持合并:普通节点也可以通过保守合并策略(如 Briggs 或 George 规则)安全地合并到预着色节点中,从而消除变量和硬件寄存器之间的数据拷贝(MOVE 指令)。
3. K个节点的“互斥小团体”
全连接图:如果目标机器有 K 个寄存器,那么图中必定存在 K 个预着色节点。因为物理硬件之间是绝对独立的(1 号寄存器永远不可能变成 2 号寄存器),所以这 K 个节点彼此之间全部互相冲突(互相有连线)。
与普通节点的冲突:如果某个预着色寄存器(如传参寄存器)在某段时间被明确使用,它的“活跃期”就会和同时期活跃的普通临时变量产生冲突,从而产生连线。
4. 核心算法技巧:“无限度数” (∞)
这是整段文字最精妙的工程实现技巧。为了不破坏我们之前学过的 Build →→ Simplify →→ Coalesce →→ Spill 算法流程,编译器对预着色节点做了特殊处理:
不能简化(Cannot Simplify):简化的本质是“把它从图中摘除,等最后再给它随便挑个颜色”。但预着色节点的颜色是硬件焊死的,没有任何选择的自由,所以绝对不能被剥离入栈。
不能溢出(Cannot Spill):溢出的本质是“把变量赶出寄存器,存进内存”。但预着色节点本身就是物理寄存器,你无法把一段硬件实体溢出到内存里。
优雅的解法:为了让算法自动绕过它们,编译器直接在数学层面赋予了预着色节点无限大(∞)的度数(邻居数量)。
因为 ∞>K,所以
Simplify阶段永远不会挑中它。编译器也会特殊标记它们,避免在
Spill阶段把它们当作溢出候选人。最终,它们就像图中的基石一样,自始至终稳稳地待在图中,迫使其他普通节点围绕着它们来寻找空闲的颜色。
现代编译器中广泛使用的工程技巧:为机器寄存器创建临时副本(Temporary Copies of Machine Registers)
1. 痛点:被“霸占”的物理寄存器
长生命周期的灾难:像被调用者保存寄存器(Callee-save register,如图中的 r7),按照规则,函数必须在运行前后保持它的值不变。如果在逻辑上认为 r7 从函数入口(
enter)一直存活到函数出口(exit),那它的生命周期就太长了(如 Figure 11.7 左侧所示)。不可调和的冲突:因为预着色节点不能溢出,如果 r7 贯穿整个函数,它就会与函数内部产生的所有普通临时变量发生冲突(产生连线)。这会极大地增加图着色时的“寄存器压力(Register Pressure)”,导致大量无辜的普通变量被迫溢出到内存,严重拖慢程序速度。
2. 破局技巧:狸猫换太子
既然物理寄存器惹不起,那编译器就采用一种“金蝉脱壳”的策略(如 Figure 11.7 右侧所示):
立刻转移:在函数刚进门的地方,编译器立刻生成一条
MOVE指令(231←r7),把 r7 的值塞给一个全新的、极其普通的临时变量 t231用完还回去:在函数即将结束时,再用一条
MOVE指令(r7←t231)把它还给 r7好处一:瞬间解放物理寄存器 好处二:将“不可溢出”转化为“可溢出”
图着色寄存器分配算法中最为精妙的“涌现(Emergent)”行为之一:它是如何自动且完美地处理调用者保存(Caller-save)和被调用者保存(Callee-save)寄存器的分配问题的
1. 寄存器分配的“黄金法则”
不跨越函数调用的变量(短命变量):应该被分配到 Caller-save 寄存器。
原因:因为它在
CALL之前就用完了,或者CALL之后才诞生,所以根本不需要耗费性能去进行保存和恢复操作。
跨越多次函数调用的变量(长命变量):应该被分配到 Callee-save 寄存器。
原因:如果你把它放在 Caller-save 里,每次遇到
CALL你都要保存/恢复一次,开销极大。放在 Callee-save 里,整个当前函数只要在最开头和最结尾保存/恢复一次即可。
2. 图着色算法的自动魔法
令人惊叹的是,编译器不需要写死任何复杂的 if-else 逻辑来执行上述法则。它只需要在构建“冲突图”时做一点小手脚,图着色算法就会自动得出最优解:
人为制造冲突:编译器会在每一条 CALL 指令所在的位置,人为地让所有的 Caller-save 寄存器都被“定义(define)”一次。
结果:这意味着,如果有一个变量跨越了这条
CALL指令(即在CALL前后都活跃),它就会在同一时刻与所有的 Caller-save 寄存器发生“冲突”(产生连线)。自动避开:因为产生了冲突连线,图着色算法自然就不可能把这个跨越函数的变量分配给 Caller-save 寄存器了。
3. “终极献祭”:为什么被溢出的是 t231?
这段文字的最后一段,完美呼应了上一张图片中“为物理寄存器创建临时副本 t231”的奇妙操作。
假设变量 x 跨越了函数调用,它现在面临巨大的寄存器压力:
它因为
CALL指令,和所有的 Caller-save 寄存器冲突。它还和那个贯穿整个函数的临时副本 t231 冲突(t231 霸占着 Callee-save 寄存器 r7 的名额)。
图里实在塞不下了,必须有一个节点被溢出(Spill)到内存。选谁呢?
溢出的启发式评估(Spill Heuristic):编译器在选择溢出节点时,会挑选“度数高(挡了很多人的路)且使用频率低”的节点。
变量 x 可能在循环里被疯狂使用,使用频率极高。
而临时副本t231 虽然贯穿全局(度数极高),但它只在函数开头和结尾被使用了两次(使用频率极低)。
完美结局:算法果断判定 t231 溢出!随着 t231 退出竞争,原本被它占用的物理 Callee-save 寄存器 r7 瞬间空闲出来。算法顺理成章地把 r7 分配给了急需它的变量 x。
eg.

历年题
去年回忆卷小题.pdf 1

如果不能 simplify,也不能 coalesce,不一定马上 spill。还可能先 freeze 某些 move-related node,把相关 move 放弃合并,然后再继续 simplify。
daily
所以合并的时机是什么? 是 当所有 当前可行的simplify 都结束后才能合并还是 一旦可以合并就立马 合并?
为了极大化“合并成功率” 必须是当所有当前可行的简化(Simplify)都彻底结束后,才能进行合并(Coalesce)。
在标准 Iterated Register Coalescing(迭代寄存器合并)算法中,各个阶段有着极其严格的执行优先级: Simplify(最高) > Coalesce > Freeze > Spill(最低)
合并的基本前提

T1

为什么 这里调用f的时候, uses r1, define r1, r2?
uses r1 代表向子函数传递参数
defines r1 观察代码最末尾:
L2: r1 <- u,紧接着return (uses r1, r3)。这说明函数f在执行完毕准备回家时,会把最终的计算结果放在 r1 里带回来。defines r2 编译器在遇到任何
CALL指令时,都必须极度悲观地假设,那个被调用的瞎搞函数会把所有的 Caller-save 寄存器都弄脏. 尽管在这段特定的f函数代码中我们没有看到它修改 r2,但编译器在遇到call f时,依然会强行标记它定义(破坏)了 r2
George raw 中,合并节点有方向性吗?也就是说 ,假设 a 的 inference节点 是 b 的 inference子集 , 和 b 的 inference节点 是 a 的 inference子集 这两个条件,是满足任何一个就可以 合并吗?
是的,对于两个普通的临时变量节点,只要满足这两个子集条件中的任何一个,就绝对可以安全合并。
普通节点:实质上的双向性
普通变量与物理寄存器(预着色节点)的合并 问题
物理寄存器的恐怖属性:还记得前面提到的吗?物理寄存器(如 r1, r2, r3)的度数被设定为无穷大,并且它们彼此之间全连接。
反向检查会死机:如果我们把 r1 当作节点 a 去检查它的邻居,试图应用 George 规则——这是灾难性的。因为 r1 的邻居包含了整个系统里所有的其他物理寄存器,它们绝不可能是低度数,也不可能恰好都和变量 t 冲突。因此,反向检查永远会失败。
正确的单向检查:我们只能把普通变量 t 当作节点 a,去检查 t 的邻居。我们问:t 的这几个屈指可数的邻居,是不是要么已经是 r1 的邻居,要么是低度数节点?如果符合,我们就把 t 放心地“融入”到 r1 庞大的身躯中。
步骤中 有 “把栈里的节点一个个弹出来分配颜色”,在建立这个栈的时候, 这个栈 是 既接受 simplify 的节点 又接受 spill的节点的吗?
是的
Briggs debug
Garbage Collection
https://gemini.google.com/app/a0abdca4dbb14bae?hl=zh
复习
标记-清除算法
1. 理论核心:将内存抽象为“有向图”(对应图 1 内容)
图 1(13.1 节)给出了垃圾回收的核心理论模型:
有向图(Directed Graph):在运行时的程序中,程序变量(Program variables)和在堆中分配的记录(Heap-allocated records,即对象/数据)共同构成了一个有向图。变量或记录是图的“节点”,它们之间的指针/引用关系就是图的“有向边”。
根节点(Roots):当前在作用域内、可以直接访问的程序变量就是这个图的“根”。
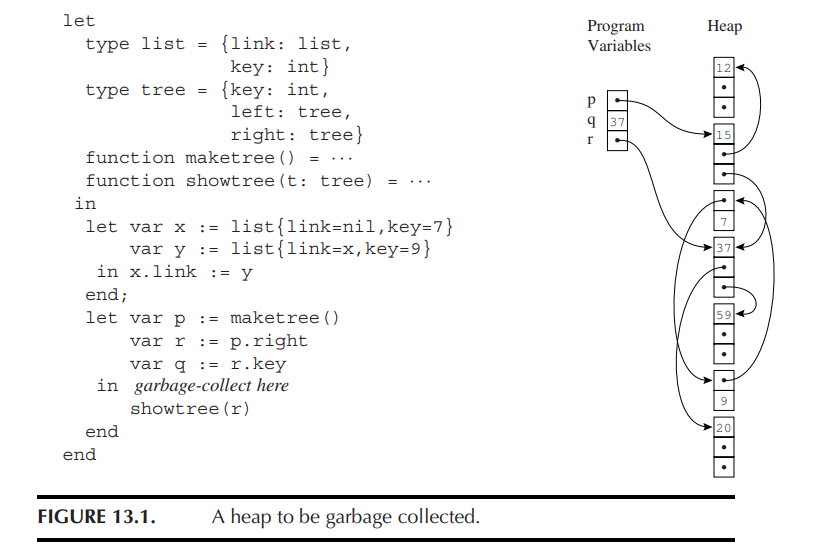
可达性(Reachable):如果从某一个根节点出发,顺着指针的箭头(有向边)能够一路走到某个节点 n,那么节点 n 就是“可达”的,也就是存活的、不能被回收的数据。
标记目标:我们需要一种图搜索算法(如图中提到的深度优先搜索 DFS),从根节点出发,把所有“可达”的节点都打上标记(Mark)。
2. 清除阶段的核心逻辑(对应图 1 内容)
在“标记”阶段结束后,所有还能被程序用到的数据(可达节点)都已经被打上了标记。剩下的工作就是清理:
线性扫描(Sweep):系统会从堆内存(Heap)的第一个地址开始,一直扫描到最后一个地址,检查每一个节点。
回收垃圾:任何没有被标记的节点,就绝对是“垃圾”。这些节点占用的空间必须被收回。
构建空闲链表(Freelist):收回的垃圾内存并不会直接消失,而是被串联成一个新的链表,称为空闲链表(Freelist)。这个链表专门用来存放当前可用的空闲内存块。
重置标记:对于那些有标记(存活下来)的节点,清除阶段会顺手把它们的标记“擦除”(unmark)。这是为了让所有存活节点恢复到干净的状态,为下一次垃圾回收做准备。
3. 程序的恢复与下一次 GC 触发(对应图 1 下半部分)
内存分配:垃圾回收完成后,暂停的程序恢复执行。当程序以后需要分配新对象(new record)时,系统就会直接从
freelist中取出一块空闲内存给它用。触发时机:当程序不断索要内存,导致
freelist再次被掏空时,这就是触发下一次垃圾回收的最佳时机。系统会再次暂停程序,重新走一遍“标记-清除”的流程来补充freelist。
评估和优化垃圾回收(GC)的性能成本
1. 单次垃圾回收的“绝对时间成本”
标记-清除(Mark-and-Sweep)算法的总时间消耗分为两部分:
标记阶段 (Mark):其花费的时间与存活(可达)数据量成正比。假设堆中存活的数据量为 R(Reachable data),每处理一个存活单位需要 c1 条指令,那么时间成本就是 c1×R。
清除阶段 (Sweep):其花费的时间与整个堆的大小成正比(因为它必须从头到尾扫一遍)。假设堆总大小为 H(Heap size),每扫过一个单位需要 c2 条指令,那么时间成本就是 c2×H。
单次回收总成本 = c1R+c2H
(书中给出的经验值为:c1 约等于 10 条指令,c2 约等于 3 条指令)
2. 更关键的指标:“均摊成本”(Amortized Cost)
衡量 GC 好坏,不能只看它跑一次花了多长时间,而是要看它为你腾出了多少可用空间。
一次 GC 腾出的空闲空间(freelist 容量)= H−R (总空间减去存活的数据空间)。
均摊成本 = (花掉的总时间) ÷ (腾出的可用空间) = (c1R+c2H)/(H−R)
这个公式算出来的结果代表:程序每分配一个字(Word)的新内存,背后到底要替垃圾回收承担多少条指令的性能开销。
3. 两种极端的运行状况
这个公式揭示了内存管理中非常核心的现象:
最坏情况(R 接近 H):堆几乎塞满了存活数据。此时分母 (H−R) 变得极小,导致均摊成本爆炸式上升。系统花了巨大力气扫描整个堆,结果只腾出一点点空间,刚分配没几下就又得进行 GC(俗称“GC 抖动”)。
理想情况(H 远大于 R):堆非常大,存活数据很少。公式中的c1R 可以忽略,分母近似于 H。均摊成本近似为 c2。也就是说,每个分配字的 GC 成本仅为大约 3 条指令,非常高效。
4. 垃圾回收器的自适应策略(动态调整)
为了避免“最坏情况”,垃圾回收器会监控 H 和空闲空间 (H−R)。
如果发现存活数据占比太高(例如 R/H>0.5),回收器就会主动向操作系统申请更多内存来扩大堆(H)。
递归算法的致命缺陷
文字部分揭示了之前讨论的 Algorithm 13.2(递归执行的 DFS)在现实工程中极其危险的一面:
最坏情况下的深度爆炸:DFS 是一个递归算法。如果堆内存中的存活数据恰好形成了一条极长的单向链表,那么 DFS 的递归深度(Recursion depth)将等同于这条链表的长度。在最坏的情况下,这个长度就是整个堆的大小 H。
栈溢出灾难:每一次函数递归调用,系统都会在内存的“调用栈(Call Stack)”中压入一个活动记录(Activation record / 栈帧)。栈帧里包含返回地址、局部变量等,体积远大于普通数据。如果递归深度达到 H,意味着调用栈的大小可能会比你要回收的堆内存还要大得多! 这极易导致系统崩溃(Stack Overflow)。
初步的改进方案:使用显式栈(Explicit Stack)
为了解决递归导致调用栈爆炸的问题,书中提出了第一步改进方案:
替换机制:放弃使用系统底层的函数递归,改为在代码中自己维护一个“显式栈”(Explicit stack)数据结构。
带来的好处:自己维护的栈里,只需要存放目标节点的内存地址(Words),而不需要存放臃肿的系统栈帧。这样一来,即使最坏情况发生,也只是占用 H 个字(Words)的额外空间,而不是 H 个庞大的活动记录。
仍然存在的问题(引出下文):即便如此,作者在最后一句指出:“为了收集堆内存,而要求提供一个和堆一样大的辅助栈内存,仍然是不可接受的。” (Still, it is unacceptable to require auxiliary stack memory as large as the heap being collected.)因为垃圾回收器本身就是在内存紧缺时才运行的,它不能再奢求大量的额外内存来完成工作。
指针反转 (Pointer Reversal)
核心工作原理
当我们从对象 x 顺着它的指针 x.fi 向下走到下一个对象时,系统会把 x.fi 的值(也就是下一个对象的地址)压入所谓的“栈”中。发现盲点:一旦我们顺着指针走下去了,在回溯(退栈)之前,当前算法绝对不会再去查看 x.fi 这个内存槽位了。这个槽位暂时处于“闲置”状态。
鸠占鹊巢:既然它闲着,我们就直接把这个内存槽位(x.fi)当成栈的一部分!我们把 x.fi 里的内容修改掉,让它反向指向刚才走过来的“父节点”。
留下沿途的面包屑:随着 DFS 不断深入,我们一路走,一路把路过的指针“反转”过来指向上一步。这就像在迷宫里留下了一条反向指引回家的线。
完美回溯:当我们遍历完底层节点需要退回时(pop),我们就顺着这些“反转指针”一步步往回走。每退回一步,就把那个指针恢复成它原本正确的值。
通过这种方式,原本需要额外分配空间的“栈”,被巧妙地打散并隐藏在了正在遍历的图结构本身的指针里面。
唯一的微小代价:done 字段
图片末尾提到,为了配合这种指针反转机制,需要在每个记录(对象)中增加一个极小的字段,叫作
done。为什么需要
done? 因为一个对象可能有好几个指针(比如一棵树有left和right两个分支)。当你顺着反转指针回溯到一个节点时,系统需要知道:“我刚才到底是在遍历它的第几个分支?”done字段就用来记录当前已经处理完了该对象的几个字段。它只需要占用非常少的几个比特位(bits),甚至可以和之前的“标记位(mark field)”挤在同一个字节里,对内存空间的额外占用微乎其微。
空闲链表数组(Array of freelists)
1. 痛点:单一链表的低效(文字第一段)
在基本的清除阶段,系统只是简单地把所有未标记的“垃圾”串联成一条单向的“空闲链表(freelist)”。
问题所在:如果程序中各个对象的大小不一样,这条链表里就会混杂着各种尺寸的内存块(比如大小为 2、大小为 8、大小为 3 的块随机排列)。
性能瓶颈:当程序请求分配一块大小为 n 的新内存时,分配器可能需要顺着这条长链表向后遍历很久,才能找到一块空间足够大的内存。这种线性的查找过程是非常消耗时间的。
2. 解决方案:分门别类(文字第二段)
为了消除这种查找时间的浪费,书中提出了使用数组来管理空闲链表:
核心结构:创建一个数组,名为
freelist。它的巧妙之处在于:数组的索引 i 代表了内存块的大小。即freelist[i]这个槽位里,专门存放所有大小正好为 i 的空闲内存块链表。分配极快:当程序需要大小为 i 的对象时,直接去 freelist[i] 的头部取下第一个块即可(时间复杂度骤降为 O(1),无需任何遍历)。
回收也快:在清除阶段,垃圾回收器发现了一个大小为 j 的垃圾块,就直接把它挂到 freelist[j] 的链表头部。
3. 进阶策略:大块拆分与“找零”(文字第三段)
这是一种应对内存碎片化的聪明机制。如果程序想分配大小为 i 的内存,但很不巧 freelist[i] 已经被掏空了怎么办?
向大块借用(Split):系统不会立刻放弃,而是去寻找尺寸更大的链表
freelist[j](其中j>i)。切分与找零:如果找到了大块,就把它一分为二。切下大小为 i 的部分拿去分配,剩下的部分就像买东西“找零”一样,大小为 j−i。
物归原位:把这块“找零”的内存,放进它该去的槽位,即
freelist[j - i]中。终极手段:如果连更大的内存块都被借空了,实在无处可借,这时候才会真正触发一次全新的垃圾回收,来重新补充整个空闲链表数组的库存。
引用计数(Reference Counting)
1. 核心思想:自带计数器 (Image 1)
第一段文字直接点出了引用计数的本质区别:
标记-清除的缺点:必须先暂停程序,去全局扫描找出一堆可达对象,剩下的才算是垃圾。
引用计数的直观做法:直接在每个数据记录(对象)里面,专门留出一小块空间存一个数字。这个数字记录了当前到底有多少个指针正在指向它。这就是引用计数(Reference count)。
生死判定:一旦这个数字变成
0,就意味着没有任何变量或对象关心它了,它立刻就被判定为垃圾。
2. 运行机制:增与减的连锁反应 (Image 2 上半部分)
为了维持这个计数器的准确性,编译器会在程序运行的代码中悄悄“加料”。
每当程序执行一次指针赋值操作(例如 x.fi = p),编译器会自动插入额外的指令来做两件事:
新欢加一:因为
p被赋值给了新的变量,所以p指向的对象的引用计数要 +1(incremented)。旧爱减一:在赋值之前,
x.fi原本是指向另一个对象(旧对象)的。现在它移情别恋了,所以旧对象的引用计数必须 -1(decremented)。
连锁反应(级联删除): 如果那个旧对象被 -1 之后,计数刚好变成了 0(变成垃圾了),它就会被立刻扔进空闲链表(freelist)。 但这还没完:既然它已经“死”了,那么它内部包含的指针所指向的其他对象,也必须统统跟着 -1。如果这导致子对象的计数也变成 0,就会继续往下 -1,形成一场连环回收。
3. 工程优化:延迟递归递减 (Image 2 下半部分)
文字的后半段提出了一个极其重要的工程优化策略。
刚才提到的“连环回收”存在一个巨大的隐患:如果程序恰好丢弃了一个包含成千上万个节点的巨大树形结构,那么在丢弃根节点的一瞬间,系统会被迫停下来执行成千上万次的 -1 操作(递归递减)。这会导致程序出现明显的卡顿。
优化方案:惰性释放(Lazy Deletion) 书里建议,当对象 r 的计数变成 0 时,先别急着去扣减它子节点的计数。仅仅把它自己挂到 freelist(空闲链表)上就完事了。 等到未来某一天,程序需要分配新内存,从 freelist 里把 r 重新拿出来准备覆盖使用的时候,再去把 r 原来指向的那些子节点的计数 -1。
书里给出了这样做的两个关键理由:
化整为零(平滑运行):把原本集中爆发的“连环递减”操作,打散分摊到了后续的每一次内存分配中。这对于需要极高流畅度的交互式程序或实时程序(Interactive or real-time programs)至关重要,消除了可怕的随机卡顿。
精简编译代码:如果每次指针改变都要做连环递减,编译器就必须在代码的每一个角落都塞满复杂的循环递减检查。但如果采用“延迟策略”,编译器只需要在内存分配器(Allocator)这一个集中的地方写一段递减代码就可以了,大大减小了编译后程序的体积。
引用计数的缺陷
致命缺陷 1:无法处理“循环垃圾”(Cycles of Garbage)
这是引用计数在逻辑上最大的死穴。
现象:假设有两个对象 AA 和 BB。程序把它们俩连起来了:AA 指向 BB,BB 也指向 AA(或者像图 1 中提到的 7 和 9 组成的环)。
困境:后来,程序的作用域结束了,再也没有任何外部的根变量去访问 AA 或 BB 了。从全局来看,它们已经是彻头彻尾的“垃圾”了。
失败:但是!在引用计数的眼里,AA 的计数是 1(因为 BB 在指着它),BB 的计数也是 1(因为 AA 在指着它)。它们的计数永远不会掉到 0。这两个对象互相抱着对方,成为了内存中永远无法被回收的“幽灵岛”。
致命缺陷 2:性能开销极其昂贵(Very Expensive)
在底层硬件层面,频繁更新计数器的代价大得惊人。
原本极快的操作:在没有引用计数的语言里,一次简单的指针赋值(把 p 赋给 x.fi)在汇编层面可能只需要一条机器指令就能完成。
代码膨胀:如图 1 中间的伪代码所示,为了维护引用计数,原本那一条指令,现在被硬生生膨胀成了近 10 条指令
复制收集(Copying Collection)



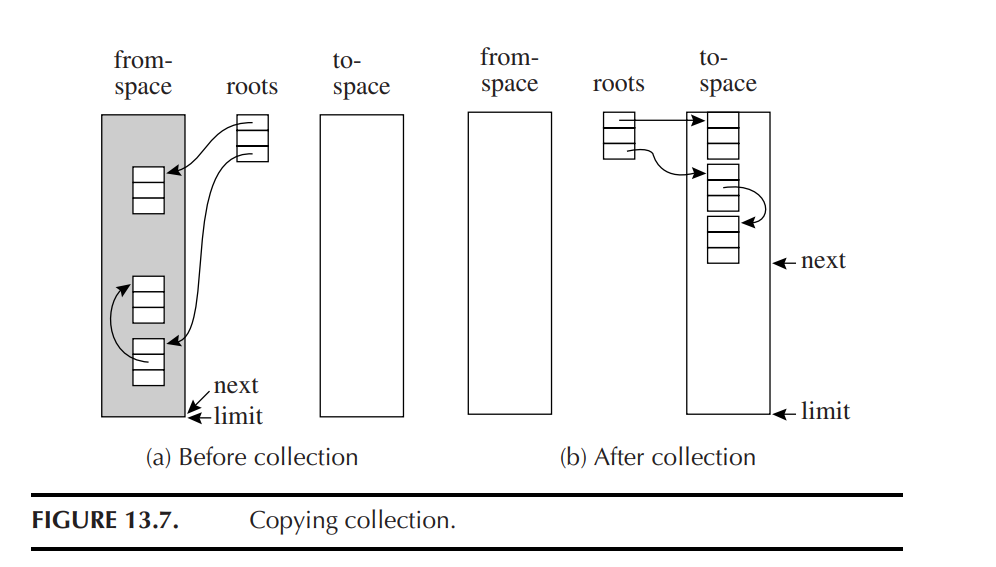
转发指针(Forwarding Pointers)
在复制收集算法中,我们面临一个巨大的逻辑难题:当你把一个对象从 from-space(旧区)搬到 to-space(新区)后,那些原本指着它的其他对象或变量该怎么办? 如果不通知它们,它们的指针就会变成指向一块废弃内存的“死链”。
这就好比你搬家了,你需要一种机制来让所有找你的人都能找到你的新地址。这就是 Forward(p) 算法的工作。
以下是对图片内容的详细拆解:
1. 初始准备 (Initiating a collection)
第一张图片简单说明了搬家前的准备工作: 系统会在干净的 to-space(新区)的开头设置一个 next 指针。每当从旧区找到一个存活对象,就把它复制到 next 指向的位置,然后把 next 往前挪动该对象的大小,为下一个搬来的对象腾出地方。
2. 核心操作:转发指针 (Forwarding)
第二和第三张图片详细解释了 Algorithm 13.8,即如何处理一个指向旧区的指针 p。
这个算法极其聪明地利用了“在老房子门上贴新地址条”的生活逻辑。它将遇到的指针分为三种情况(我按照逻辑发生的先后顺序为您解释):
情况 2:首次遇到该对象(真正执行搬家)
场景:程序顺着指针
p找到了旧区的一个存活对象,并且发现这个对象还没有被搬走。动作:
把它原封不动地复制到新区的 next 位置。
【核心黑科技】 破坏旧区里的那个原对象!把原对象的第一个字段(p.f1)(原本可能就是一个普通的变量,或者指针,在这里给他赋予了特殊意义,转发指针)强行覆盖写成它在新区的新地址。这个被修改的字段,就叫做转发指针(Forwarding pointer),也就是留在老房子门上的“新地址条”。
(图3解释了为什么可以放心破坏:因为这个对象的所有真实数据都已经安全复制到新区了,旧对象已经成了个空壳,随便改没关系。)
情况 1:再次遇到该对象(按图索骥去找新家)
场景:假设有两个变量
A和B都指向对象X。刚才处理A的时候,已经把X搬走了,并在旧X身上留下了新地址。现在,程序顺着指针B又找了过来。动作:程序一看旧
X的第一个字段p.f1,发现它居然指向to-space(正常情况下,旧区的对象是不可能指向新区的未分配区域的)。系统立刻明白:哦,这个对象已经被搬走了!于是,系统绝对不会再复制一遍该对象,而是直接读取
p.f1里的新地址,让B指向这个新地址即可。
情况 3:无需处理的数据
场景:如果
p根本不是个指针(比如只是个普通的整数),或者它已经指向了外部区域/新区。动作:什么都不做,直接返回。
切尼算法(Cheney's Algorithm)


“半深度优先(Semi-depth-first)”的混合算法


复制收集(Copying Collection)”算法的性能成本(Cost)

Chapter18 Loop Optimization
https://gemini.google.com/app/ef1e4f43148873ae?hl=zh
支配节点 (Dominators)


直接支配节点 (Immediate Dominators)
1. 核心定理:支配关系的“线性”特征
图片开篇提出了一个重要的定理:
在一个连通图中,假设节点 d 支配节点 n,并且节点 e 也支配节点 n。那么必然得出:要么 d 支配 e,要么 e 支配 d。
通俗解释: 如果有两个不同的节点(d 和 e)都能把守住通往节点 n 的必经之路,那么这两个节点绝对不会是“平行”或“并列”的关系。它们在控制流路径上必然是一前一后排成一条直线的。
3. 直接支配节点 idom(n) 的严格定义
基于上述定理(所有支配节点必定排成一条线),我们就可以在这条线上找到那个离节点 n 最近的支配节点。这个节点被称为 直接支配节点 (Immediate Dominator),记作 idom(n)。
它必须同时满足以下三个条件:
条件 1: idom(n) 不能是节点 n 本身。(排除了自我支配)
条件 2: idom(n) 必须是 n 的支配节点之一。
条件 3: idom(n) 不支配 n 的任何其他支配节点。
这一条是最关键的。因为所有支配节点排成一线,离 n 更远的节点会支配离 n 更近的节点。“不支配其他支配节点”意味着 idom(n) 是这条线上距离 n 最近、位次最低的那个守门员。
4. 最终结论与意义
图片最后一段得出了一个极其优雅的结论:
除了起始节点 s0 之外,图中的每一个节点都有且仅有一个直接支配节点。
支配树 (Dominator Tree) 和 回边 (Back Edge)
1. 支配树 (Dominator Tree) 的构建
第一段文字和图 18.3(b) 介绍了如何将支配关系可视化为一棵树。
如何画树: 我们把控制流图中的每一个节点都当作树的一个节点。对于任何一个节点 n,我们找到它的“直接支配节点” idom(n),然后画一条从 idom(n) 指向 n 的边。
为什么必定是树: 正如上一节所得出的结论,除了起始节点外,每个节点有且仅有一个直接支配节点。这种“一个子节点只有一个父节点”的严格一对一关系,自然而然地就构成了一棵树状结构。
3. 回边 (Back Edge) —— 锁定循环
图表下方的文字介绍了本章的终极目标:如何在图中准确地把循环找出来。这里给出了一个极其干脆的技术定义:
定义: 在原控制流图中,如果有一条从节点 n 指向节点 h 的边(即 n→h),并且 h 支配 n,那么这条边就被称为回边 (back edge)。
直观理解: h 支配 n,意味着你想要执行到代码 n,之前必然已经执行过代码 h 了。此时如果有一条边又把你从 n 送回了 h,这就形成了一个闭环——这就是循环 (Loop)。在这其中,节点 h 就是这个循环的头节点 (header)。
自然循环 (Natural Loop) 的定义
在找到了回边 n→h(其中 h 支配 n)之后,我们需要确定这个循环到底包含了图中的哪些节点。
教材给出了自然循环的严谨数学定义:它是由节点 x 组成的集合,这些节点必须同时满足两个条件:
被头节点支配: 节点 x 必须被头节点 h 支配。
存在内部通路: 从节点 x 必须存在一条能够到达回边起点 n 的路径,并且这条路径在途中绝对不能经过头节点 h。
满足这些条件的节点集合就构成了一个自然循环,其中节点 h 就是该循环的头节点 (header)。
循环预首节点 (Loop Preheader)
1. 为什么要引入“预首节点”?(图 18.5a 的困境)
很多循环优化技术需要把一些代码移动到紧挨着循环执行之前的位置。
经典场景:循环不变量外提 (Loop-invariant hoisting)。 如果循环里有一段代码(比如
x = a + b),每次循环算出来的结果都一样,编译器为了提升速度,就会把它“提”到循环外面,只算一次。面临的问题: 观察图 18.5(a),循环的头节点是 4。从循环外部进入头节点 4 有两条不同的路径(节点 2 和节点 3)。如果我们想把语句 s 提到循环外面,为了保证无论从哪条路进来 s 都会被执行,我们不得不把 s 复制两份,分别塞进节点 2 和节点 3 的末尾。如果外部入口有十几个,就要复制十几次,这显然非常低效且难以管理。
2. 什么是“预首节点”及构建规则
为了解决上述“找不到唯一安放点”的问题,编译器会在进入循环的关口,人为地创建一个新的、最初为空的节点,也就是预首节点 (preheader),通常记为 p。
它的构建和连线规则非常明确:
单线联系: 添加一条从预首节点 p 指向循环头节点 h 的边(即 p→h)。
外部入口统管: 将所有从循环外部指向头节点的边(比如原先的 y→h),全部拔掉,重新连到预首节点上(变成 y→p)。
内部回边照旧: 所有从循环内部指向头节点的边(即构成循环的回边 x→h),保持原样,完全不动。
循环不变量计算 (Loop-Invariant Computations)


代码外提 (Hoisting)

1. 盲目“外提”的四大陷阱(结合图 18.6)
图 18.6 给出了四种不同的代码结构,展示了外提操作何时安全,何时会导致灾难:
(a) 可以外提 (Hoist): 这是一个标准的
do-while结构。无论如何循环体至少会执行一次。把 t←a⊕b 提到循环外面是绝对安全的,能让程序跑得更快且结果正确。(b) 坚决不能提 (Don’t) - 可能根本不执行: 这是一个带有前置条件判断的循环。如果初始状态下 i≥N,程序本应该直接跳出循环(跳到 L2),根本不执行 t 的计算,最后 x 会得到 t 的旧值(即 0)。但如果你把 t←a⊕b 提到了最外面,程序就会强制算出这个新值并最终赋给 x,导致输出结果错误。
(c) 坚决不能提 (Don’t) - 存在多重定义: 循环体里,在 t←a⊕b 之后,又执行了 t←0。如果把不变量提到外面,循环体内对 t 的赋值顺序就会被打乱,导致最后存入数组 M 的数据发生严重错误。
(d) 坚决不能提 (Don’t) - 定义前就使用了旧值: 在这个循环里,第一句是 M[j]←t,此时它期望使用的是进入循环前 t 的旧值(即 0)。如果把 t←a⊕b 提到了循环外面,第一轮迭代时M[j] 就会错误地使用外提计算出的新值。
2. 安全外提的三大严格标准
为了避开上述陷阱,教材给出了将赋值语句 d:t←a⊕b 安全外提到“预首节点”的三个必须同时满足的严格条件:
节点 d 必须支配所有变量 t 是“活跃 (live-out)”的循环出口: * 解释: 如果跳出循环后,后面的代码还需要用到变量 t(即 t 是活跃的),那么我们必须保证,只要程序走到这个出口,它在循环里就必然已经经过了节点 d。这直接规避了图 18.6(b) 的陷阱,防止提出来一个原本可能根本不会被执行的语句。(防止节点d在一个条件语句的段中,就不一定会执行)
循环中只有这一处对 t 的定义(赋值):
解释: 保证没有其他代码在循环里覆盖 t 的值。这直接规避了图 18.6© 的陷阱。
变量 t 在预首节点的出口处不是“活跃”的:
解释: 这意味着在进入循环的第一轮,在执行到语句 d 之前,程序不需要用到进入循环前 t 的旧值。这直接规避了图 18.6(d) 的陷阱。
(注:文本还提到了一个“隐式副作用”的问题,比如如果a⊕b 可能会导致除以零的报错,把它无条件外提可能会让原本不会崩溃的程序提前崩溃,这需要额外的特殊处理。)
3. while 循环的“硬伤”与编译器的巧妙转换
文章最后一段指出了一个常见问题:我们日常写的 while 循环,通常无法满足上面的条件 (1)。
为什么? 因为
while循环在最开头(头节点)进行条件判断,如果条件不成立,直接就从头节点出去了。这意味着循环体内部的代码(比如节点 d)不支配这个出口。因此,while循环里的很多计算都无法被安全外提。如何破解? 编译器会玩一个花招,把
while循环转换成if (...) { repeat ... until }的结构(如图 18.7b 所示)。通过在外面包一层if,将真正的循环体变成了“至少执行一次”的repeat结构。在repeat循环中,循环体内部的节点就能成功支配出口了,条件 (1) 得以满足,优化的大门也随之敞开。